【干货】seq2seq模型实例:用Keras实现机器翻译
【导读】近日,人工智能学者Ravindra Kompella发表一篇博客,介绍了作者实现的基于keras的机器翻译例子。作者通过一个seq2seq编码器-解码器网络实现英语到法语的自动翻译。作者在博文中详细介绍了自己的模型架构和训练数据,并使用代码片段分步骤对训练过程进行讲解。总之,这是一篇比较详尽的机器翻译应用示例教程,如果你有从事机器翻译或seq2seq模型相关的研究,可以详细阅读一下,相信一定对您的工程和理论都有所帮助。专知内容组编辑整理。
Neural Machine Translation——Using seq2seq with Keras
神经机器翻译——用Keras实现的seq2seq模型
Translation from English to French using encoderdecoder model
使用编码解码器模型实现从英文翻译成法语

这篇文章受启发于keras的例子和关于编码器- 解码器网络的论文。目的是从这个例子中获得直观和详细的了解。本文中我自己关于这个例子的实现可以在我个人的GitHub中找到
keras的例子链接:
https://github.com/keras-team/keras/blob/master/examples/lstm_seq2seq.py
编码器- 解码器网络论文:
https://arxiv.org/abs/1409.3215
GitHub链接:
https://github.com/kmsravindra/ML-AI-experiments/blob/master/AI/Neural%20Machine%20Translation/Neural%20machine%20translation%20-%20Encoder-Decoder%20seq2seq%20model.ipynb
在我们开始之前,可以先看一下我关于LSTM的另一篇文章。这有助于理解这篇文章中的LSTMs的基本原理。
LSTM 文章链接:
https://medium.com/@kmsravindra123/lstm-nuggets-for-practical-applications-5beef5252092
以下是用于训练seq2seq编码器 - 解码器网络的详细网络架构。我们将通过这个图展现。
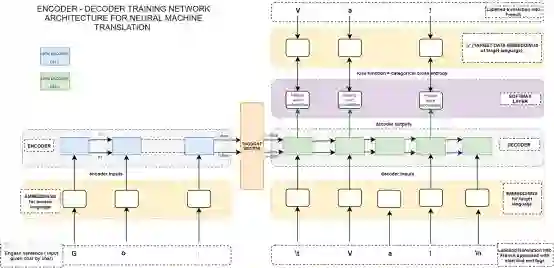
首先我们要去训练网络。然后,我们将着眼于如何将一个给定的英文句子翻译成法语的推断模型。推断模型(用于预测输入序列)有一个稍微不同的解码器架构,当涉及到这个模型的时候我们将详细讨论。
▌训练网络
训练数据是怎样的?
我们有10,000个英语句子,以及相对应的10,000个翻译好的法语句子。所以我们的nb_samples = 10000。
总体的训练计划
1. 为英语和法语句子创建一个one-hot字符嵌入。这些将是编码器和解码器的输入 。法语的one-hot 字符嵌入也将被用作损失函数的目标数据。
2. 将字符逐个嵌入到编码器中,直到英语句子序列的结束。
3. 获取最终的编码器状态(隐藏和cell状态),并将它们作为初始状态输入到解码器中。
4. 解码器在每个时间步长上将有3个输入 - 其中2个是解码器的状态以及还有一个是法语的逐个字符嵌入。
5. 在解码器的每一步,解码器的输出被传送到与目标数据进行比较的softmax层。
▌用代码训练网络的详细流程
请参考代码片段1 - 请注意,我们已经加上了“\t”表示法语句子的开始以及“\n”表示法语句子的结束。这些被标记了的法语句子将被作为解码器的输入。所有的英语字符和法语字符都是在各自单独的集合中存放着。这些集合被转换为字符级字典(以后用于检索索引和字符值)。

代码片段1
请参考代码片段2 - 准备编码器输入的嵌入,解码器输入的嵌入和目标数据嵌入。我们将分别为英语和法语中的每个字符创建one-hot编码(one-hot encoding)。这在代码片段中被称为tokenized_ eng_sentences和tokenized_fra_sentences。它们分别是编码器和解码器的输入。
请注意我们在softmax层输出中比较的target_data法语字符嵌入值相比于解码器输入嵌入偏移了(t+1)(因为目标数据中没有起始标记—请参阅上面的架构图以获得更清晰地理解)。因此,下面的代码片段中的target_data会相应地偏移(注意下面的target_data数组的第二个维度中的k-1)。
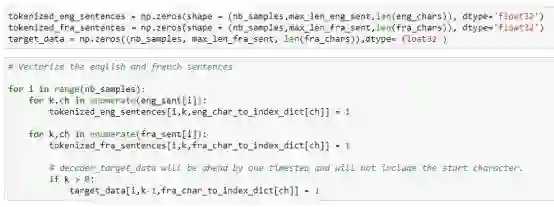
代码片段2
请参考代码片段2 - 正如在我的另外一篇关于LSTM的文章中指出的,嵌入(embeds)(tokenized_eng_sentences 和 tokenized_fra_sentences and target_data)是三维数组。第一个维度对应于nb_samples(在本例中等于10,000)。第二个维度对应于英语/法语句子的最大长度,而第三维度对应的是英语/法语字符的总数。
LSTM文章链接:
https://medium.com/@kmsravindra123/lstm-nuggets-for-practical-applications-5beef5252092
请参考代码片段3:我们将逐字(当然, 还包括它们相应的一个one-hot嵌入)输入到编码器网络中。对于 encoder_LSTM,我们设置了return_state = True。我们没有设置 return_sequences = True(默认情况下,它将设置为False)。这意味着我们只得到了最终的编码cell状态和在输入序列末端的编码隐藏状态,而没有得到每一个时间步长的中间状态。这些将是用来初始化解码器状态的最终编码状态。

代码片段3-用于训练的编码器模型
请参考代码片段3 - 还要注意输入形状已被指定为 (None,len(eng_chars))。这意味着编码器LSTM可以动态地将许多时间步长作为字符的数量,直到它达到这个句子序列的末尾。
请参考代码片段4 - 解码器的输入将会是逐个法语字符嵌入(包含在tokenized_fra_sentences数组中),每一步都与之前的状态值同步。解码器第一步的前几个状态将用我们在代码片段3中的最后编码器状态来初始化。出于这个原因,请注意initial_state = encoder_states已经设置在下面的代码片段中了。在随后的步骤中,对解码器的状态输入将是它的cell状态和隐藏状态。
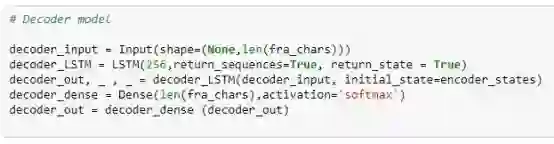
代码片段4 – 用于训练的解码器模型
另外从上面的代码片断,请注意解码器是设置为 return_sequences = True和return_state = True。因此,我们在每个时间步长得到解码器的输出值和两个解码器状态。虽然这里已经声明了return_state = True,但是我们不打算在训练模型时使用解码器状态。其原因是它们将在构建解码器推断模型时使用(我们稍后会看到)。解码器输出通过softmax层,它将学习如何对正确的法语字符进行分类。
请参考代码片段5 - 损失函数是分类交叉熵,即通过比较来自softmax层的预测值和target_data(one-hot法语字符嵌入)来获得。
现在该模型已经准备好进行训练了。我们将训练特定epoch数量下的整个网络模型。
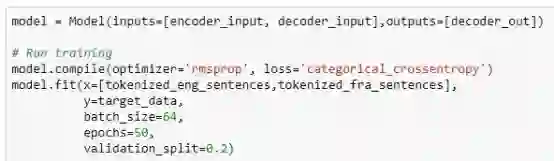
代码片段5 - y = target_data(包含one-hot法语字符嵌入)
▌测试(推断模式)
下面是用于推断模型的架构—推断模型将利用训练中所学到的所有网络参数,但我们单独定义它们,因为在推断过程中的输入和输出与在训练网络时是不同的。
从下图可以看出,网络的编码器端没有变化。因此,我们将新的英语句子(经过one-hot字符嵌入的)向量作为输入序列输入编码器模型并获得最终编码状态。
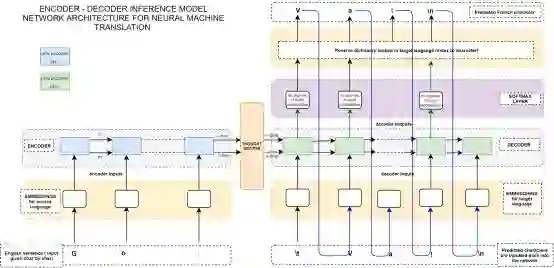
图片B:NMT的编码器-解码器推断模型架构—图片版权@ Ravindra Kompella
将图B和解码器端的图A进行对比。我们可以看到如下的主要变化—
在第一个时间步长,解码器有3个输入 - 开始标记'\ t'和两个编码器状态。我们输入第一个字符'\ t'(它的一个one-hot嵌入向量),将它作为进入解码器的第一个时间步长。
然后解码器输出第一个预测字符(假设它是'V')。
观察蓝色的线是如何连接回到下一个时间步长的解码器输入的。因此这个预测字符“V”将在下一个时间步长中作为对解码器的输入。
另外还要注意,我们只在每个时间步长的softmax层的输出中使用np.argmax函数获得预测字符的一个one-hot嵌入向量。因此,我们对索引进行反向字典查找,以获得实际字符“V”。
从下一个时间步长开始,解码器仍然有3个输入,但不同于第一个时间步长,它们是先前预测字符的one-hot编码(之前的解码器cell状态和之前的解码器隐藏状态)。
▌鉴于以上的理解,现在让我们来看看代码
请参参考代码片段6 - 编码器推断模型是相当的直截了当。它将只输出encoder_states。
代码片段6:编码器推断模型
请参考代码片段7 - 解码器模型更为精细。注意,我们为解码器隐藏状态和解码器cell状态创建单独的“输入”。这是因为我们要在每个时间步长(除了第一个时间步长 - 回想一下,我们在第一个时间步长只有编码器状态)都将这些状态输入进解码器,并且解码器推断模型是一个单独的独立模型。对于在翻译序列中生成的每个字符,编码器和解码器都将被递归调用。

代码片段7:解码器推断模型
请参考代码片段8 - 我们将编码器状态设置为states_val变量。在while循环内的第一次调用中,这些来自于编码器的隐藏状态和cell状态将被用来初始化decoder_model_inf,decoder_model_inf被作为输入直接提供给模型。一旦我们使用softmax来预测字符,我们现在输入这个预测的字符(使用target_seq三维数组作为预测字符的一个one-hot嵌入),和更新的state_val(从先面的解码器状态更新)来进行while循环的下一次迭代。注意,在每一次while循环,我们创建预测字符的一个one-hot嵌入之前,我们都要重置target_seq。
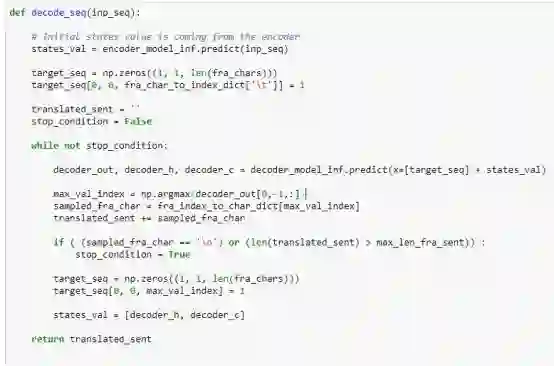
代码片段8:递归地调用解码器来预测翻译后的字符序列的函数
那么!现在我们有一个训练过的模型,可以把英文句子翻译成法语!下面是训练这个网络25个epoch后得到的结果。

图:使用一些样本训练数据获得的结果
如果你打算使用以上的架构图数据,请随意使用,并请在图片版权中提及我的名字。
如果从这篇文章你可以获得有用的信息,请为我点赞!
原文链接:
https://towardsdatascience.com/neural-machine-translation-using-seq2seq-with-keras-c23540453c74
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!





