【NeurIPS2022】SparCL:边缘稀疏持续学习

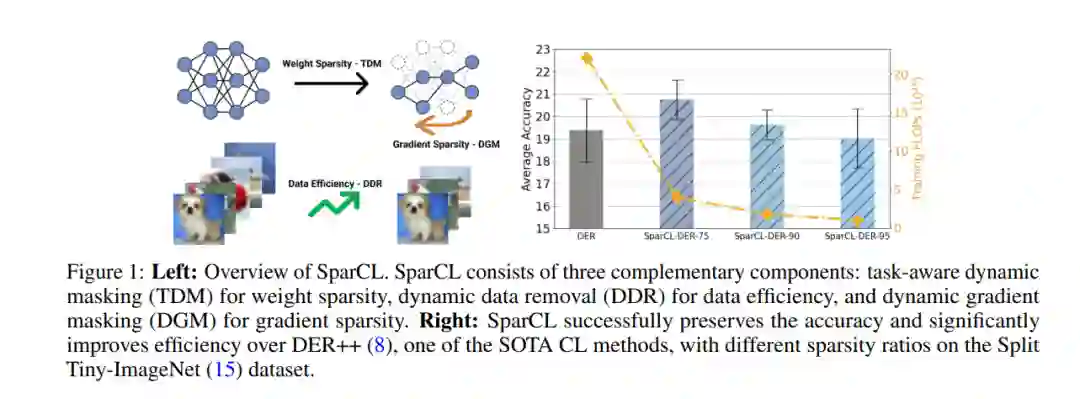
现有的持续学习(CL)研究集中在减轻灾难性遗忘上,即模拟在学习新任务时对过去任务的表现恶化。然而,对于CL系统的训练效率研究不足,这限制了CL系统在资源有限场景下的实际应用。在这项工作中,我们提出了一个名为稀疏持续学习(SparCL)的新框架,这是第一个利用稀疏性在边缘设备上实现低成本持续学习的研究。SparCL通过权值稀疏性、数据效率和梯度稀疏性三个方面的协同作用实现了训练加速和准确性保持。提出任务感知动态掩码(TDM)在整个CL过程中学习一个稀疏的网络,动态数据移除(DDR)来删除信息量较少的训练数据,以及动态梯度掩码(DGM)来稀疏梯度更新。这些方法不仅提高了效率,还进一步减轻了灾难性的遗忘。SparCL通过最多23×少的FLOP训练,持续提高现有的最先进的(SOTA) CL方法的训练效率,并且令人惊讶的是,进一步提高SOTA精度最多1.7%。SparCL在效率和准确性方面也优于通过将SOTA稀疏训练方法应用于CL设置而获得的竞争基线。我们还在真实的手机上评估了SparCL的有效性,进一步表明了我们的方法的实用潜力。源代码将被发布。
https://arxiv.org/pdf/2209.09476.pdf
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“C424” 就可以获取《【MIT博士论文】非参数因果推理的算法方法,424页pdf》专知下载链接



登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文