入坑机器学习,这10个知识点你要了解!

来源:将门创投
本文长度为1581字,建议阅读4分钟
本文为你介绍机器学习的概念、内涵、以及机器学习的相关问题。
【导读】这篇文章主要面向的是非专业的读者,简单直白地介绍了机器学习的概念、内涵、以及机器学习的相关问题。对于专业人士而言也可以依据这篇文章对机器学习的概念做更深入的理解,看看如何向身边朋友们解释你所从事的工作。
1. 机器学习意味着从数据中学习,而AI呢是一个比较炫酷时髦的词。
机器学习基于这样的假设:我们可以通过将正确的数据放到正确的算法中去训练解决一系列复杂的问题。当你需要融资或者发布产品的时候可以毫不犹豫地称之为人工智能(AI),但是你心里需要明白现在AI是一个几乎可以代表一切的时髦用词。

2. 机器学习包括数据和算法,但最主要的部分还是数据。
机器学习算法特别是深度学习近年来取得了极大的成功,但是你需要明白的是数据才是使机器学习成为可能的关键因素。你可以使用简单的算法实现机器学习,但是没有好的数据你将寸步难行。
3. 如果没有大量的数据,那么你还是安心地使用简单的模型吧。
机器学习的任务是从数据中训练出一种模式,探索由参数定义的模型空间。如果你的参数空间太大的话,模型就会在训练数据上出现过拟合,并使得模型失去泛化性。 关于过拟合的详细解释需要很多的数学推导的,但是你需要记住的是,模型越简单越好。
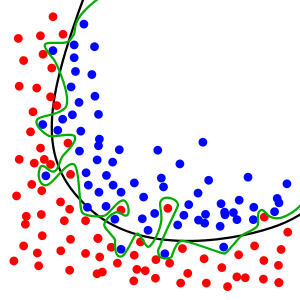
4.机器学习的能力只能到达训练数据所能提供的水平。
“无用输入,无用输出”很好地反映了机器学习的局限性。机器学习只能在提供的训练数据中发现模式,不能够凭空学习出新模式。对于类似分类的监督学习任务来说你需要鲁棒的收集正确标注的特征丰富的数据来作为训练数据。
5.只有训练数据具有代表性的情况下机器学习才会有效。
就像教科书中曾经教会我们的一样“过去的表现并不是未来结果的保障”,机器学习只能在于训练数据同分布的数据上有效。你需要对训练数据和实际数据之间统计上的不对称性保持足够的警觉,同时需要保持模型不断地被训练让它不落伍。
6.机器学习中最复杂的工作来自于数据转换。
在阅读文献的时候你会看到很多眼花缭乱算法,你也许认为机器学习最主要的工作便是选择算法和调节参数。但真实的情况是:机器学习中需要做的最多的工作就是数据清洗和特征工程,你需要将数据的原始特征转换到能更好地表示其中信息的新特征上去。
7. 深度学习是一项革命性的技术,但却不是包治百病的灵丹妙药。
近些年来深度学习被捧上神堂,远远超过了其他的机器学习算法。其中的原因之一就是深度学习可以自动完成传统机器学习算法中需要特征工程才能实现的任务,特别是在图像和声音数据的处理中更是如此。但是我们需要明白深度学习不是万金油,你只能在一定的范围内应用这项技术,同时你也需要在数据清洗和变换上花上很多的精力才行。
8.机器学习极易受到误操作的影响。
“机器学习算法不会杀人,而人类却可能会自掘坟墓”。当机器学习算法失效的时候,很少因为算法本身的的错误,而大多数情况下却是人为的错误造成的。很多情况下你在训练数据中不小心引入了认为错误,或者引入了偏差和其他的系统错误。你需要时刻保持怀疑的态度来使用机器学习算法,并在应用的过程中进行严格的检查。
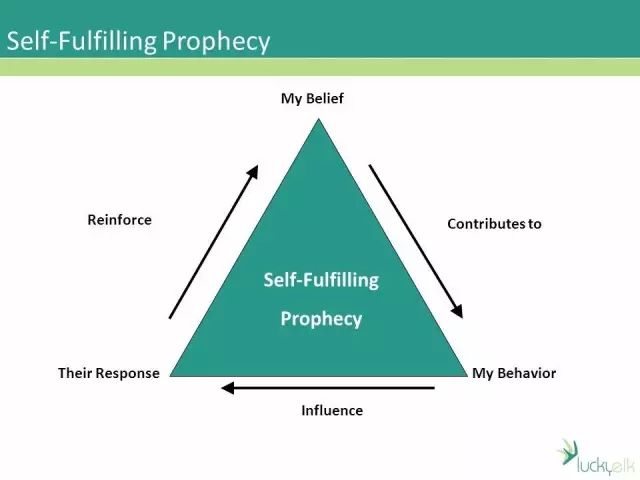
9.机器学习会在不经意间实现自我预言。
在很多机器学习的应用中,今天的决策会影响未来收集的训练数据。一旦机器算法模型引入了一定的模型偏差,那么它会持续地收集新的数据不断强化这一偏差。事实上有些这样的偏差确实会夺取人宝贵的生命。每一个机器学习从业者都要在心中铭记:不要创造自我实现的预言!
10. AI不会拥有自我意识,也不会崛起摧毁人类的。
令人惊讶的是,在机器学习如此普遍的今天,好多人却依旧用科幻小说和电影中的情节来定义和认识AI。的确,科幻小说可以启发人的创造力,但却不应该如此轻信科幻小说,以致于我们对真实的世界产生误解。今天的世界已经有很多需要我们去关注的危险,从别有用心的邪恶的人到无辜的被滥用的机器。所以请大家不要再去担心“天网”和超级人工智能的出现,而是应该用审慎的心态去看待机器学习,让它更加健康地发展为人类服务。
编辑:王璇
校对:吕艳芹
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。





