学界 | 把酱油瓶放进菜篮子:UC Berkeley提出高度逼真的物体组合网络Compositional GAN
选自arXiv
机器之心编译
作者:Samaneh Azadi 等
参与:李诗萌、张倩
生成对抗网络(GAN)可以产生复杂且逼真到令人惊讶的图像,但它会忽略可能存在于场景中的多个实体间的显式空间交互。本文提出以 GAN 为框架、将目标组合建模为自洽的组合-分解网络。该模型以其边缘分布的目标图像为条件,通过明确学习可能的交互,在联合分布中产生逼真的图像。实验结果表明,训练后的模型可以在作为输入的两个给定的目标域间捕获潜在的交互关系,并以合理的方式在测试时输出组合场景的新的实例。
1. 引言
生成对抗网络(GAN)是在给定输入的条件下生成图像的一种强大方法。输入的格式可以是图像 [9,37,16,2,29,21]、文本短语 [33,24,23,11] 以及类标签布局 [19,20,1]。大多数 GAN 实例的目标是学习一种可以将源分布中的给定样例转换为输出分布中生成的样本的映射。这主要涉及到单个目标的转换(从苹果到橙子、从马到斑马或从标签到图像等),或改变输入图像的样式和纹理(从白天到夜晚等)。但是,这些直接的以输入为中心的转换无法直观体现这样一个事实:自然图像是 3D 视觉世界中交互的多个对象组成的 2D 投影。本文探索了组合在学习函数中所起到的作用,该函数将从边缘分布(如椅子和桌子)采集到的目标不同的图像样本映射到捕获其联合分布的组合样本(桌椅)中。
由于不同对象间在相对缩放、空间布局、遮挡以及视角变换等方面可能存在复杂的交互关系,在自然图像中对组合建模是一个极具挑战的问题。近期的研究在 GAN 框架 [15] 中使用空间变换网络 [10],通过在几何扭曲参数空间中进行操作,找到前景对象的几何纠正来分解该问题。但这种方法仅限于固定的背景,也并未考虑真实世界中更加复杂的交互关系。近期的另一项研究是以文本和场景图为条件生成场景的,这项研究明确地对对象和其交互关系进行了推理。
我们开发的这种方法可以对图像中的目标组合建模。我们将组合两个输入对象图像的任务视为生成一个联合图像,该图像可以捕获这两个对象在自然图像中的联合交互关系。例如,给定椅子和桌子的图像,可以产生一张包含相同的成对桌椅的自然交互的图像。一个可以正确捕捉组合特征的模型需要对遮挡排序(如桌子在椅子前面)和空间布局(如椅子在桌子内滑动)有所了解。据我们所知,我们是第一个在没有任何清晰的关于目标布局的先前显式信息的情况下,在图像条件空间中解决该问题的组。
我们的工作重点是将两个目标组合的问题重构为先组合好给定的目标图像以生成可以对目标交互关系建模的联合图像,再将联合图像分解,以获得单个目标。这样的重构可以通过组合-分解网络加强自洽约束 [37]。但在一些场景中无法用组合合成图像对相同的目标实例的成对样例进行访问,例如,要根据给定桌子和椅子的图像生成联合图像,除了指定的桌子外我们可能没有任何有关指定椅子的样例,但我们可能有其他桌子和椅子的图像。我们在组合分解层添加了修复网络,以处理这样的不配对情况。
通过定性和定量实验,我们在两个训练场景中评估了我们提出的 Compositional-GAN 方法:(a)配对:当我们有权用相关组合图像访问单个对象图像的成对样例时;(b)未配对:当数据集源于联合分布且没有与来自边缘分布的任何一张图进行配对时。
联合 GAN 代码和数据集请参阅:https://github.com/azadis/ CompositionalGAN
论文:Compositional GAN: Learning Conditional Image Composition

论文链接:https://arxiv.org/pdf/1807.07560v1.pdf
生成对抗网络(GAN)可以产生复杂且逼真到令人惊讶的图像,但它一般会从单个潜在源采样建模,从而忽略可能存在于场景中的多个实体间的显式空间交互。在相对缩放、空间布局、遮挡或视角转移等情况下在不同目标间捕获复杂的交互关系是极具挑战的问题。本文提出以 GAN 为框架、将目标组合建模为自洽的组合-分解网络。该模型以其边缘分布的目标图像为条件,通过明确学习可能的交互,在联合分布中产生逼真的图像。我们在对单独的目标进行配对和不配对的两个场景中通过定性实验和用户评估对模型进行了评估,在训练过程中也给出了联合场景。结果表明,训练后的模型可以在作为输入的两个给定的目标域间捕获潜在的交互关系,并以合理的方式在测试时输出组合场景的新的实例。
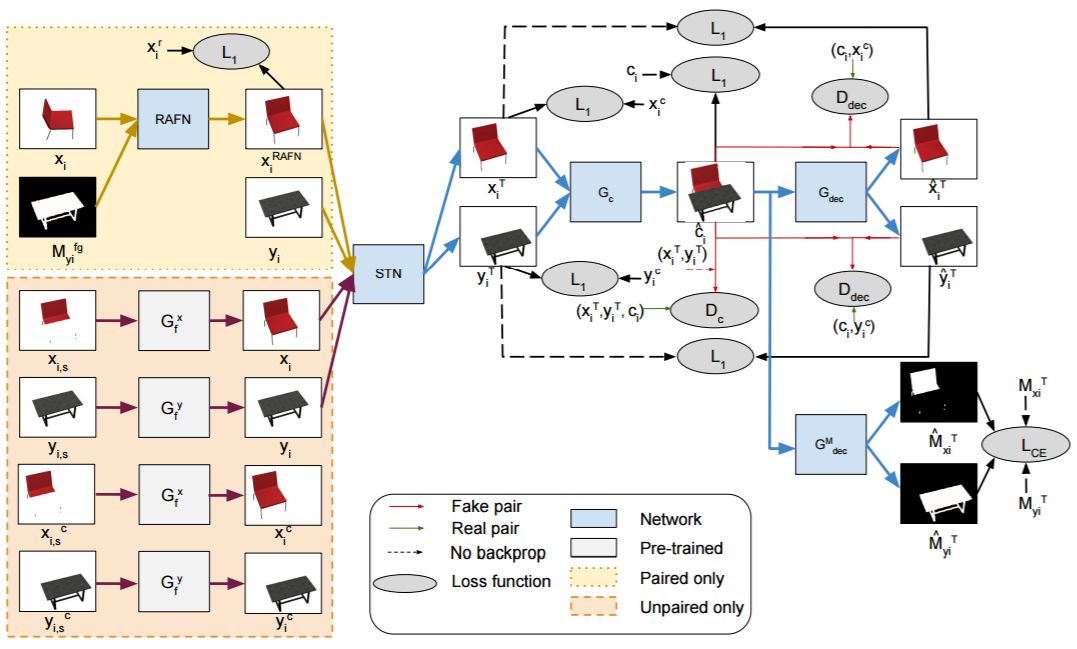
图 1:组合 GAN 对配对和未配对训练数据训练得到的模型。黄色框指的是用于在给定第二对象被遮挡的情况下合成第一对象的新视角的 RAFN 步骤,该过程仅用于成对数据的训练过程。橙色框表示用未配对数据修复输入分割的过程。对配对和未配对的情况而言模型的剩余部分相似,都包括 STN,再之后是自洽组合-分解网络。

图 2:使用配对或未配对数据训练桌椅组合任务的测试结果。「NN」代表成对训练集中最接近的图像,「NoInpaint」表示在没有修复网络的情况下未配对模型的结果。在配对和未配对情况中,cˆ before 和 cˆ after 分别表示在推理细化网络之前和之后的生成器的结果。cˆ after s 表示细化步骤后的有遮掩的转置输入的总和。
4 实验
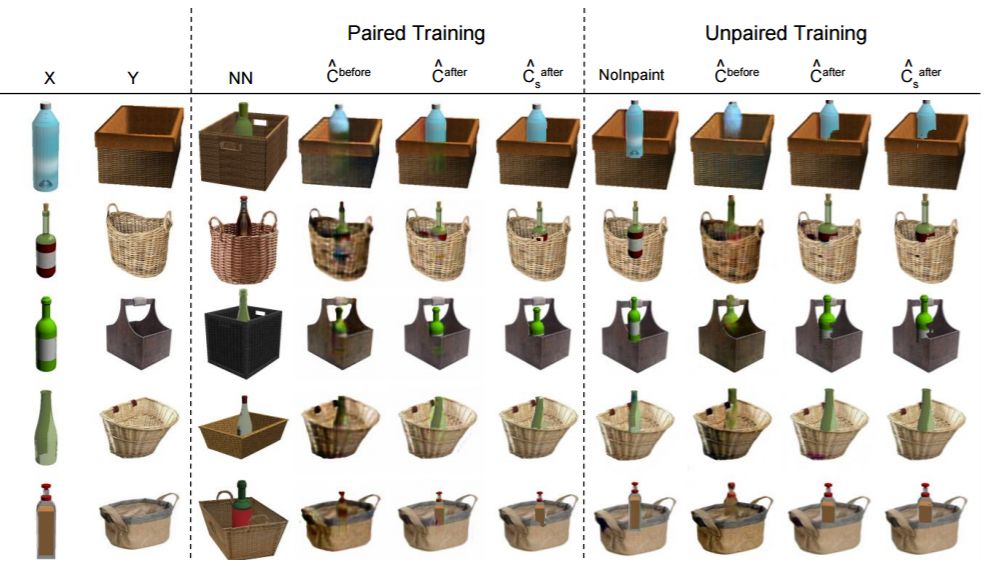
图 3:用配对或未配对数据对篮子-瓶子组合任务训练后的测试结果。「NN」表示在配对的训练集中最近的图像,「NoInpaint」表示在没有修复网络的情况下用未配对数据训练得到的模型。在配对和未配对情况中,cˆ before 和 cˆ after 分别表示在推理细化网络之前和之后生成器的输出结果。此外,cˆ after s 表示细化步骤之后遮掩情况下转置输入的总和。

表 1:AMT 用户评估比较我们提出的模型的不同组件。第一列表示在未配对场景中推理(未细化)期间要细化的图像的偏好百分比。第二列表示与未配对情况相比,通过配对数据训练策略生成的细化图像的偏好百分比。

图 4:面部-太阳镜组合任务的测试样例。前两行表示输入的太阳镜图像和面部图像,第三行和第四行分别表示用配对和未配对数据训练的组合 GAN 的输出。最后一行表示 ST-GAN 模型生成的图像。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


