计算机视觉中的自监督表示学习近期进展


Representation Learning

▲ Representations: The input image (224 x 224 x 3) is passed through a feature extractor (typically a trained CNN network) that non-linearly transforms the spatial features of the image to a vector space of dimension 512.
计算机视觉中的表征学习是从原始数据中提取特征。特征提取涉及将原始数据处理到向量空间中,捕获表示该数据的基础时空信息。
在计算机视觉中,表征学习算法可分为两类:
监督学习(Supervised learning):利用大量的标注数据来训练神经网络模型,完成模型训练之后,不直接使用分类的 fc 层的输出,而是其前一层的输出作为 Representation 用于下游任务。
自监督学习(Self-Supervised Learning):利用大规模的无标注的数据,选择合适的辅助任务(pretext)和自身的监督信号,进行训练,从而可以学习到 Representation 用于下游任务。


Contrastive Learning
对比学习的核心思想是最大化相似性和最小化差异性的损失。先定义:
-
Query (q):待查询的图像 -
Positive sample (k₊):与 query 相似的样本 -
Negative sample (k₋):与 query 不相似的样本
Van den Oord et al.提出了一种称为 Noise Contrastive Estimation (InfoNCE) 得损失函数,如下:

这里的 q 是 encoded query 向量,而包含 encoded keys 的字典 k 记做 ,每一个 query 有一个对应的 Positive sample 和 k 个 Negative samples,因此,研究的就是 (K+1)-way 分类器问题,其目标是将 q 分类为 。
也就是说,如果 q 尽可能接近 ,同时又远离字典中其他 k 个负样本,那么损失值就会最小。
3.2 Contrastive Learning Architectures
3.2.1 End-to-End Backpropogation Based
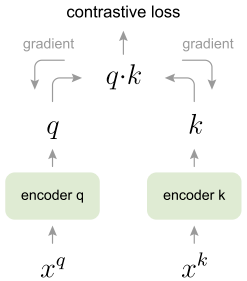
一个思路是使用基于端到端反向传播的方法,有两个编码器,一个生成查询向量 q,另一个计算字典键 k(从当前的训练 batch 中获取)。举个例子来说,每一个 batch 采样 10 张图片,则每一张图片都和这 10 张图片算一个 contrastive loss。
虽然这在实践中可行,但算法由于 GPU 内存有限,字典的容量基本上是非常有限的,因此,end-to-end 问题的核心在于 dictionary size 和 batch size 的耦合。


Related Papers
4.1 MoCo
先前的方法,有以下缺陷:
end2end 方法的 dictionary size 和 batch size 的耦合;
-
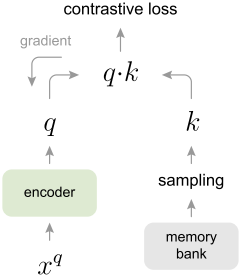
memory bank 方法会因为快速改变的 encoder,其键值表示特征的连续性较差;
因此,FAIR 提出了 MoCo,使得构建的字典具有大容量和一致性的特点。如下图所示,MoCo 将字典表示为数据采样的队列:
-
当前 mini-batch 的编码表示特征入队时,旧的 mini-batch 的编码表示特征出队; -
队列的大小和 mini-batch 的大小无关,因而字典可以有很大的容量;同时,字典的键值来自于先前的几个 mini-batches 的融合; -
momentum encoder 是基于动量的滑动平均值计算得到,保证了字典的持续性。
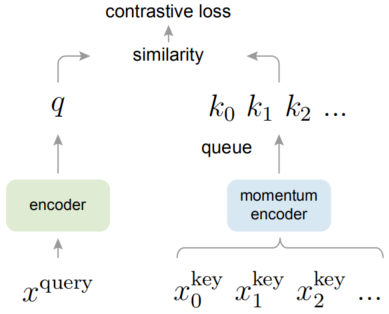
伪代码如下,每次迭代时,对相同的样本使用了不同的数据增强方法,将结果分别作为查询集和键值。每次梯度传播不向 key encoder 传播,而只更新 query encoder 的参数。key encoder 的参数采用逐步向 query encoder 逼近的方式。

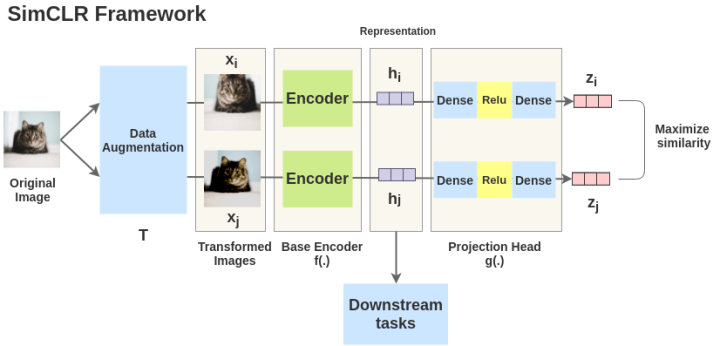
4.2 SimCLR
数据扩充的组合在有效的预测任务中起着关键作用;
在表征和对比损失之间引入可学习的非线性变换,大大提高了学习表示的质量;
与有监督的学习相比,对比学习需要更大 batch size 和训练轮数。
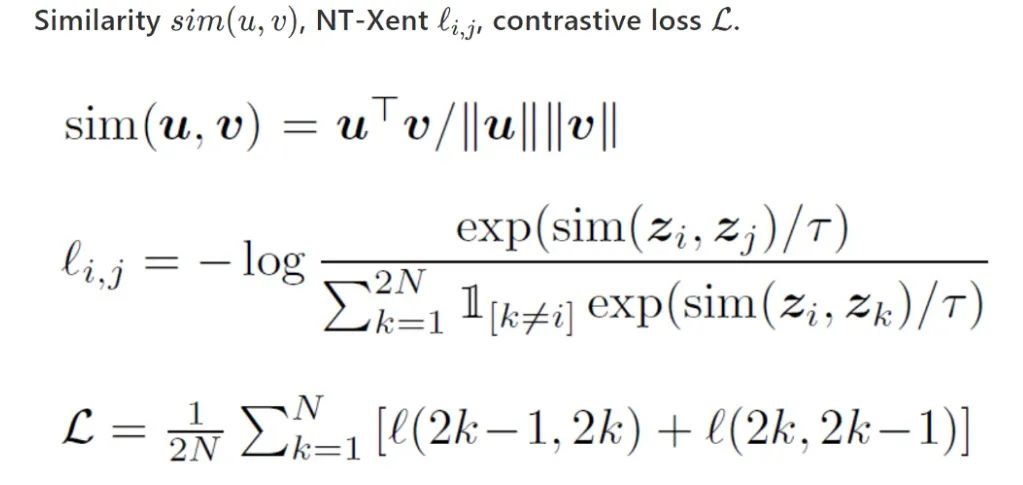


-
原始的 SimCLR 是采用end to end 的方式,负例 keys 都是来源于同一个 batch,并且通过反向传播来更新参数。假设 batch 里有 N 个样本,则计算 affinity 的复杂度为 N*N, 计算量较大,且比较依赖于大的 batch size。 -
而通过引入 MoCo 的框架,只需要把 query 送到 encoder 中去,而不需要很大的Batch。其中Momentum encoder用于计算 positive 和 negative 的 encoding,但是这个 encoder 是不用反向梯度来更新的,而是直接用左边的 encoder 来做一个 moving average。
实验的结果也非常好,在 ImageNet 任务提升了 6%。在我看来,Moco v2 是站在了 MoCo 和 SimCLR 基础上,还是很好理解的。
4.4 SimCLR v2
SimCLRv2 使用了一种独特的训练方法,包括使用的无监督预训练、半监督训练、有监督的微调和未标记数据的蒸馏,这超出了本文的范围,就不做详细介绍,不过 SimCLRv2 对工业界还是有很多用处的。
因为现实世界中有很多未标记的数据,手动标记每个样本以进行监督学习是一种非常低效的方法。而 SimCLRv2 利用未标记的数据来改进和传输特定于任务的知识,并取得了很好的结果,难道这不值得借鉴吗?
4.5 BYOL
终于到了 BYOL,这篇是我非常喜欢的一篇。BYOL 不仅仅是集大成所作,使用了 MPL、DataAugment 和 momentum constant 而已,更重要的是其提出了 CL 中关于负样本的新认识,并证明了无需负样本也能够取得好的效果。

-
上面的分支是 online network,参数为 。具体包括三个网络,encoder ,projector 以及 predictor 。最终训练好之后只需要将 保留下来作为训练好的特征提取器。 -
下面的分支是 target network,参数为 。网络比 online 少一个,只有 encoder 网络 和 projector 网络 。 网络更新:online 网络参数使用梯度进行更新,而 target 网络参数是通过 online 网络的滑动平均得到的。
-
损失函数:直接使用 L2 损失。


总结

参考文献
[1] Falcon, William, and Kyunghyun Cho. "A Framework For Contrastive Self-Supervised Learning And Designing A New Approach."arXiv preprint arXiv:2009.00104(2020).
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。



