【ECCV2020-Google】多模态Transformer视频检索,Multi-modal Transformer

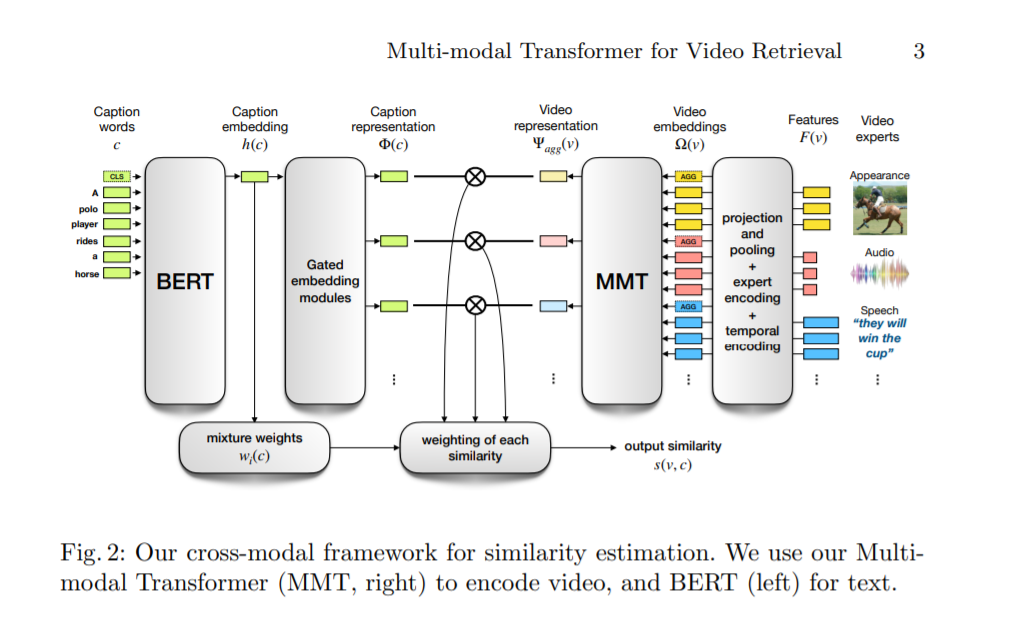
检索与自然语言查询相关的视频内容对有效处理互联网规模的数据集起着至关重要的作用。大多数现有的字幕-视频检索方法都没有充分利用视频中的跨模态线索。此外,他们聚合每帧的视觉特征与有限的或没有时间信息。在本文中,我们提出了一种多模态Transformer联合编码视频中不同的模态,使每一个模态关注其他模态。transformer架构还被用于对时态信息进行编码和建模。在自然语言方面,我们研究了联合优化嵌入在多模态转换器中的语言的最佳实践。这个新的框架允许我们建立最先进的视频检索结果在三个数据集。更多详情请访问http://thoth.inrialpes.fr/research/MMT。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MTVR” 可以获取《【ECCV2020-Google】多模态Transformer视频检索,Multi-modal Transformer》专知下载链接索引



登录查看更多
相关内容
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日



相关VIP内容
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日