学界 | 3D形状补全新突破:MIT提出结合对抗学习形状先验的ShapeHD
选自arXiv
作者:Jiajun Wu 等
机器之心编译
参与:乾树、张倩
单视图 3D 形状补全或重建具有挑战性。在给定单视图输入的情况下,ground truth 的形状是不确定的。现有的全监督方法无法解决这个问题。本文提出了 ShapeHD,通过将深度生成模型与对抗学习的形状先验相结合,超越单视图形状补全和重建的极限。实验证明,ShapeHD 在多个真实数据集的形状补全和形状重建方面都远远超过了当前最高水平。
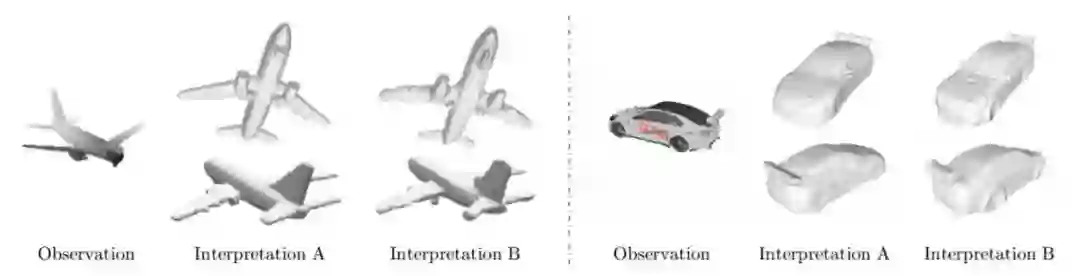
图 1. 研究者的模型使用单深度图像或 RGB 图像中的精细细节补全或重建对象的完整 3D 形状。
让我们从一个游戏开始:图 1 展示了一个深度图像或彩色图像以及两种不同的 3D 形状渲染图。哪一个看起来更好?
在这幅图中,研究者展示了两个例子,每个例子包括一个输入图像、两个 ground truth 的视图,以及两个结果图。研究者重建的形状高质且富含细节,并且在人类调研中的选择率分别是 41% 和 35%。研究者的模型在测试期间采用单个前馈传递且无需任何后处理,因此非常高效(<100 ms)、实用。
我们在亚马逊 Mechanical Turk 平台上向 100 人提出这个问题。59% 的人选择重建的飞机 A,35% 的人更喜欢重建的汽车 A。这些数字表明人们对这两种情况的偏好存在分歧,这些重建的质量接近,而且他们的感知差异相对较小。
实际上,对于每个实例,本文介绍的模型的输出是重建结果之一,另一个是 ground truth。
在本文中,研究者的目标是超越从单个深度图像到 3D 形状补全和从单个彩色图像到 3D 形状重建的极限。最近,研究者利用巨大的三维数据集 [5,60,59] 在这些任务上取得了令人印象深刻的进展 [7,52,8]。
这些方法中的许多方法通过使用深度卷积网络来生成可能的 3D 形状来应对问题的病态本质。利用深度生成模型的力量,他们的系统学会避免生成极不真实的形状(图 2b)。
然而,从图 2c 中我们意识到,受过监督训练的网络建模失败还存在歧义。对于单视图图像,存在多种自然形状,可以很好地解释看到的结果。换句话说,每个观察到的结果都没有确定的 ground truth。通过纯粹的监督学习,网络倾向于产生平均形状,这些形状由于歧义的存在而将惩罚最小化。
为了解决这个问题,研究者提出了 ShapeHD,通过将深度体积卷积网络与对抗网络学习的形状先验相结合来补全或重建 3D 形状。学到的形状先验只有在生成的形状脱离实际时才对模型进行惩罚,在偏离 ground truth 时不进行惩罚。
这解决了上面讨论的难题。研究者的模型通过对抗学习来描述这种自然性损失,该研究课题近年来受到了极大的关注,并且仍在迅猛发展 [14,37,57]。
在多个合成和真实数据集上的实验表明,ShapeHD 在单视图 3D 形状补全和重建方面表现良好,比最先进的系统表现更好。进一步分析表明,网络学会了了解有意义的对象的子部分,自然模块随着时间的推移确实有助于表征形状细节。

图 2. 单视图 3D 形状感知中的两个歧义等级。对于每个 2D 视图(a),存在许多可能的 3D 形状可以很好地解释这个视图(b,c),但只有一小部分符合真实的日常形状(c)。利用深度网络进行识别的方法在一定程度上减少了这一层面的歧义。
论文:Learning Shape Priors for Single-View 3D Completion and Reconstruction

论文链接:https://arxiv.org/pdf/1809.05068v1.pdf
摘要:单视图 3D 形状补全或重建具有挑战性,因为一个视图可能对应许多可能的形状,大多数情况不合情理且没有对应的自然对象。该领域的最新研究是通过利用深度卷积网络的表征能力来解决这个问题。事实上,还存在另一种常常被忽视的歧义:在合理的形状中,仍有多种形状可以很好地对应 2D 图像;即,在给定单视图输入的情况下,ground truth 的形状是不确定的。现有的全监督方法无法解决这个问题,而且通常会产生表面光滑但没有精细细节的模糊平均形状。在本文中,我们提出了 ShapeHD,通过将深度生成模型与对抗学习的形状先验相结合,超越单视图形状补全和重建的极限。学习到的先验知识作为一个正则化向,只有在它的输出脱离现实而非简单的偏离 ground truth 时才会对模型进行惩罚。因此,我们的设计解决了前面提到的两种歧义。实验证明,ShapeHD 在多个真实数据集的形状补全和形状重建方面都远远超过了现有最高水平。
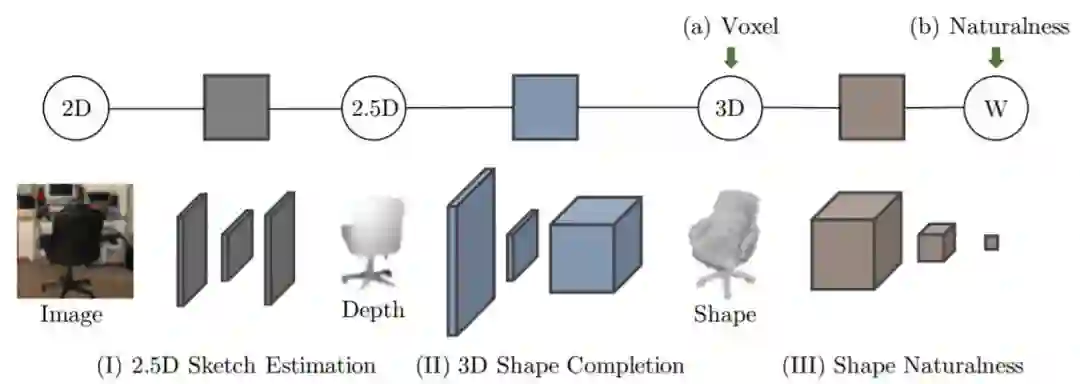
图 3. 对于单视图形状重建,ShapeHD 包含三个组件:(I)用于预测单个图像的深度、表面法线和轮廓图像的 2.5D 轮廓估计器;(II)3D 形状补全模块,该模块根据轮廓掩膜深度和表面法线图像补全 3D 形状;(III)用作自然损失函数的对抗预训练卷积网。在微调 3D 形状补全网络时,我们使用两种损失函数:输出形状的监督损失,以及预训练鉴别器提供的自然损失。
单视图形状补全

图 5. 3D 形状补全模型的结果,以及现有技术 3DEPN [8] 和研究者的没有自然损失的模型的对比。研究者发现对抗训练的自然损失有助于修复错误、添加细节(例如第 3 行中的机翼、第 6 行中的汽车座椅和第 8 行中的椅子把手)及抚平平面表面(例如第 7 行的沙发)。
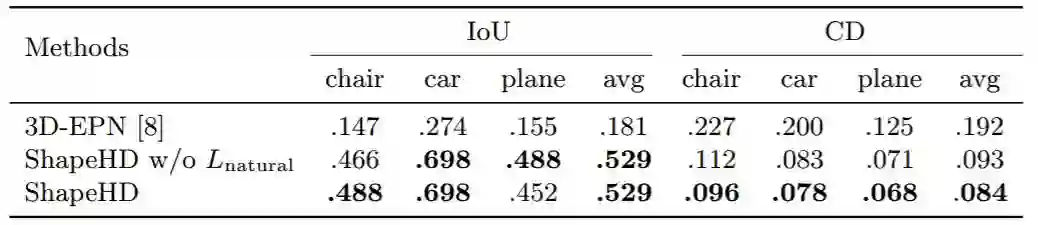
表 1. ShapeNet 上的 3D 形状补全的平均 IoU 分数(323)和 CD [5]。我们的模型远远超过了现有最高技术水平。可学习的自然损失不断改善本文的结果和 ground truth 之间的 CD。

图 6. 来自物理扫描仪的深度数据的 3D 形状补全的结果。研究者的模型能够从单视图中很好地重建形状。从左到右:输入的深度图片,补全结果的两个视图以及对象的彩色图像。
3D 形状重建

图 10. Pix3D 上的单视图 3D 重建 [45]。对于每个输入图像,研究者展示了通过 AtlasNet、DRC、ShapeHD 的重建效果图以及 ground truth。研究者的 ShapeHD 重建完整的 3D 形状,具有接近 ground truth 的精细细节。

图 11. ShapeHD 处理深度图中细节的可视化。第 1 行:车轮探测器。第 2 行:椅背和椅子腿探测器。左边对应于跨步模式。第 3 行:椅子臂和椅子腿探测器。第 4 行:飞机发动机和曲面探测器。右侧对应跨类别的特定模式。
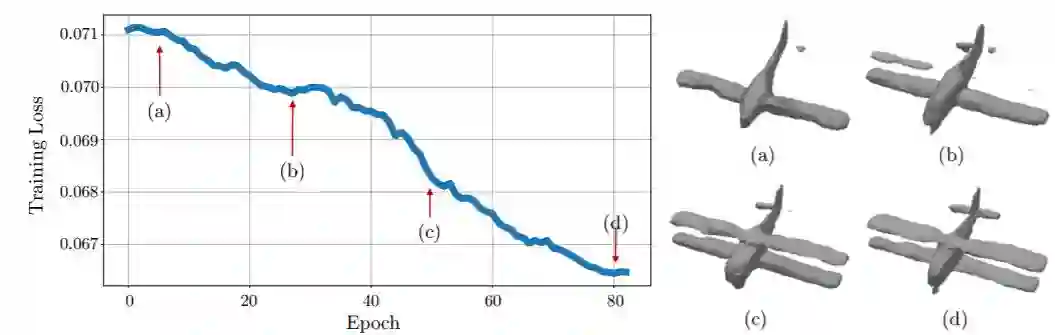
图 12. 使用自然损失的 ShapeHD 随着时间推移的演变图:随着细节的增加,预测的形状变得越来越逼真。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com