学界 | 清华大学提出SA-VAE框架,通过单样本/少样本学习生成任意风格的汉字
选自arXiv
作者:Danyang Sun等
机器之心编译
参与:Nurhachu Null、刘晓坤
近日,清华大学提出了一种风格感知变分自编码器(SA-VAE),通过引入先验知识,结合少量的样本学习,可以有效地将汉字分解成内容部分和风格部分,使我们能快速而自由地生成期望风格的汉字。
论文:Learning to Write Stylized Chinese Characters by Reading a Handful of Examples

论文地址:https://arxiv.org/abs/1712.06424
摘要:因其广泛的适用性,自动书写中文字体是一个很具吸引力但又不乏挑战的任务。在这篇论文中,为了灵活地生成汉字,们提出了一个叫做风格感知变分自编码器(Style-Aware Auto-Encoder,SA-VAE)的框架。具体而言,我们建议通过将一个汉字的隐藏特征分解成内容相关和风格相关的成分来捕捉汉字的不同特征。考虑到复杂的形状和结构,我们将结构信息作为先验知识纳入我们的框架来指导结果的生成。通过推理一个字体未知的汉字的风格组成,我们的架构展示出了强大的单样本/少样本(one-shot/low-shot)泛化能力。据我们所知,这是首次尝试仅仅通过观察一个或者少数样本生成新字体汉字的工作。通过融合不同内容和风格的特征向量来生成不同风格的汉字,大量实验证明了这个架构的有效性,这在实际应用中是非常重要的。
汉字生成因巨大的词汇量和复杂结构而特别具有挑战性。与图像生成任务(例如人脸 [35]、卧室 [29])不一样,汉字生成中即使是一个很小的偏差也能导致完全的混乱和错误。为了解决这个问题,我们将字体的知识集成在了框架中,而且考虑到汉字的结构和部首信息,我们提出了哈希编码方法来指导生成。通过这种方式,我们的模型能够容易地被扩展到大词汇量中。同时,与之前基于笔画的方法不同的是,我们的模型在处理手写字体的时候也表现良好。
为了解决新风格推理的挑战,也就是说,生成一种在训练阶段没有见过的风格,我们在字体库中收集了很多字体风格,包括打印体和手写体。依靠模型的强大生成能力,我们可以做出合理的推断,并且允许在不用重新训练的情况下就能生成新字体,而传统的模型都需要重新训练。
大量实验证明,我们的方法可以通过仅读取少量样本就生成中文字体,包括打印体和手写体。据我们所知,据我们所知,这是首次尝试仅仅通过单样本/少样本设置来生成新字体汉字(包括打印体和手写体)的工作。总结一下,我们的主要贡献在以下三个方面:
我们提出了一个新型的交叉逐对优化的方法用于风格特征提取,它也是以弱监督的形式解决解耦合问题的一个通用技术。
我们将汉字的域知识以先验知识的形式引入模型中,并提出了一种信息编码方法来指导汉字生成。
我们提出的模型(SA-VAE)可以实现准确的风格推理,并以单样本/少样本的方式生成中文字体。
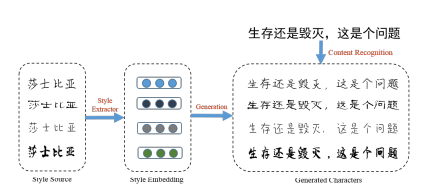
图 1:基于我们的方法的汉字生成过程描述。给定少量特定字体的样本(例如签名),我们推理不同字体的隐藏向量。然后,我们通过识别它们的内容在少量样本的基础上生成中文字体(「生存还是毁灭,这是个问题」),可以看到,用来训练的样本中,每个风格只有四个汉字(「莎士比亚」)。
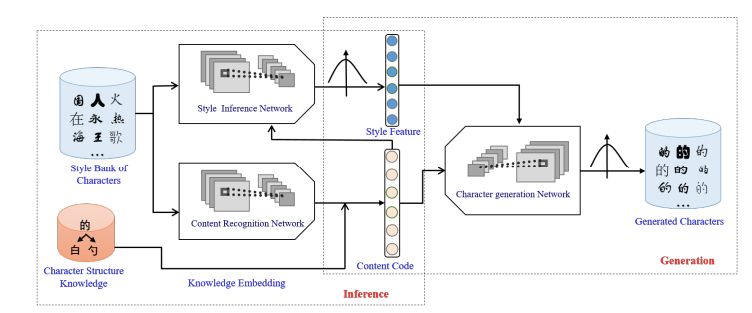
图 2:我们提出的 SA-VAE 框架主要包含三个子网络,包括内容识别网络 C、风格推理网络 S,以及汉字生成网络 G。S 和 C 分别提取风格特征和内容特征,G 结合这两个特征生成汉字。另外,我们引入了汉字的域知识 K 以得到更多的内容表征信息。训练过程是以交叉逐对的方式进行的。
如图 2 所示,我们的模型,主要包含三个子网络,包括内容识别网络 C、风格推理网络 S,以及汉字生成网络 G。整个过程可以分为两个阶段——推理阶段和生成阶段。在推理阶段,首先,我们分别基于内容识别网络和风格推理网络将隐藏特征解耦成与内容和风格相关的成分。为了得到更多信息的内容编码,字体结构和部首的知识进一步被集成在内容向量中。在生成阶段,我们将内容向量和风格向量作为一个反卷积网络的输入,所以字体可以通过之前推理阶段得到的风格特征进行重构。为了可靠的解耦,训练过程是以交叉逐对的方式进行的,这意味着生成的汉字提取了不同的源汉字中的风格特征和内容编码。
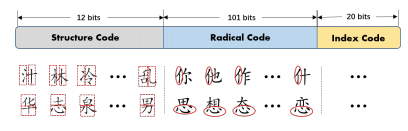
图 3:编码方法描述,包含结构信息和部首信息。
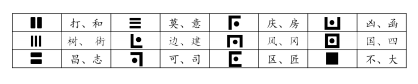
图 4:汉字的全部 12 种结构和对应的例子。

图 5:汉字中经常使用的部首和对应的例子。
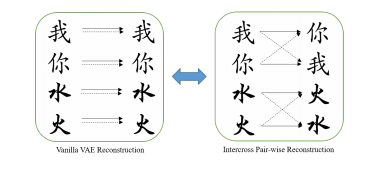
图 6:Vanilla 变分自编码器和我们的交叉逐对训练的对比:实线和虚线分别代表风格提供者和内容提供者。
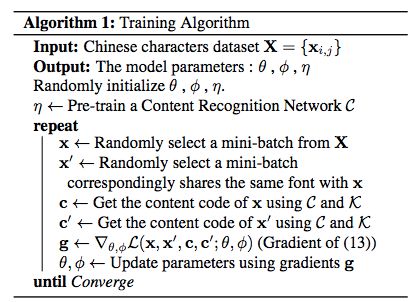
训练算法
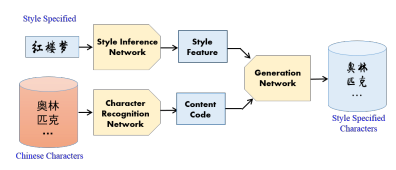
图 7:只需少数汉字就能通过我们的风格推理网络 S 提供新的风格,结合我们数据库中的内容编码作为生成网络的输入,我们可以得到新风格的任何汉字。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击「阅读原文」,在 PaperWeekly 参与对此论文的讨论

