Transformer落地:使用话语重写器改进多轮人机对话

作者丨袁一鸣
学校丨武汉大学硕士生
研究方向丨对话系统、目标检测
概述
https://github.com/chin-gyou/dialogue-utterance-rewriter


研究背景及主要工作


本文将话语重写问题建模为使用指针网络的提取生成问题。重写的话语是基于 attention 机制,通过复制来自对话历史或当前话语来生成。这个灵感来自最近提出的 Transformer [1] 可以更好地捕捉句子内的词之间的依赖关系,本文修改了 Transformer 体系结构使其包含指针网络机制。在指代消解和信息补全方面,得到的模型优于递归神经网络 (RNN) 和原始的 Transformer 模型, F1 分数超过了 0.85。此外,本文整合了训练好的话语重写器到两个在线聊天机器人平台,发现它可以实现更准确的意图检测并提高了用户的参与度。
模型
问题描述
将每个训练样本表示为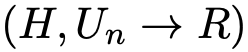
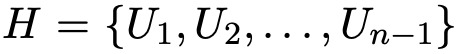
本文的目标是学习一个映射函数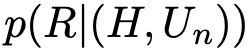
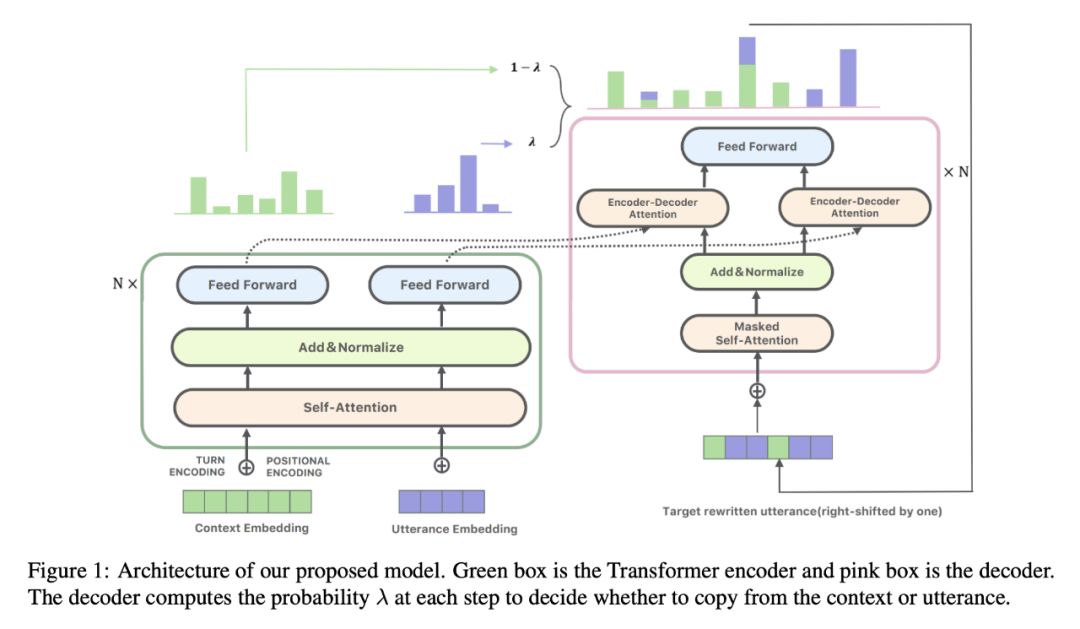
编码器
将 (H, Un) 中的所有 token 展开成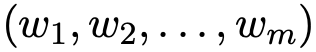
,其 input embedding 为其 word embedding, position embedding 和 turn embedding [2] 之和:
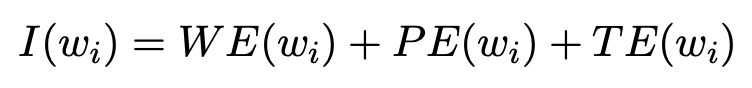
额外添加的 turn embedding ,用来指明每个 token 属于哪一轮对话。来自同一轮对话的 token 将共享相同 turn embedding。然后将 input embeddings 转发到堆叠的 L 层编码器,得到最终的编码表示。每个编码器包含一个 self-attention 层接着一个前馈神经网络。
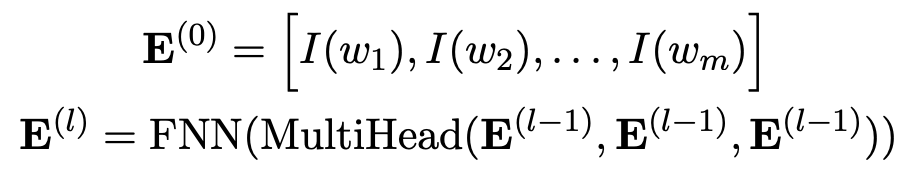
FNN 是前馈神经网络,MultiHead (Q, K, V) 是以查询矩阵 Q、键矩阵 K、值矩阵 V 为输入的 multi-head attention 函数。每个 self-attention 和 feedforward 组件都有一个残差连接和层归一化步骤,具体参考文献 [1]。最终的编码是第 L 个编码器的输出。
解码器
解码器也包含 L 层,每层由三个子层组成。第一子层是一个 multi-head attention:
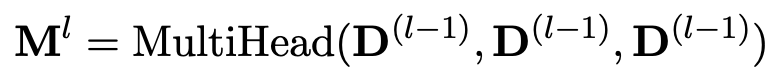
。第二个子层是编码器-解码器 attention,它将
集成到解码器。在本文的任务中,由于 H 和 Un 的用途不同,本文对于来自于对话历史 H 和来自当前话语 Un 的 tokens 分别使用单独的键-值矩阵。从上一节得到的编码序列
被分为
(H 中的令牌编码)和
(Un 中的令牌编码)然后分别处理。编码器-解码器向量计算如下:
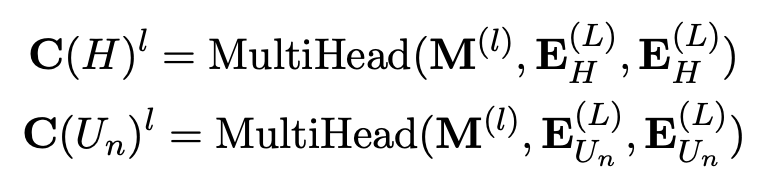
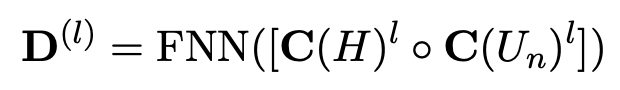
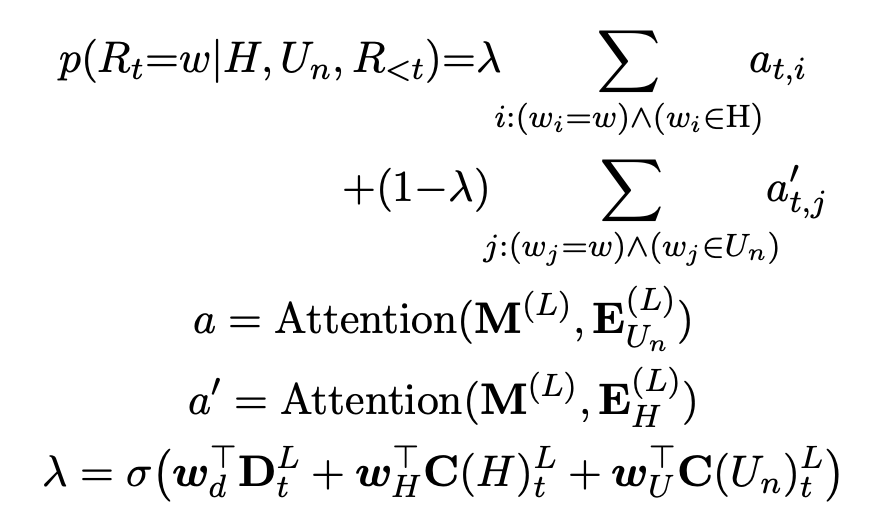
a 和 a'分别为 H 和 Un 的 tokens 上的 attention 分布。、
和
是可学习的参数,σ 是 sigmoid 函数,输出值在 0 和 1 之间。控制权重 λ 指示解码器从中对话历史 H 中提取信息或直接从 Un 复制。如果 Un 既不包含共指关系也不包含信息省略,λ 将总是 1 来复制原来的 Un 作为输出。否则检测到共指关系或信息省略时,λ 为 0。整个模型通过最大化
实验
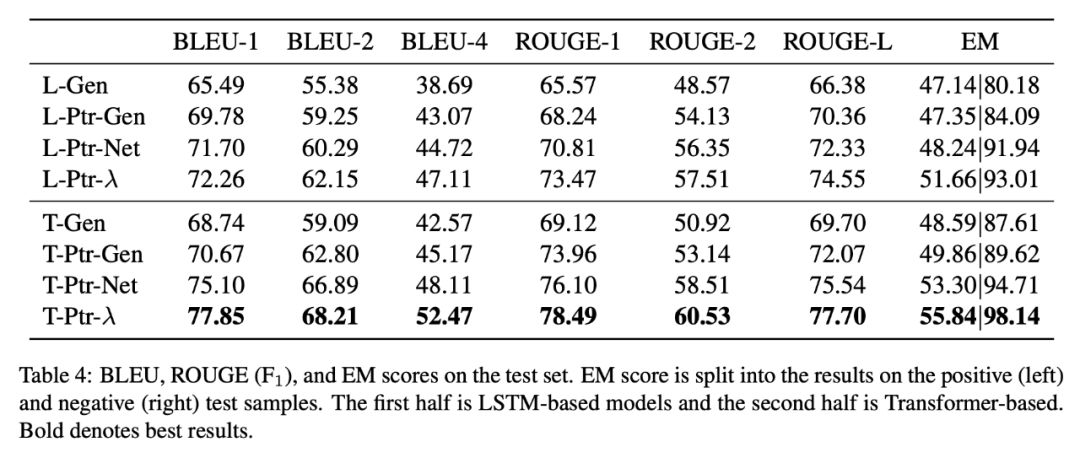
集成测试

总结
参考文献
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码