不再鹦鹉学舌:26亿参数量,谷歌开放领域聊天机器人近似人类水平
选自Google博客
开放领域聊天机器人是人工智能研究的一个重要领域。近日谷歌一篇博客介绍了团队在该领域的最新研究进展——Meena 机器人。
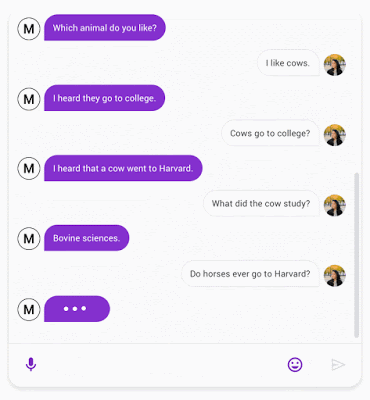
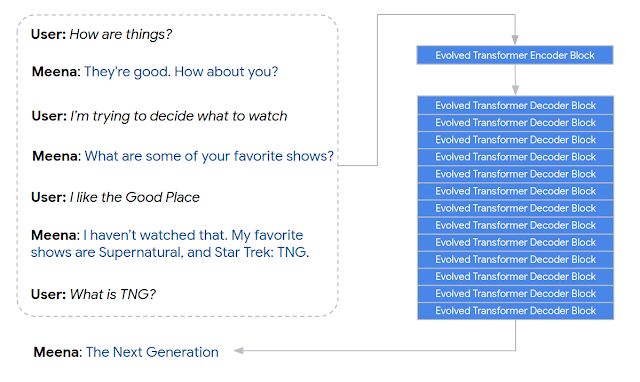
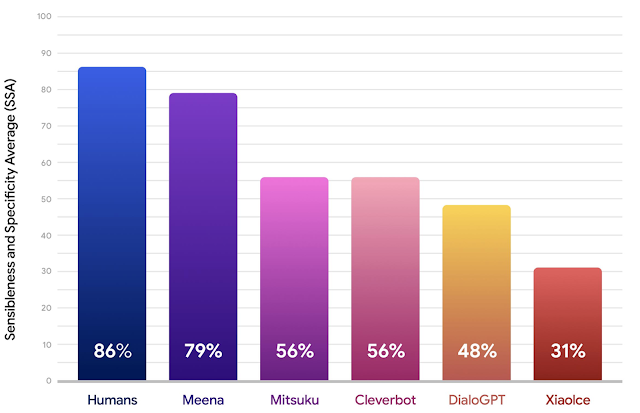
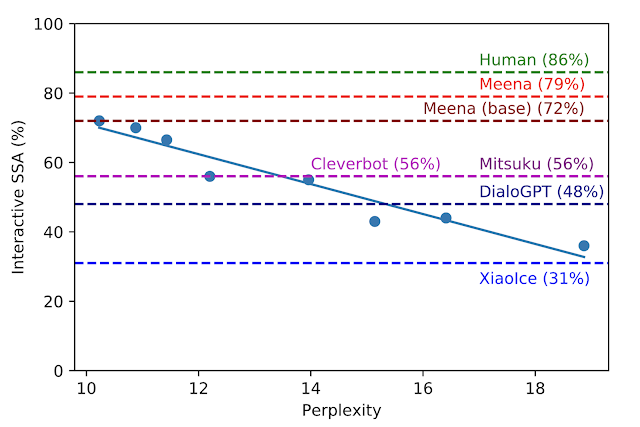
登录查看更多
相关内容
专知会员服务
35+阅读 · 2020年4月30日
Arxiv
11+阅读 · 2019年11月4日
Arxiv
15+阅读 · 2018年10月11日





相关VIP内容
专知会员服务
35+阅读 · 2020年4月30日
相关资讯
相关论文
Arxiv
11+阅读 · 2019年11月4日
Arxiv
15+阅读 · 2018年10月11日