CVPR 2022 | MLP才是无监督学习比监督学习迁移性能好的关键因素
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:王逸舟 | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/481881853
在这里和大家分享一下我们被CVPR 2022录用的工作" Revisiting the Transferability of Supervised Pretraining: an MLP Perspective"。

Revisiting the Transferability of Supervised Pretraining: an MLP Perspective
论文:https://arxiv.org/abs/2112.00496
单位:浙江大学,悉尼大学,商汤,上海交大清源研究院
开篇定性,作为一篇学术宣传稿,不需要受制于固定的格式,因此我们希望和大家讨论的更加自由放飞一些,分享有趣的现象和背后的洞见(insight),而不是简单的堆砌各种实验结果和”由此可得”。
迁移能力(transferability)的定义很简单,模型在相同数据下,如何在各种下游任务表现的更好。形象的来说,就是门派内有着大量的弟子(pretraining methods),基于门派内共同的修炼资源(pretraining data),修炼着不同的功法(with different supervision),以期让自己在未来在不同类型的江湖比武(various downstream tasks, various dataset)上都能拔得头筹。而我们想要讲述的是,一个资质平凡的监督学习(supervised learning method,SL),修着最普通的功法(the cross-entropy loss),通过“自我审视”(revisit)和取长补短,总结经验教训(theoretical analysis),在各种迁移任务上成功击败早已声名鹊起的后起之秀(unsupervised learning methods, USL),最终脱颖而出的故事。
相比于之前的对监督学习和无监督学习的分析,这次针对迁移性能的revisit,从监督学习和无监督学习在训练时结构上的差异出发,指出了之前被大家忽视的MLP projector是其中的关键因素。
我们从“回看监督学习/无监督学习的差距分析”,“新视角下的监督学习/无监督学习迁移能力差距”,“SL-MLP: MLP带来的有趣现象”,“对实验现象的理论分析”,“SL-MLP的迁移性能”五个章节,讲一下如何挖掘监督学习的迁移能力,以及怎样的特征才更适应下游任务。
回看监督学习/无监督学习的差距分析
首先,明确我们的目标:找到监督学习(SL)在迁移能力上真正劣于无监督学习(USL)的原因。只有找到监督学习真正的短板,才能针对性补强,从而完成逆袭。
围绕这一目标,现有的分析和实践性质的文章,主要从两个角度出发:(1)无监督放弃了标签中的语义信息[1,2],避免模型在训练过程中对标签的过拟合,从而更好保留了instance-specific的特征,使其对下游任务的适应性更好。(2)Contrastive loss的设计让模型学到了对下游任务更友好的中低层的特征[3,4]。
但是,监督学习方案和现有无监督学习方案在结构上的不同,却一直被大家忽视。从SimCLR[5]开始,在encoder后引入一个multi-layer perceptron(MLP) projector的方案,就被无监督学习广泛的用于提升当前数据集的表征能力。MLP带来的提升是那么的简单有效,以至于我们当前在设计对比式的无监督学习方案时,都会默认的加入MLP。从而导致在对监督学习和无监督学习迁移性比较上出现了结构上的unfair,得到了不够准确的结论。比如,在提升监督学习迁移能力的方案中,SupContrast[4]在把contrastive loss引入监督学习的同时,MLP projector也被一并引入,但在[3]的进一步分析比较中,却单一地把性能提升归功于contrastive loss设计上的优势。
而实际上,通过这次的revist,我们发现之前被大家忽视的MLP projector才是其中的关键因素。
新视角下的监督学习/无监督学习迁移能力差距
找到了一个新的视角后,要做的自然是用实验验证这个视角观察的可信度。具体来说,就是要首先从模型结构的视角上凸显出监督学习与无监督学习的迁移能力差距。
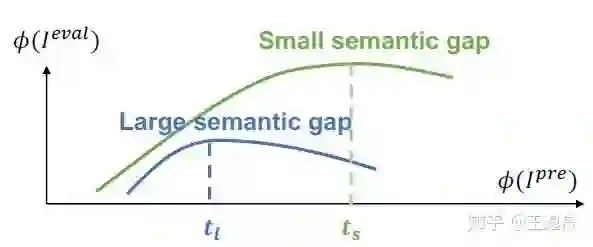
Concept generalization task[6]给我们提供了一个值得参考的方案,并指出各种模型之间的迁移性差异随着pretraining dataset和evaluation dataset之间的语义差距(semantic gap)。而ImageNet作为一个包含多种语义的分类数据集,能被划分成语义差距较大的两类——652类(主要是生物类)的预训练集(pre-D),以及358类(工具类)的测试集(eval-D)。让所有的模型都在pre-D上预训练,再在eval-D上进行linear eval从而体现各种方案间的transferability gap。
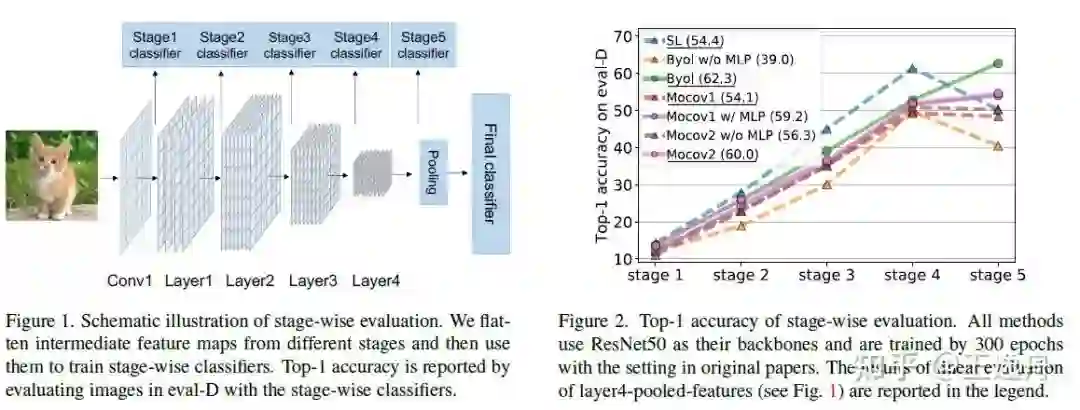
既然我们从一个结构差异(MLP)的视角出发,我们自然就需要按照encoder层级结构的划分,做一个stage-wise的测试。Stage-wise evaluation的结果是出乎意料的:
(1) 监督学习(SL)在前4个stage有着比无监督学习(BYOL,MoCov1,MoCOv2)更高的迁移能力,说明标签中的语义信息能够增益中底层特征的迁移能力;
(2) BYOL和MoCov2在stage4到5保持了迁移能力的提升,而SL和MoCov1则出现了性能的下降,而这两组实验中一个关键的差异就是:BYOL和MoCov2在stage5之后插入了一个只用于预训练的MLP层,而SL和MoCov1没有;
(3) 对MoCov1、MoCov2、BYOL分别进行with/without MLP的ablation后,发现在无监督方案上增加MLP能提升其迁移性能,并避免出现类似MoCov1的stage4到5的迁移能力下降。
说句题外话,实际上可能存在一些其他的非线性结构同样能增加迁移性能,但仅仅从MLP projector的角度出发,也能给我们带来更多有趣的结论。
SL-MLP: MLP带来的有趣现象
把竞争对手无监督学习在迁移能力上的情况剖析的差不多了,下一步自然就是修炼学到的知识。具体来说,参照无监督学习常用的做法,在预训练时,我们在SL的encoder和分类层之间加入了一个MLP,并在迁移到下游任务时丢弃掉,仅使用encoder进行迁移。
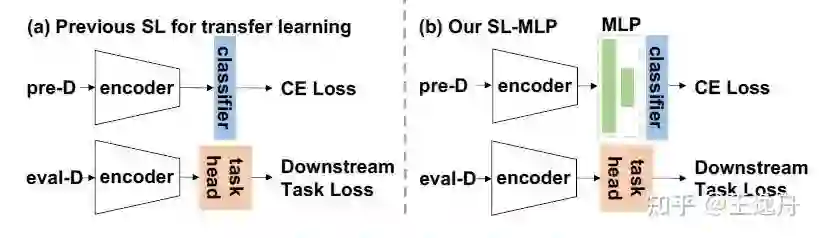

这种简单的设计带来了十分有效且有趣的现象。
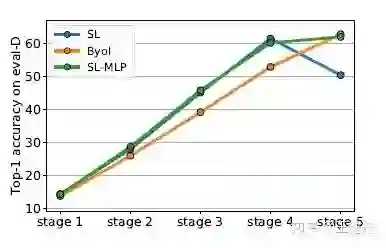
现象1. SL-MLP避免了监督学习(SL)在stage4-5上的迁移能力下降。
用从无监督学习那偷师来的MLP修炼自身后,监督学习(SL)成功弥补了自己在stage-wise eval上的最大劣势,让stage5的存在真正对下游任务有了增益。
现象2. MLP增大了预训练模型的intra-class variation。
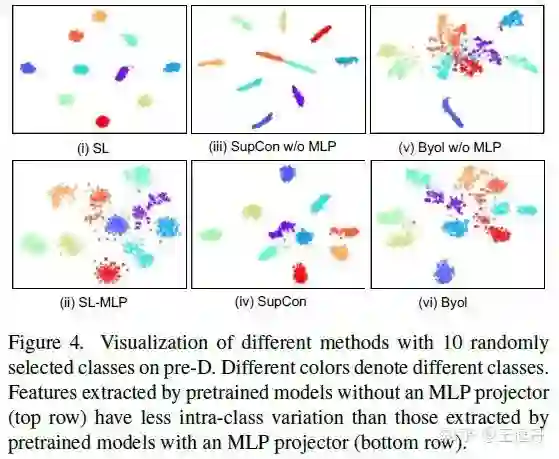
所谓修炼,只有不在单一方面过度拘于小节,才能适应广泛的任务要求。不是一味专注在减小intra-class variation,才能让模型保留更丰富的特征。

现象3. MLP拉近了pre-D和eval-D特征分布间的距离
所谓修炼,除了与他人竞争水平高低,更重要的在于内心对万事万物的理解是否有所精进。测试精度只能说明方法的最终结果,而学习到的特征分布,才真正代表了增加了MLP后的监督学习,对语义的表征做出了哪些改变。
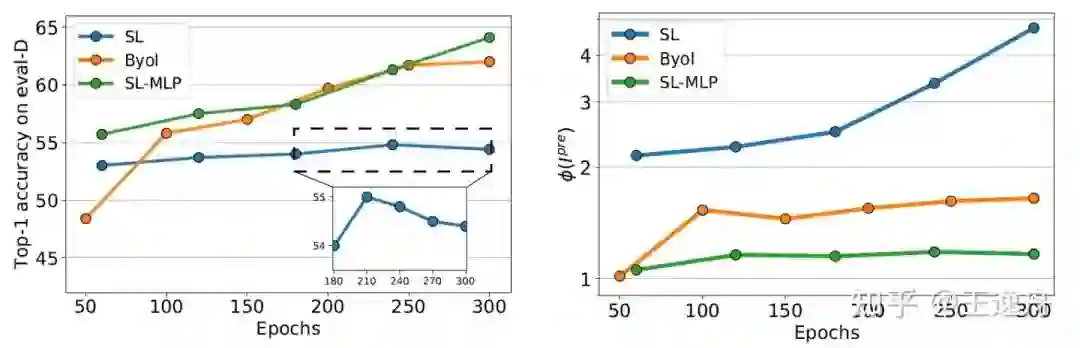
根据Jennifer Wortma对于domain adaption的分析[8],拉近预训练域pre-D和迁移域eval-D特征分布间的距离对于针对迁移域eval-D的迁移学习是有帮助的。我们用蓝色系和橙色系代表可视化预训练域pre-D和迁移域eval-D上不同类别。SL的预训练域pre-D特征彼此分散,且与迁移域eval-D的特征产生较大的距离。相对的,SL-MLP和BYOL在保持了预训练域pre-D特征可分的基础上,预训练域pre-D和迁移域eval-D的特征在特征空间中混合的更好。

直觉上来说,我们可以用特征在pre-D和eval-D之间的混合程度Feature mixtureness(两个set中不同类中心周围topk中同set的比例),来定量计算pre-D和eval-D特征分布间的距离:
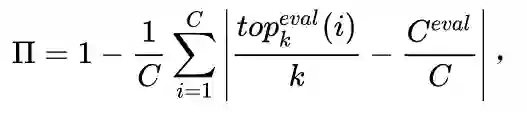
虽然SL,SL-MLP,BYOL在开始时的Feature mixtureness都较高,随着训练的进行,SL专注在预训练域pre-D上的表征,预训练域pre-D和迁移域eval-D特征分布间的距离开始拉远,而SL-MLP和BYOL的预训练域pre-D和迁移域eval-D特征分布间的距离则一直保持在一个很高的状态。自然,SL-MLP和BYOL就更容易适应新的迁移数据集。
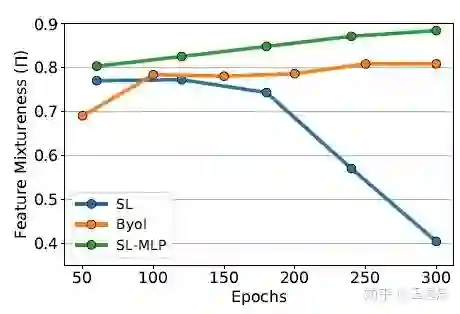
现象4. MLP能减低特征冗余
所谓修炼,就是去除内部的芜杂。对于模型来说,则是特征通道间的冗余度,避免重复受限于当前的任务。
在Barlow Twins[9]中提到,特征通道间的高冗余会限制特征的表征能力,我们用Resnet50输出的2048-d特征维度间的Pearson相关度来衡量特征冗余。SL-MLP,BYOL以及MoCov1 w/ MLP,相比他们对应的无MLP变体,有更高的迁移性能与更小的特征冗余度,说明了MLP能减低特征冗余。
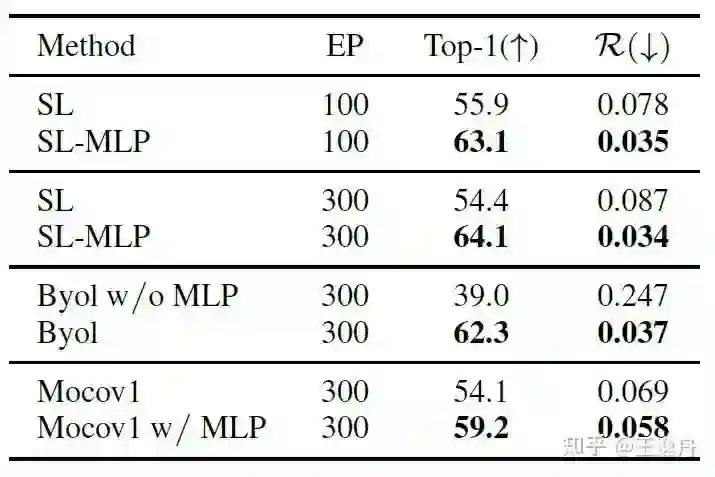
对实验现象的理论分析
在发现了这些有趣的观察之后,我们当然需要对所学到的经验进行一次归纳总结,通过理论分析提炼出成功的关键,为我们研究下一门针对transferability的功法打好基础。

用数学的语言来说:

上述理论说明了 ,
(1) 当我们在pre-D上一直优化其辨别能力直到超过一个固定的阈值t之后,进一步优化pre-D会导致模型在eval-D上的迁移能力下降,
(2)当pre-D和eval-D之间的语义差距更大时(此时,在相同的模型下两者的特征分布距离容易更大),t会更小。
那么在应对transfer learning时,
(1)在设计模型结构或者优化函数时,为了更好的迁移能力,我们不能把模型在预训练集的intra-class variation优化的过小,导致模型对于预训练集的overfit。(可以考虑增加MLP来完成)
(2)当被迁移域eval-D和预训练域pre-D的语义差距(semantic gap)更大时,我们需要保留更大的intra-class variation来做应对。
SL-MLP的迁移性能
学成归来,自当从容应对各种挑战,不卑不亢,一鸣惊人。
我们在concept generalization task任务上验证了SL-MLP对多个模型结构的效果。SL-MLP对SL有明显的提升,甚至在相同epoch数下超过了BYOL的迁移性能。同样的,MLP在Swin-ViT上也有一样的效果。在Swin-ViT上的提升较低主要是因为不加MLP的Swin-ViT已经有了和SL-MLP类似的高混合程度(Feature mixtureness)。
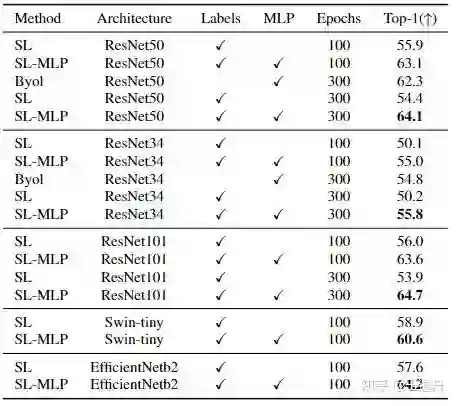
我们在cross domain的其他分类数据集上验证了MLP对于SL-MLP和SupContrast的重要性。在linear eval,finetune和few-shot learning任务上,增加MLP都表现出了提升,说明MLP相比于contrastive loss对于有监督的迁移能力提升更加重要。
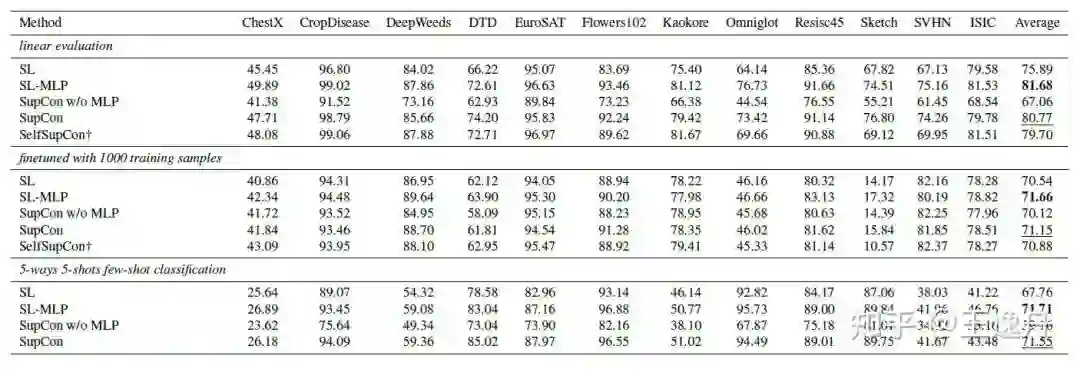
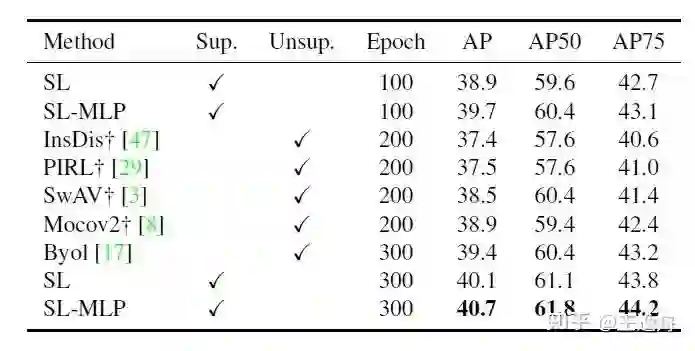
SL-MLP在检测任务上也能观察到性能的提升。SL-MLP在较少epoch下的性能甚至超过了用更多epoch的无监督方案。
尾声
至此,监督学习通过研究自身与无监督学习之间存在的结构差异,成功掌握了一项提升transferability的关键因素(MLP),用SL-MLP证明了自身有取得与无监督相似或更好的结果的实力。但是,未来的道路还在不断延伸,其他有效简单的非线性模块,亦或是把knowledage直接化用到supervision里,修炼的道路没有尽头。
参考文献
Nanxuan Zhao, Zhirong Wu, Rynson WH Lau, and Stephen Lin. What makes instance discrimination good for transfer learning? arXiv preprint arXiv:2006.06606, 2020.
Linus Ericsson, Henry Gouk, and Timothy M Hospedales. How well do self-supervised models transfer? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5414–5423, 2021
Ashraful Islam, Chun-Fu Chen, Rameswar Panda, Leonid Karlinsky, Richard Radke, and Rogerio Feris. A broad study on the transferability of visual representations with contrastive learning. arXiv preprint arXiv:2103.13517, 2021.
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. arXiv preprint arXiv:2004.11362, 2020.
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020
Mert Bulent Sariyildiz, Yannis Kalantidis, Diane Larlus, and Karteek Alahari. Concept generalization in visual representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9629–9639, 2021
John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman. Learning bounds for domain adaptation. Advances in Neural Information Processing Systems, 20:129–136, 2007
Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and St´ephane Deny. Barlow twins: Self-supervised learning via redundancy reduction. arXiv preprint arXiv:2103.03230, 2021.
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看