网易互娱AI Lab视频动捕技术iCap被CVPR 2022接收!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
动作捕捉技术在影视和游戏行业已得到广泛的应用,其中最常用的技术方案是光学动作捕捉。光学动捕需要演员穿着紧身动捕服,并且在身上粘贴光学标记点,在配置好光学动捕设备的场地进行表演和动作录制。光学动捕设备通常价格不菲,同时还需要固定的室内场地,使用成本和门槛较高,很多小型动画工作室只能望而却步。如果可以从手机拍摄的视频中高精度地捕捉人物动作,那将是动画师的福音。
现在,动画师的福音,他来了,一起来看下面的视频,只需用手机人物动作,便可快速高质量地捕捉到人物的动作,得到骨骼动画数据。这些都是通过iCap——网易互娱AI Lab研发的一款产品级的视觉动作捕捉工具实现的。
相比于传统光学动作捕捉流程,iCap有以下优势:
1.快速产出:能够快速产出动作数据,更适用于敏捷开发,方便前期试错;
2.随时随地:只需光照条件足够让拍摄清晰,便可随时随地拍摄视频,产出结果;
3.节约人力,节约成本;
值得一提的是,iCap不仅支持身体关节数据捕捉,也支持手部数据捕捉。近日,网易互娱AI Lab已经将手部动作捕捉部分的算法进行了整理,目前已被CVPR 2022录取。

论文题目:Spatial-Temporal Parallel Transformer for Arm-Hand Dynamic Estimation
论文:https://arxiv.org/abs/2203.16202
现有的手部动作捕捉方法大部分是将手部信息和身体信息分开考虑的,即这些方案的输入是单纯的手部视觉信息。这样做的问题是,捕捉到的手部动作可能会和手臂动作存在不匹配,不协调的情况,在整合进全身动作捕捉数据时容易产生不合理的姿态。另外,现有的手部动作捕捉方法大多都只考虑了当前帧的信息,未能考虑帧间连续性,输出的动作容易出现抖动,也难以应对复杂的手部动作捕捉场景(模糊、遮挡等)。这些问题都导致现有方案比较难以推向实际应用。
为解决现有方案的痛点,网易互娱AI Lab提出了解决方案,该方案的主要贡献点如下:
1. 考虑到手臂动作和手部动作之间的相关性,设计模型同时预测手臂和手部动作;通过利用此相关性,输出的手臂和手部姿态会更加合理;
2. 通过两个transformer模型分别在时间和空间维度上提取相关性信息,使得手臂和手部的相关性能够更好地被利用,与此同时也能输出帧间连续的结果;另外,论文还定制了合适的目标函数以获得准确而稳定的输出序列;
方法介绍:
此项工作的目标是从视频中捕捉手臂和手的动作,具体地,此方案以骨骼旋转量来表示动作。实现上述目标最简单的思路是直接学习一个图像到骨骼旋转量的映射,但这就需要有能够和动作捕捉数据逐帧匹配图像数据(即和动作捕捉数据对齐的视频),这通常是难以获取的。作者认为,直接从图像输入中学习旋转量信息难度要大于从关键点输入中学习旋转量信息,因为前者缺少训练数据,后者则可以很方便地从动作捕捉数据中提取出(输出关键点,输出旋转量)数据对。基于上述分析,方案的整体框架主要包括了一个关键点预测模块和一个旋转量估计模块。
下图展示了iCap中手部动作捕捉算法的整体框架。
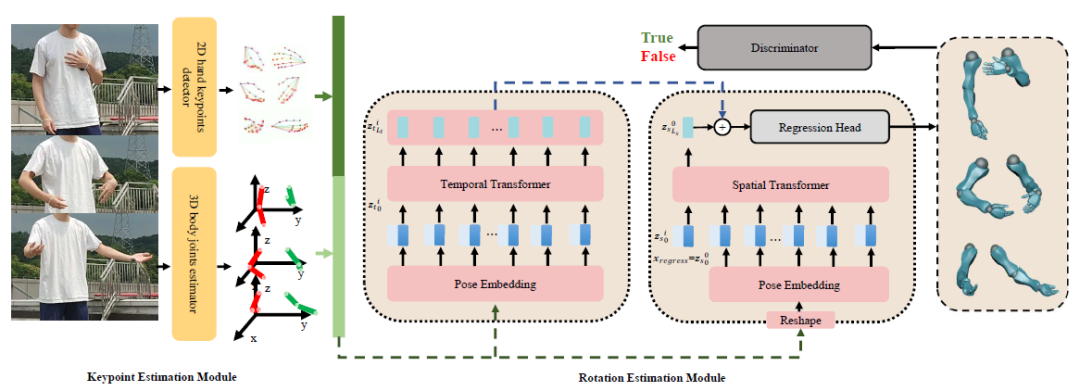
模型结构:
手部动作捕捉方案由两个模块组成,一个是关键点预测模块,另一个是旋转量预测模块。我们首先获取手部2D关键点以及手臂处的3D关键点,然后在基于这些关键点,设计了合适的模型用来估计旋转量。
关键点预测模块包含一个手部2D关键点定位模型和一个手臂3D关键点预测模型。手部2D关键点定位模型是基于MobileNetV3结构设计的,具体结构是基于one shot NAS搜索得出。手臂3D关键点则直接采用CVPR 2018的VPose3D预测全身3D姿态,再从中提取手臂关键点。
旋转量预测模块主要包含两个Transformer模型,一个是Temporal Transformer,一个是Spatial Transformer,整个模块称为Spatial-Temporal Parallel Arm-Hand Motion Transformer(PAHMT)。Temporal Transformer。Temporal Transformer的主要目标是提取手臂和手部动作的时序先验信息,以求输出帧间连续的动作数据。Spatial Transformer的主要目标是提取手臂姿态和手势姿态之间的全局相关性(挥动手臂往往和挥动手掌高度相关)以及不同关节点之间的局部相关性(譬如无名指的运动通常会带动中指和小拇指)。对于一段输入序列,将其Reshape成不同形状以作为两个Transformer的输入。不论是全局相关性还是局部相关性,他们在不同帧之间都应该保持一致,故论文受到ViT中的classification token的启发,设置了一个可学习的regression token,用来表征空间相关性特征。我们将Spatial Transformer输出的空间相关性特征和Temporal Transformer时序特征进行逐元素相加(element-wise adding)得到最后的特征,最后经过一个简单的回归网络得到最后的输出。
目标函数:
用来引导模型训练的目标函数主要包含两个部分,一部分是重建目标函数,一部分是对抗目标函数。
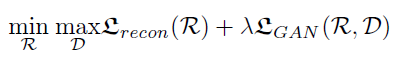
对抗目标函数的主要目的是引导模型输出具有“真实感”的手臂和手部动作。
重建目标函数是负责去学习骨骼旋转量的,主要由三个部分组成,L1 loss,FK loss和帧间平滑loss,
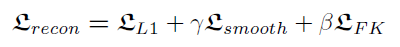
重建损失的基本目标是L1 loss。
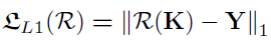
考虑到在以骨骼树的形式表示一个姿态的旋转量的时候,不同关节的重要程度是不一样的(父节点的旋转量会直接影响到子节点的位置,故同样的旋转误差作用于父子节点时,父节点带来的整体误差更大),论文引入了FK loss,即对输出旋转量通过FK函数计算得到关节点位置,用它与ground truth关节点位置计算loss。
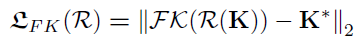
考虑到帧间连续性,论文还引入了帧间平滑loss。
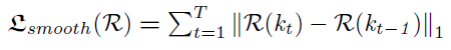
实验结果:
实验数据:由于缺少包含手部数据的开源动作捕捉数据集,作者收集了一套包含身体关节和手部动作的动作捕捉数据,数据包含500段动作,总计约20万帧。该动捕数据主要包含了一些舞蹈和体育动作,覆盖了很多肢体动作和手势。作者对该数据进行了划分(90%训练集,10%验证集),并在此动作捕捉数据集上训练模型并进行了消融实验对比。下图展示了该数据的样例。

另外,论文还通过动捕数据渲染得到了一批包含手部动作标签的视频数据,用来和state-of-the-art算法进行对比。下图展示了渲染数据集的样例。

评价指标:论文同时以MPJPE(Mean Per Joint Position Error)和MPJRE(Mean Per Joint Rotation Error)作为评价指标。
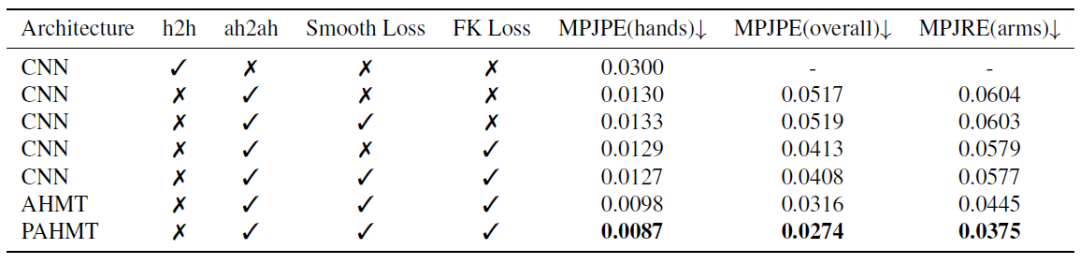
Baseline: 模型backbone为普通CNN,目标函数只包含对抗损失和L1 loss,输入输出和论文提出的方案一致,训练涉及的batch size,learning rate等信息均与消融实验中其他方法一致;
AHMT:只考虑Temporal Transformer的方案;
h2h和ah2ah:h2h表示输入手部关键点输出手部旋转量;ah2ah表示同时输入手臂和手臂关键点并同时输出手臂和手部旋转量。
下表展示了消融实验的结果。结果显示,通过利用帧间相关性信息,普通Temporal Transformer表现出显著优于CNN的性能。而通过引入Spatial Transformer来利用手臂姿态和手势姿态之间的全局相关性以及不同关节点之间的局部相关性之后,实验误差继续显著降低(MPJPE降低13%,MPJRE降低16%)。对于目标函数,可以看出单独引入FK loss能够降低实验误差,而单独引入帧间平滑损失则于误差降低无益,这是因为帧间平滑损失的主要目标是提高输出的帧间连续性。但值得注意的是,当FK loss和帧间平滑损失结合使用时,实验误差比单独使用任意一种都更低。综上所述,实验验证了论文提出的并行时空transformer结构以及目标函数的有效性。
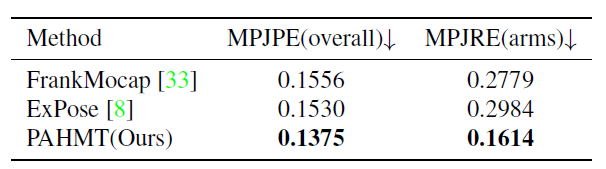
下表是论文方案和state-of-the-art算法(ExPose,FrankMocap)在渲染数据集上的实验结果,结果表明论文方案显著优于之前的state-of-the-art方法。
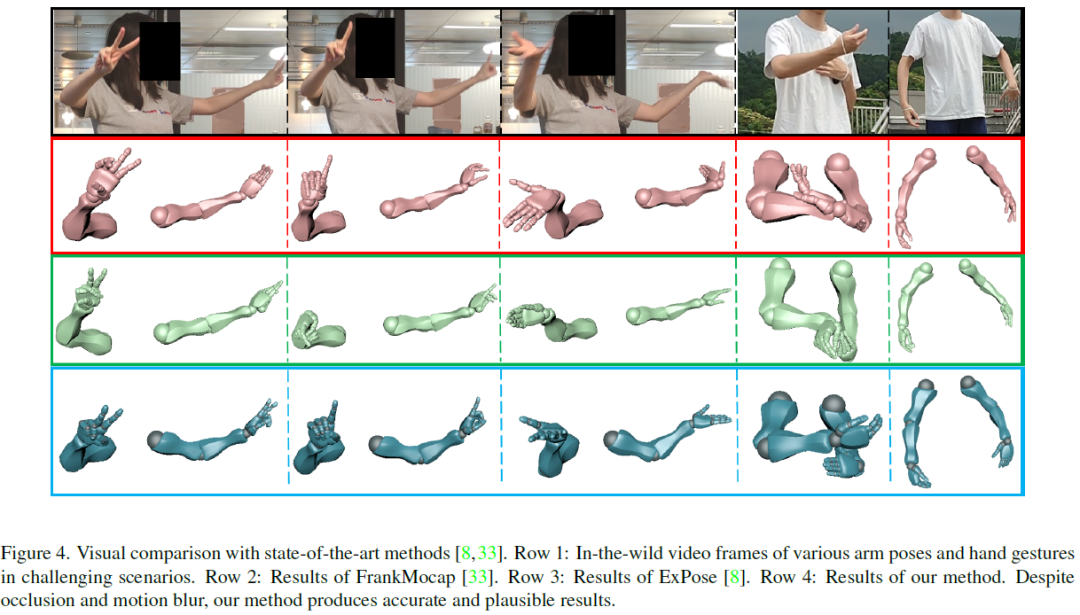
下图展示了论文方案和state-of-the-art算法的直观对比,第一行是一些包含识别难度较高的手部动作的视频帧,第二行是FrankMocap的结果,第三行是ExPose的结果,最后一行是论文方案的结果。不难看出论文方案表现出了明显更佳的准确性和鲁棒性。
总结:
网易互娱AI Lab提出了一套高效的手部动作捕捉算法,该算法在准确性和稳定性上都显著优于现有的方案。目前该算法已接入其视觉动作捕捉产品iCap中,并持续帮助多个游戏工作室进行动作资源辅助生产。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-Transformer或者目标检测 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer或者目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看







