【干货】这8种神经网络结构,你掌握了几个?
【导读】近日,James Le撰写了一篇博文,全面阐述了神经网络中经典的八种神经网络结构。包括感知器、卷积神经网络、循环神经网络、LSTM、Hopfield网络、玻尔兹曼机网络、深度信念网络、深度自编码器。这些都是深度学习中非常经典的网络。文章中,作者会深入浅出地对每个网络结构进行讲解,如果您想要从事机器学习或深度学习的研究,那么这篇文章可以带您快速了解神经网络的经典网络结构。如果您已经有了相关的基础,希望通过阅读本文,给您带来新的感悟。专知内容组编辑整理。

The 8 Neural Network Architectures Machine Learning Researchers Need to Learn
机器学习研究人员需要掌握的八种神经网络结构
机器学习核心框架的发展历史
▌为什么你需要机器学习?
机器学习可以解决人类不能直接解决的复杂的问题。有些问题过于复杂,以至于不能通过编写程序来解决,因此,我们向机器学习算法提供了大量的数据,让算法通过学习数据来搜索一个模型来解决问题。
让我们来看两个例子:
编写程序来解决问题可能是非常困难的,例如在杂乱的场景中、以及新的照明条件下从一个新的视角来解决诸如识别三维物体这样的问题是非常困难的。 我们不知道要怎么写代码来解决这个问题,因为我们不知道这个识别过程是如何在我们的大脑中完成的。 即使我们知道该怎么做,要编写的程序可能会非常复杂。
另外,通过写程序来判别一个信用卡交易属于诈骗的概率也是很难的。因为这没有任何简单可靠的规则指导编程,我们需要结合大量的弱规则。 因为欺诈是一个动态的目标,程序也需要不断变化。
因此,出现了机器学习方法:机器学习并不是像传统方法那样,对每一个特定的任务都要编写特定的代码,在机器学习中,我们收集了许多示例,然后通过机器学习算法利用这些样例自动生成程序。这种通过机器学习自动生成的程序与传统的手写程序有很大的不同。如果机器学习的程序正确,这个程序就适用于新的案例。如果数据发生变化,程序也可以通过对新数据的训练来改变程序。当前,机器学习大量的计算比对某个特定任务编程来的更划算。
考虑到这一点,机器学习能解决以下问题:
模式识别:真实场景中的目标识别、面部识别和表情识别、声音识别;
异常识别:异常信用卡交易行为,核电站内的传感器读取模式异常;
预测:股票走势预测,对电影的喜好预测。
▌什么是神经网络?
神经网络是机器学习中的一类方法。如果你学习了Coursera机器学习课程,可能对神经网络有所了解。神经网络是机器学习领域中的革命性方法。神经网络是受生物神经网络的启发,特别是深度神经网络目前取得了很好的效果。神经网络本身就是一般函数的近似,这就是为什么它们几乎可以被应用到任何机器学习的问题中,来学习一个从输入到输出空间的复杂映射。
有三个原因能说服你学习深度神经网络:
理解人类大脑的工作机制:人脑是非常复杂且脆弱的,所以我们要用计算机模拟其工作机制。
理解并行计算风格(受神经元及其连接启发):这是一种与按照顺序计算相反的计算风格。
使用学习算法(受到人类大脑的启发)来解决实际问题:学习算法是非常有用的,即使它们不是大脑实际的工作原理。
学完了Andrew Ng的著名的机器学习课程Coursera(https://github.com/khanhnamle1994/machine-learning )之后,我们主要开始学习神经网络和深度学习。互联网上有很多关于神经网络和深度学习的课程,其中Geoffrey Hinton的课程“Neural Networks for Machine Learning”是很不错的。
https://github.com/khanhnamle1994/neural-nets。
如果你是深度学习从业者,或者想深入了解这些知识,那么可以学习一下这个课程。Geoffrey Hinton无疑是深度学习领域的教父级的人物,他的课程必定也是不同寻常的。在本博文中,我将介绍这个教程中提到的八种神经网络结构。

这八种神经网络结构可以被分为三类:
1. 前馈神经网络(Feed-Forward Neural Networks)
这是最常见的神经网络类型。第一层是输入,最后一层是输出。如果隐含层不止一层,那么被称为“深度”神经网络。每一层神经元的活动通过非线性组合输入到下一层神经元。
2. 递归神经网络(Recurrent Networks)
在网络连接中定义有向环, 这意味着你有时可以按照箭头回到你开始的地方。 因为比较复杂,可能有时会导致很难训练。
目前,人们仍然在探索如何更加高效地训练递归神经网络。递归神经网络能对序列数据进行建模。它们相当于一个非常深的网,每一层都有一个隐藏层;每次都使用相同的权重并且每次都有输入。该网络可以在很长一段时间内记住隐藏状态的信息,但很难用这种信息进行训练。
3. 对称连接网络(Symmetrically Connected Networks)
它们像递归神经网络,但是单元之间的连接是对称的(它们在两个方向上都有相同的权重)。对称网络比递归网络更容易分析。但是它受限于专注某种功能,因为必须要服从能量函数。没有隐藏层的对称连接网络也被称为“Hopfield”网络。有隐藏层的对称网络被称为“玻尔兹曼机(Boltzmann machines)”。
▌1.感知器(Perceptrons)
考虑到第一代神经网络,感知器仅仅是单个神经元的计算模型。感知器在上个世纪60年代的时候被Frank Rosenblatt推广。他认为该算法非常强大,并做了大量的宣传。在1969年,Minsky 和Papers出版了一本书,名为“Perceptrons”,书中分析了它可以做什么以及有什么限制。许多人认为这些限制适用于所有的神经网络模型。然而,感知器的学习过程在今天仍然被广泛使用,因为它可以包含大量的特征向量,其中可以有数百万的特征。
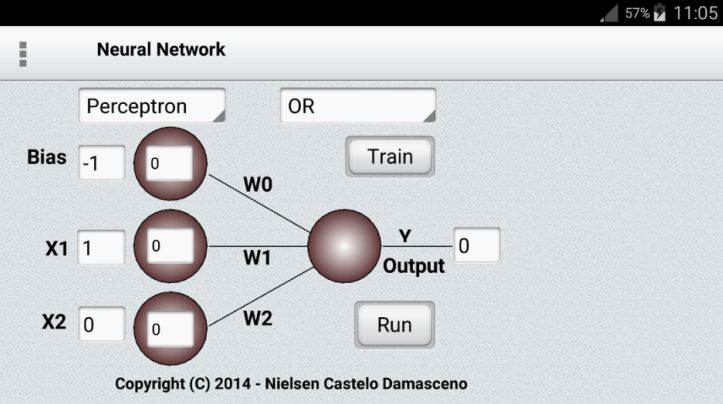
在统计模式识别的范例中,我们首先将原始输入向量转换为特征激活向量。 然后,我们使用传统的手写程序来定义特征。 接下来,我们学习如何对每个特征进行加权以获得单个标量。如果这个数量高于某个阈值,我们认为输入向量是目标类的一个正例。标准的Perceptron体系结构遵循前馈模型,输入被送入神经元中,然后被处理并产生输出。在下图中,这意味着网络自下而上训练:从底部输入,从顶部输出。
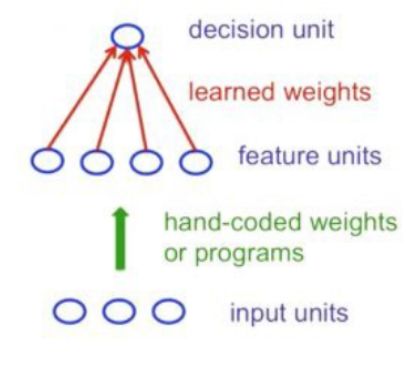
但是,感知器确实有局限性:如果你手动选择特征,并且使用了足够多的特征,则几乎可以做任何事情。 对于二进制输入向量,我们可以为每个指数多的二进制向量分别设置一个特征单元,因此我们可以对二进制输入向量进行任何可能的区分。 但是,一旦确定使用手工编码的特征,感知器就会遇到很多限制。
这个结果对感知器来说是毁灭性的,因为整个模式识别的重点是识别出模式,即使是像翻译一样的转换方法。 Minsky和Papert的“群体不变定理(Group Invariance Theorem)”表明,对于一个感知器不能做的工作,如果使用一群感知器就可以。为了处理这种需求,感知器需要使用多个特征单元来识别子模式的转换。 所以模式识别中棘手的部分必须由手工编码的特征检测器来解决,而不是学习的过程来解决。
没有隐藏层的网络在学习输入到输出的映射中也是非常有限的。 更多的线性单位层不会改善,因为线性组合仍然是线性的,即使将输出做成非线性的也是不够的。因此,我们需要多层自适应非线性隐藏单元。 但是我们如何训练这样的网络呢? 我们需要一种有效的方式来适应所有的权重,而不仅仅是最后一层。学习隐藏单元的权重等同于学习特征。这很困难,因为没有人直接告诉我们隐藏单位应该做什么。
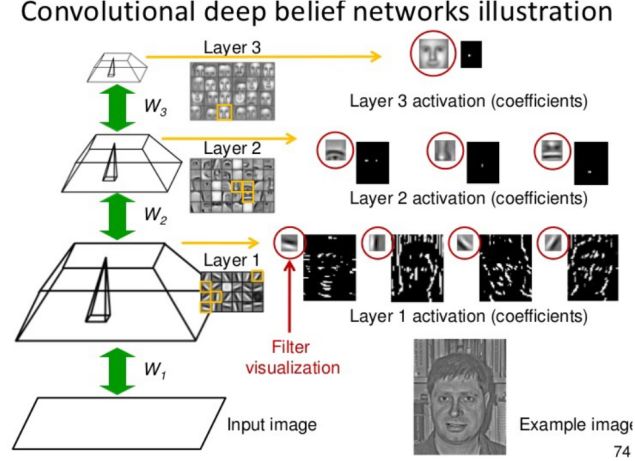
▌2.卷积神经网络(Convolutional Neural Networks)
机器学习研究一直以来都专注于目标检测问题上。但是有各种各样的挑战:
分割:真实的场景与其他物体混杂在一起。很难说哪些片段是属于同一个物体的。目标的一部分可能隐藏被其他物体遮挡。
光照:像素的强度由光照决定,光照对物体的影响非常大。
变形:物体可能会产生形变(物体以各种非仿射方式变形)。例如,手写字体可能尺寸变化:可能有一个大的圈或可能只是一个小点。
可用性:目标的类别通常由他们的用途决定。例如,椅子是指一类坐着的东西,所以他们有各种各样的物理形状。
视角:视角的变化导致图像的变化,标准的方法不能处理视觉变化。会导致输入维度(即像素)之间的信息跳跃。
设想一个病人年龄的医学数据库,有时我们希望对输入维度进行正常的权重编码!要应用机器学习,我们首先要消除这个维度差异(不同数据具有不同的维度)。
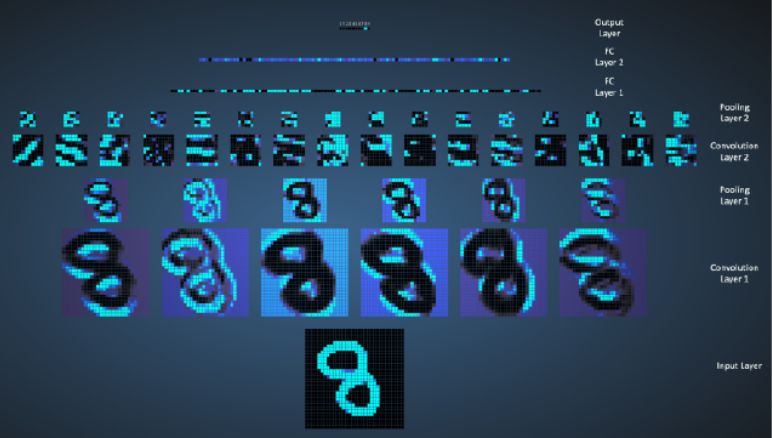
复制特征方法(replicated feature approach)是目前神经网络解决目标检测问题的主要方法。它使用很多具有不同位置的相同特征检测器的不同副本。它也可以在比例和方向上复制。复制大大减少了要学习的参数数量。它使用几种不同的特征类型,每个特征类型都有自己的复制检测器映射。它还允许每个图像块以多种方式表示。
那么复制特征检测器是如何实现的呢?
等价活动:复制特征不会使神经的活动保持不变。但是活动是同等的。
不变的知识(Invariant knowledge):在训练期间如果某个特征在某些位置有用,那么该特征的检测器可用于测试期间的所有位置。
1998年,Yann LeCun和他的合作者开发了一个非常棒的手写数字识别器,称为LeNet。它用了具有许多隐藏层的前馈网络,并用了反向传播,每一层都有许多复制单元的映射,将附近复制单元的输出进行pooling操作,一个宽的网络可以同时处理几个字符。这个网络被命名为卷积神经网络。有趣的事实:这个网络被用于读取北美约10%的支票。
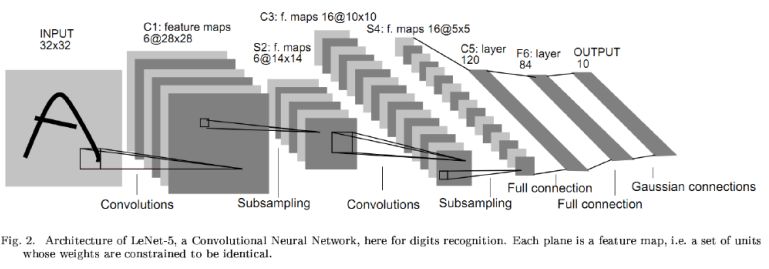
卷积神经网络可用于所有与物体识别相关的工作,从手写数字到3D物体的物体识别。然而,从彩色图像中识别真实物体比识别手写数字复杂得多。彩色图像比灰度图像多几百倍(1000 vs 10),上百倍多的像素(256 x 256彩色vs 28 x 28灰色)。识别三维场景的二维图像,需要对混乱的场景进行分割。
然后是ILSVRC-2012 ImageNet竞赛,该数据集包含约120万张高分辨率训练图像。测试图像没有初始标签,你的算法需要判断图像中物体真实的类别。很多有名的计算机视觉小组在这个数据集上进行试验,他们分别来自牛津大学,INRIA,XRCE ...通常,他们的计算机视觉系统使用复杂的多阶段系统(multi-stage systems),且早期阶段是通过对几个参数进行手动调整优化的。

比赛获胜者Alex Krizhevsky(NIPS 2012)在Yan LeCun的基础上开发出了非常深的卷积神经网络。其架构包括7个隐藏层(不包括最大池化层)。开始的层是卷基层,而最后2层为全连接层。激活函数是在每个隐藏层中修正线性单元。这些训练要快得多并且比逻辑单元更具表现力。除此之外,它也使用competitive normalization来抑制附近单元的活动。这有助于不同强度的变化。
有几个技术窍门能明显改善神经网络的泛化能力:
1. 在256 x 256图像上随机选择224 x 224个小块获得更多的数据。在测试时,结合10个不同小块的意见:四个224 x 224角落的小块和中央224 x 224小块再加上这5个小块的重复。
2. 用Dropout来规范全连接层(包含大部分参数)。Dropout意味着一层中的一半隐藏单元是随机失效的。这防止隐藏单元过于依赖其他隐藏单元。
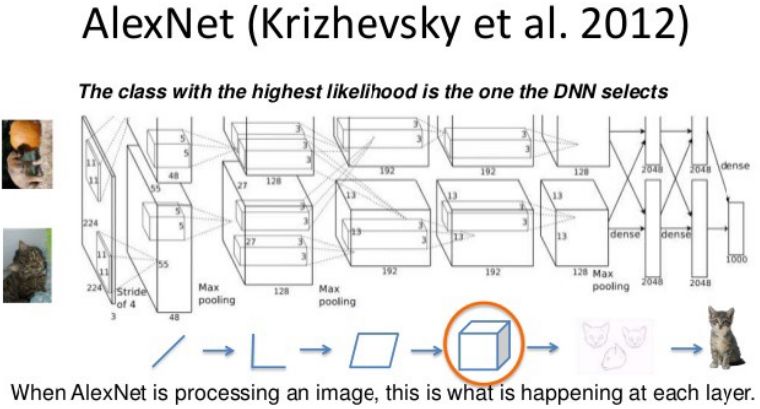
在硬件要求方面,Alex使用2个Nvidia GTX 580 GPU(1000多个快速小内核)非常高效实现了卷积网络。 GPU对于矩阵相乘非常有用,并且对内存也有很高的带宽。这允许他在一个星期完成网络的训练,并使其在测试时快速地结合10个块的结果。如果我们可以足够快地传递状态,就可以在很多内核上训练网络。 随着内核越来越便宜,数据集越来越大,相比传统的计算机视觉系统,大型神经网络速度将更快。
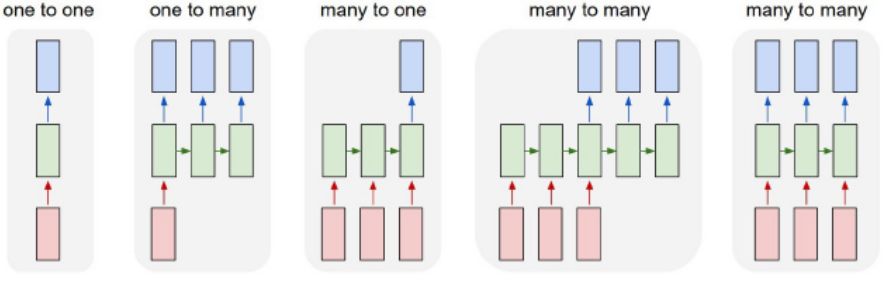
▌3.循环神经网络(Recurrent Neural Network)
为了理解RNN,我们需要对序列模型进行简要概述。当把机器学习应用于序列建模时,我们经常会遇到一个问题:想要将一个输入序列转换成一个输出序列,而这两个序列是在不同的领域;例如,将一系列声音转换成一个单词的序列。没有单独的目标序列时,我们可以通过尝试预测输入序列的下一项得到一个信号。目标输出序列是将输入序列前进1步。这似乎比试图从其他像素预测图像中的一个像素或者从图像的其余部分预测图像的一个片段更加靠谱。预测一个序列的下一项使得监督和无监督的学习之间的区别变模糊了。它使用有监督方法学习,但不需要单独的引导信号(teaching signal)。
无记忆模型(Memoryless models)是这个任务的标准方法。特别是,自回归模型使用“delay taps”来从固定数量的序列中预测下一个项; 前馈神经网络是广义自回归模型,它使用一个或多个非线性隐藏单元的层。但是,如果我们给我们的生成模型一些隐藏的状态,如果我们给这个隐藏状态赋予自己的内部动态,我们会得到一个更有趣的模型:它可以将信息的长时间以隐藏状态存储。如果动态是嘈杂的,他们产生的隐藏的状态也是嘈杂的,我们永远不知道它的确切的隐藏状态。我们所能做的最好的办法就是推导出空间上的概率分布隐藏状态向量。这个推断仅适用于两类隐藏状态模型。
循环神经网络非常强大,因为它们将两种属性结合在一起:1)分布式隐藏状态,允许他们存储很多有关过去的信息,2)非线性动态(non-linear dynamics)允许他们以复杂的方式更新隐藏状态。利用足够的神经元和时间,RNN可以很强大。那么RNN有哪些行为呢?他们可以振荡,他们可以解决点之间的干扰,他们可以表现混乱。他们可能会学习实现很多个小程序,每个小程序都捕获了一块并行运行的知识,相互作用产生非常复杂的效果。
但是,RNN的计算能力使得它们训练起来非常困难。训练RNN是非常困难的,因为梯度爆炸或消失。当我们在许多层中进行反复传递,梯度的大小发生了什么变化?如果权重很小,梯度呈指数递减。如果权重很大的话梯度呈指数增长。传统的前馈神经网络可以应付这些指数效应,因为他们只有少数隐藏层。另一方面,在训练长序列的RNN中,可能很容易梯度爆炸或消失。即使有良好的初始权重,也很难检测到当前的目标输出是依赖先前时刻的输入的,所以RNNs很难处理远程依赖关系。
基本上有4种有效的方法来学习RNN:
长短期记忆(Long Short Term Memory):让RNN脱离那些用来记住长时间值的小模块。
Hessian Free优化(Hessian Free Optimization):使用优化器处理梯度消失问题,通过使用特殊的优化器,它可以检测出带有微小梯度但更小曲率的方向。
回声状态网络(echo state networks):初始化输入 - >隐藏和隐藏 - >隐藏和输出 - >隐藏层的连接是精心设计的,所以这个隐藏的状态有一个巨大的弱耦合振荡器的储存器可以由输入进行选择性的驱动。
良好的动量初始化(Good initialization with momentum):像回声(Echo)状态网络一样初始化网络,但是,用动量(momentum)学习所有的连接。
▌4.长/短期记忆网络(Long/Short Term Memory Network)
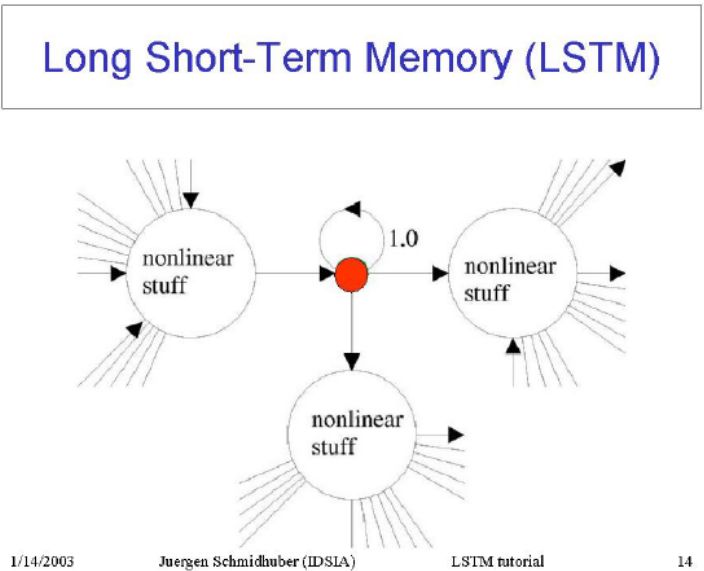
Hochreiter&Schmidhuber(1997)解决了一个问题,使得RNN能记住很长一段时间的信息(比如几百个时间步),并建立所谓的长短期记忆网络(LSTM:Long Short Term Memory)。他们使用具有乘法相互作用的logistic和线性单元来设计存储器单元(Memory Cell)。当“write”大门打开信息随时进入单元。只要其“keep”门打开,信息保存在单元中。 信息可以通过打开“read”门而从单元中读取。
草书手写字体识别是一个RNN的任务。输入是一个坐标序列(x,y,p),其中p表示笔是向上还是向下。输出是一个字符序列。Graves&Schmidhuber(2009)表明,带有LSTM的RNN是目前是草书字体识别的最佳系统。简而言之,他们使用一系列小图像作为输入而不是笔坐标。

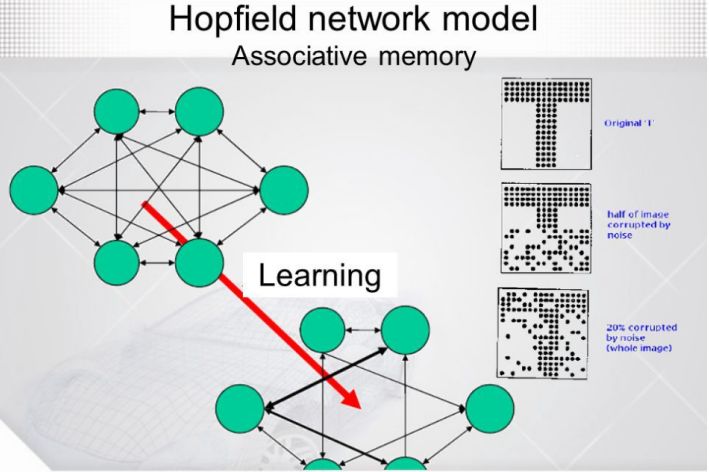
▌5.Hopfield网络(Hofield Networks)
非线性单位的循环网络分析起来是非常困难的。他们可以以许多不同的方式工作:稳定的状态,振荡,或无法预测的轨迹。 Hopfield网络由二进制阈值单元组成,他们之间进行循环连接。1982年,John Hopfield意识到,如果连接是对称的,就有一个全局能量函数。每个二进制“配置”的整体网络有能量;而二进制阈值决策规则使网络来最小化这个能量函数。一个利用这种计算的方式就是把记忆当作神经网络能量最小值。使用能量最小值来表示内存提供了一个内容可寻址的存储器。 一个项目可以通过仅仅了解其内容的一部分来访问,可以很有效应对硬件损坏的情况。
每次进行一次配置,我们都希望创造一个新的能量最小值。但是,如果在中间位置附近有两个最小值怎么办?这限制了Hopfield网络的能力。那么我们如何提高Hopfield网络的能力呢?物理学家对他们了解的大脑工作机制的数学解释引以为傲。许多关于Hopfield网络及其存储容量的论文在物理学期刊上发表。最终,伊丽莎白·加德纳(Elizabeth Gardner)发现存在一个更好的存储规则,该规则可以充分利用权重。在给定某向量中所有其他单元状态的情况下,她没有一次性存储向量,而是多次循环训练,并利用感知器收敛过程来训练每个单元,使其具有正确的状态。统计学家称这种技术为“伪似然pseudo-likelihood”。
Hopfield网络还有另一个计算任务。我们不用网络来存储 memories,而是用它来构建感官输入的解释。输入用可见单元表示,解释用隐藏单元的状态表示,用能量表示解释的好坏。
▌6.玻尔兹曼机网络(Boltzmann machine Network)
Boltzmann Machine是一种随机递归神经网络。可以看作是Hopfield网络的随机生成的副本。它是最早能够学习神经网络内部表示的方法之一,能够解决复杂组合问题。
玻尔兹曼机学习算法的学习目标是最大化玻尔兹曼机分配给训练集的二进制向量的概率的乘积。如果我们做了如下的事情,这相当于最大化玻尔兹曼机分配给训练向量的对数概率之和:1)让网络在没有外部输入的情况下在不同时间稳定分布; 2)每次采样一个向量,也等价于最大化我们得到N个训练样本的概率。
2012年,Salakhutdinov和Hinton提出了玻尔兹曼机的一个高效的小批量(mini-batch)学习过程。对于正向(positive phase),首先将隐藏层概率初始化为0.5,然后将可见单元上的数据向量进行固定,然后将所有隐藏单元并行更新,直到收敛。在网络收敛之后,记录每个单元对的PiPj,并在mini-batch中对所有数据进行平均。
对于反向(negative phase):首先保留一组“幻想粒子(fantasy particles)”。每个粒子都有一个全局的值。然后依次更新每个幻想粒子中的所有单位。对于每一个连接单元对,平均值SiSj超过所有的幻想粒子。
在普通玻尔兹曼机中,单元的随机更新是有序的。有一个特殊的体系结构允许更有效的交替并行更新(层内无连接,无跨层连接)。这个mini-batch程序使玻尔兹曼机的更新更加并行化。这就是所谓的深度玻尔兹曼机(DBM),即有很多缺失连接的普通玻尔兹曼机。
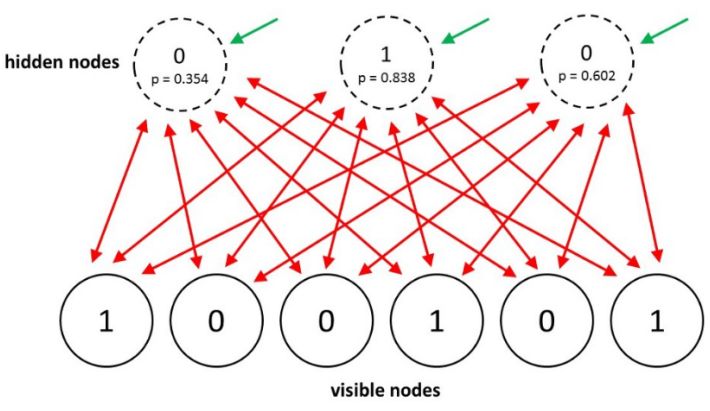
2014年,Salakhutdinov和Hinton对他们的模型提出了另一种升级,称之为Restricted Boltzmann Machines。他们通过限制连通性,来使推理和学习变得更容易(隐单元只有一层,隐单元之间没有连接)。在RBM中,若可见单元被固定时(clamped),只需要一步就能达到热平衡。
另一个有效的小批量mini-batch RBM学习过程如下:
对于正向,首先在可见单元上处理数据向量。然后计算所有可见单元和隐藏单元对<ViHj>的确切值。对于每个连接的单元对,mini-batch中的所有数据的平均值为<ViHj>。
对于反向,也要保留一组“幻想粒子”。然后用交替并行更新的策略,对每个幻想粒子进行若干次更新。对于每一个连接的单位对,所有幻想粒子的平均值为ViHj。
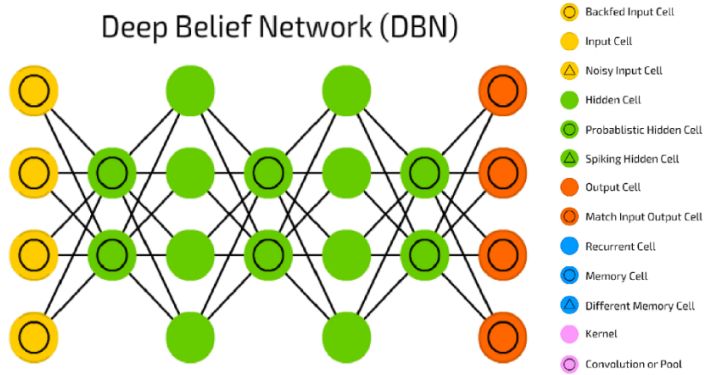
▌7.深度信念网络(Deep Belief Network)
反向传播被认为是人工神经网络中的标准方法,用于在处理一批数据之后计算每个神经元的误差贡献。但是,使用反向传播也存在一些问题。首先,它需要有标签的训练数据; 而几乎所有的数据都没有标签。其次,学习时间效率不高,这意味着隐藏层数多的网络很慢。第三,它可能会陷入局部最优解,所以对于深度网络来说,它们是远远不够的。
为了克服反向传播的限制,研究人员已经考虑使用无监督的学习方法。这有助于继续使用梯度方法来调整权重的效率和简化过程,还可以用它来建模感观输入。特别是,他们能调整权重,以最大化生成模型的概率。问题是我们应该学习什么样的生成模型?它可以是像玻尔兹曼机这样的基于能量的模型吗? 还是由理想化的神经元组成的因果模型? 还是两者的混合?
信念网络(belief net)是由随机变量组成的有向无环图。使用belief net,我们可以观察到一些变量,并且我们想要解决下面2个问题:
1)推理问题:推断未观测的变量的状态; 2)学习问题:调整变量间的相互作用,使网络更有可能生成训练数据。
早期的图模型使用专家定义的图结构和条件概率。那时,图结构是稀疏连接的;所以研究人员最初的重点是做正确的推断,而不是学习。对于神经网络来说,学习才是最重要的,因为知识来是从训练数据学习到的,因此手动输入知识并不明智。神经网络的目的并不是提高可解释性或稀疏连接。 不过,还是有神经网络版的信念网络(belief nets)。
随机二元神经元组成的生成神经网络有两种类型:1)基于能量的,其中我们使用对称连接方法连接二元随机神经元,以获得玻尔兹曼机; 2)因果关系,我们在一个有向无环图连接二进制随机神经元,以获得Sigmoid Belief Net。这两种类型的描述超出了本文的范围。
▌8.深度自编码器(Deep Auto-encoders)
最后,我们来讨论深度自编码器。它看起来像一个非线性降维的好方法,原因如下:它们提供了两种灵活的映射方式。在训练目标的数量上,学习时间是线性的(或更好的)。最终的编码模型相当紧凑和快速。然而,使用反向传播来优化深度自动编码器是非常困难的。在初始权重较小的情况下,反向传播梯度消失。我们现在有更好的方法来优化它们。要么使用无监督的逐层预训练,要么像回声状态网络那样仔细地初始化权重。
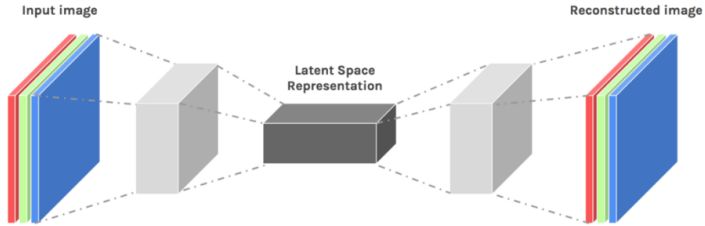
对于预训练任务,实际上有三种不同类型的浅层自编码器:
1、 RBM作为自动编码器:当我们用one-step contrastive divergence(一阶对比散度)训练一个RBM时,它试图使重建数据使之看起来像原始数据。它就像一个自动编码器,但是它通过使用隐藏层中的二进制活动来强化正则。经过最大似然训练后,RBM与自动编码器不同了。我们可以用一堆浅自动编码器来替代用于预训练的RBM。然而,如果浅层自动编码器通过惩罚平方权重来调整的,那么预训练就不是有效的。
2、 去噪自编码器:通过将其许多分量设置为0(如dropout,但是用于输入的数据),从而将噪声添加到输入向量。他们仍然需要重建这些组件,因此必须提取能够捕获输入之间相关性的特征。使用表示自编码器的堆栈可以使预训练非常有效。与RBM预训练一样好甚至更好。评估预训练也更简单,因为我们可以很容易地计算目标函数的值。它缺乏我们用RBM获得的好的变分边界,但这只是理论研究。
3、 压缩自编码器:另一种正规化自编码器的方法是,使隐藏单元的活动对输入尽可能不敏感。但是不能忽视这些输入,因为他们必须重建这些输入。我们通过惩罚每个隐藏活动相对于输入的平方梯度来达到这个目的。压缩自编码器在训练前工作得很好。这些代码只有一小部分隐藏单元对输入变化敏感的属性。
简而言之,现在有很多不同的方法来进行特征的逐层预训练。对于没有大量标记的数据集,预训练有助于后续的判别式学习。对于大型有标记数据集,并不需要使用无监督预训练对监督学习中使用的权重进行初始化,即使对于深度网络也是如此。预训练是初始化深度网络权重的第一个好方法,不过现在还有其他方法。如果我们把网络变得更大,我们需要再次进行预训练!
说了这么多...(Last Takeaway)
神经网络是有史以来最优美的编程范例之一。 在传统的编程方法中,我们将大问题分解成计算机可以轻松执行的许多精确定义的小任务。相比之下,在神经网络中,我们不告诉计算机如何解决我们的问题。 相反,它从观测数据中学习,找出解决问题的办法。
当今,深度神经网络和深度学习在计算机视觉、语音识别和自然语言处理等许多重要问题上取得了出色的表现。在Google,微软和Facebook等公司大规模部署。
我希望这篇文章能帮助你学习神经网络的核心概念,包括最先进的深度学习技术。 您可以从我的GitHub中获取Hinton's Coursera课程所做的所有ppt,研究论文和编程任务。 祝你好运学习!
GitHub代码:
https://github.com/khanhnamle1994/neural-nets
原文链接:
https://medium.com/@james_aka_yale/the-8-neural-network-architectures-machine-learning-researchers-need-to-learn-2f5c4e61aeeb
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!