CVPR 2022 | 商汤/上交/港中文提出U2PL:使用不可靠伪标签的半监督语义分割
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:Pascal | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/474771549
论文概况

论文标题:Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
作者信息:商汤科技, 上海交通大学, 香港中文大学
录用信息:CVPR 2022
论文:https://arxiv.org/abs/2203.03884
代码刚刚开源:
https://github.com/Haochen-Wang409/U2PL
Project Page:
https://haochen-wang409.github.io/U2PL/
今天介绍我们在半监督语义分割(Semi-Supervised Semantic Segmentation)领域的一篇原创工作 U2PL (Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels)。
半监督任务的关键在于充分利用无标签数据,我们基于「 Every Pixel Matters」的理念,有效利用了包括不可靠样本在内的全部无标签数据,大幅提升了算法精度。目前 U2PL 已被 CVPR 2022 接收,相关代码已开源,有任何问题欢迎在 GitHub 提出。
Self-training: 样本筛选导致训练不充分
半监督学习的核心问题在于有效利用无标注样本,作为有标签样本的补充,以提升模型性能。
经典的 self-training 方法大多遵循着 supervised learning → pseudo labeling → re-training 的基本流程,但学生网络会从不正确的伪标签中学习到错误的信息,因而存在 performance degradation 的问题。
常规作法是通过样本筛选的方式只留下高置信度预测结果,但这会将大量的无标签数据排除在训练过程外,导致模型训练不充分。此外,如果模型不能较好地预测某些 hard class,那么就很难为该类别的无标签像素分配准确的伪标签,从而进入恶性循环。
我们认为「 Every Pixel Matters」,即使是低质量伪标签也应当被合理利用,过往的方法并没有充分挖掘它们的价值。
Motivation: Every Pixel Matters
具体来说,预测结果的可靠与否,我们可以通过熵 (per-pixel entropy) 来衡量,低熵表示预测结果可靠,高熵表示预测结果不可靠。我们通过 Figure 2 来观察一个具体的例子,Figure 2(a) 是一张蒙有 entropy map 的无标签图片,高熵的不可靠像素很难被打上一个确定的伪标签,因此不参与到 re-training 过程,在 FIgure 2(b) 中我们以白色表示。
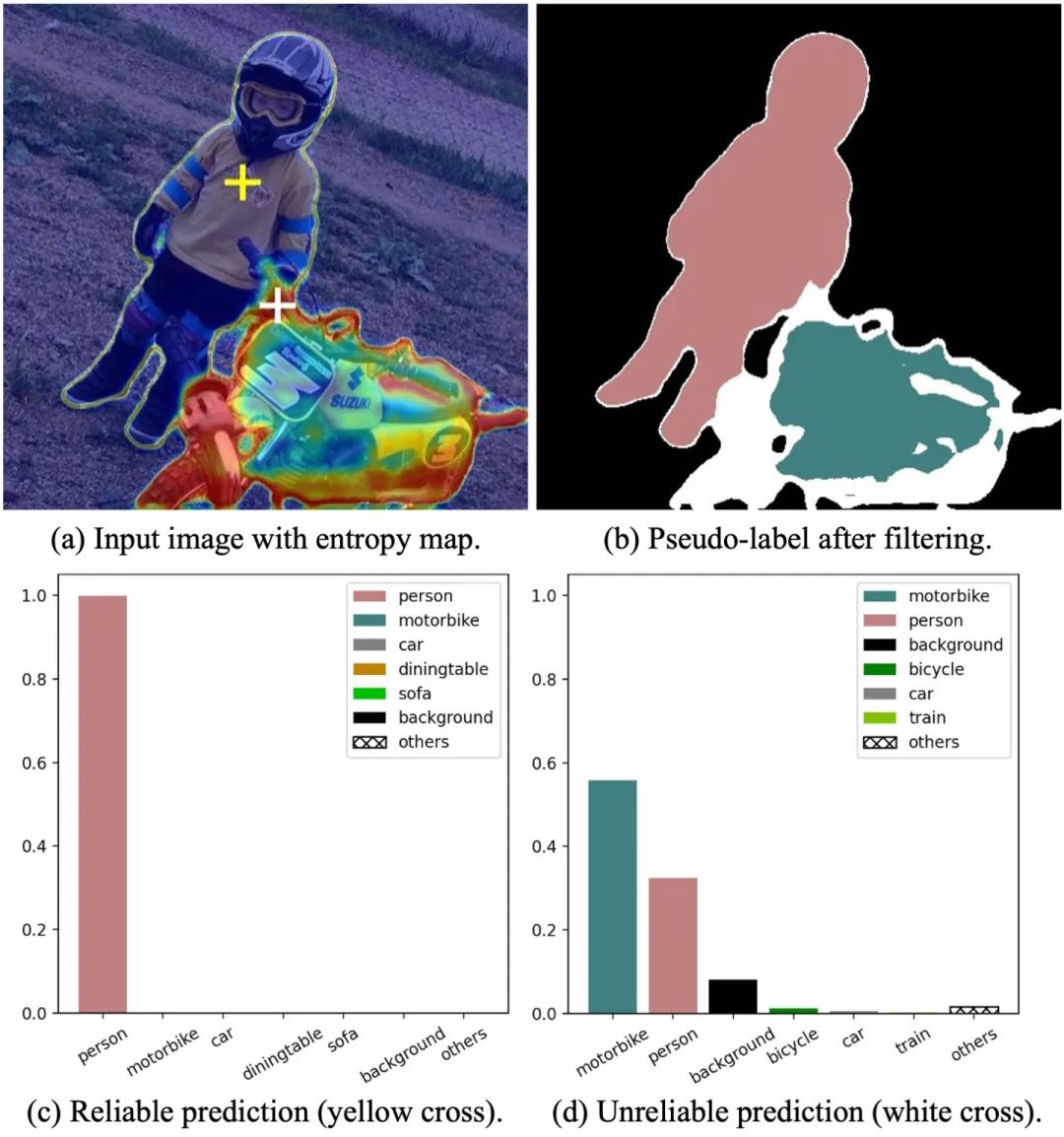
我们分别选择了一个可靠的和不可靠的预测结果,在 Figure 2(c) 和 Figure 2(d) 中将它们的 category-wise probability 以柱状图的形式画出。黄色十字叉所表示的像素在 person 类上的预测概率接近于 1,对于这个预测结果模型非常确信,低熵的该像素点是典型的 reliable prediction。而白色十字叉所表示的像素点在 motorbike 和 person 两个类别上都具有不低的预测概率且在数值上较为接近,模型无法给出一个确定的预测结果,符合我们定义的 unralibale prediction。对于白色十字叉所表示的像素点,虽然模型并不确信它具体属于哪一个类别,但模型在 car 和 train 这两个类别上表现出极低的预测概率,显然很确信不属于这些类别。
因而,我们想到即使是不可靠的预测结果,虽然无法打上确定的伪标签,但仍可以作为部分类别的负样本,从而参与到模型的训练,从而让所有的无标签样本都能在训练过程中发挥作用。
Method
Overview

网络结构上,U2PL 采用 self-training 技术路线中常见的 momentum teahcer 结构,由 teacher 和 student 两个结构完全相同的网络组成,teacher 通过 EMA 的形式接受来自 student 的参数更新。单个网络的具体组成主要参考的是 ReCo (ICLR'22)[1],包括三个部分: encoder h, decoder f, 表征头 g。
损失函数优化上,有标签数据直接基于标准的交叉熵损失函数Ls 进行优化。无标签数据则先靠 teacher 给出预测结果,然后根据 pixel-level entropy 将预测结果分成 reliable pixels 和 unreliable pixels 两大部分 (分流的过程在 Figure 2 有所体现), 最后分别基于 Lu 和Lc进行优化。

如上三个部分构成了 U2PL 全部的损失函数,熟悉 self-training 的话就只需要关注对比学习 Lc部分,是经典的 InfoNCE Loss[2],细节会在后续具体讨论。
Pseudo-Labeling
本节主要探讨无标签样本中可靠预测结果的利用方式,即损失函数中的 Lu部分

随着训练过程的推进,我们认为模型的性能在不断攀升,不可靠预测结果的比例相适应地也在不断下降,因此在不同的训练时刻我们对可靠部分的定义是不断变化的,这里我们简单采用了线性变化策略,并未作过多探索
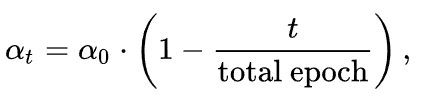
需要注意的是,由于并非所有的无标签像素都会参与这部分的计算,因此需要计算一个权重对这部分损失进行调节。
Using Unreliable Pseudo-Labes
本节主要探讨无标签样本中不可靠预测结果的利用方式,即损失函数中的 Lc 部分。
U2PL 以对比学习为例介绍了如何将不可靠伪标签用于提升模型精度。既然是对比学习,那不可避免的问题就是讨论如何构建正负样本对。接下来的有关对比学习内容的实现细节大量参考了 ReCo[1],因此如果要深入了解 U2PL,建议可以先看下这篇论文。
首先是 anchor pixels (queries) ,我们会给训练过程中出现在 mini-batch 中的每一个类别都采样一系列的 anchor pixel 用于对比学习。
然后是构建 anchor pixel 的 positive sample,我们会给每一个类别都算一个特征中心,同一类的 anchor pixel 会 share 共同的特征中心作为 postive sample。具体地,我们先从 mini-batch 分类别筛选出可用于计算特征中心的像素点,对于有标签样本和无标签样本,筛选的标准是一致的,就是该样本在真值标签类别或伪标签类别上的预测概率大于一个阈值,对筛选出来的像素点的表征的集合 Ac 求一个均值作为各类别的特征中心 zc+ ,这里可以参见如下公式

最后是构建 anchor pixel 的 negative sampe,同样的也需要分成有标签样本和无标签样本两个部分去讨论。对于有标签样本,我们明确知道其所属的类别,因此除真值标签外的所有类别都可以作为该像素的负样本类别;而对于无标签样本,由于伪标签可能存在错误,因此我们并不完全却行确信标签的正确性,因而我们需要将预测概率最高的几个类别过滤掉,将该像素认作为剩下几个类别的负样本。这部分对应的是论文中公式 13-16,但说实话这一段内容用公式去描述还是比较晦涩的。

由于数据集中存在长尾问题,如果只使用一个 batch 的样本作为对比学习的负样本可能会非常受限,因此我们采用 MemoryBank 来维护一个类别相关的负样本库,存入的是由 teacher 生成的断梯度特征,以先进先出的队列结构维护。
Comparison with Existing Alternatives
本文所有的实验结果均是基于 ResNet-101 + Deeplab v3+ 的网络结构完成的,所采用的的数据集构成和评估方式请参见论文描述。
我们在 Classic VOC, Blender VOC, Cityscapes 三种数据集上均和现存方法进行了对比,在全部两个 PASCAL VOC 数据集上我们均取得了最佳精度。在 Cityscapes 数据集上,由于我们没能很好地解决长尾问题,落后于致力解决类别不平衡问题的 AEL (NeurIPS'21)[3],但我们将 U2PL 叠加在 AEL 上能够取得超越 AEL 的精度,也侧面证明了 U2PL 的通用性。值得一提的是,U2PL 在有标签数据较少的划分下,精度表现尤为优异。



Ablation Studies
Effectiveness of Using Unreliable Pseudo-Labels
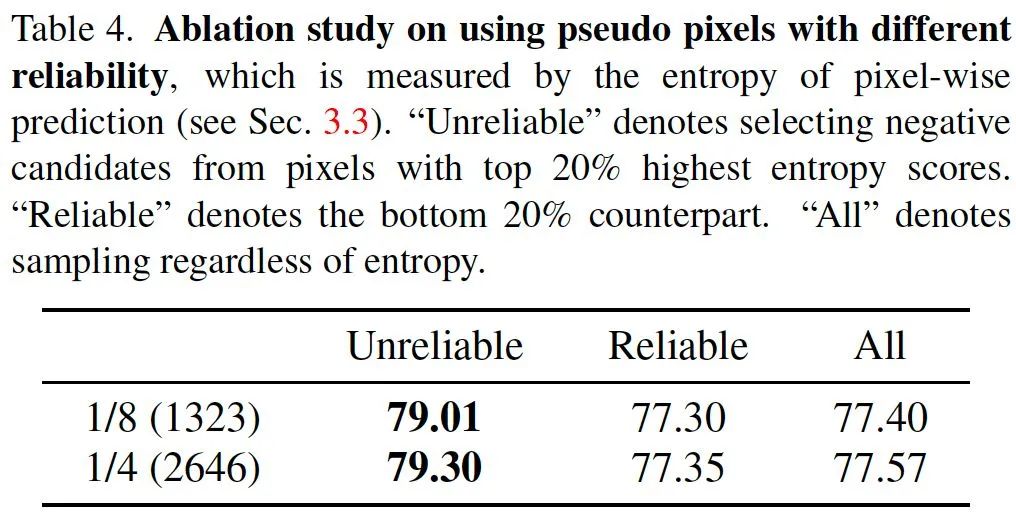

我们在 PSACAL VOC 和 CItyscapes 等多个数据集的多个划分上验证了使用不可靠伪标签的价值。
Alternative of Contrastive Learning

我们增加了通过二分类去利用不可靠样本的对比实验,证明利用低质量伪标签并不是只能通过对比学习去实现,只要利用好低质量样本,即使是二分类方法也能取得不错的精度提升。
附录
U2PL 与 negative learning 的区别
这里需要着重强调下我们的工作和 negative learning 的区别, negative learning 选用的负样本依旧是高置信度的可靠样本[4],相比之下我们则提倡充分利用不可靠样本而不是把它们过滤掉。
比如说预测结果 p =[0.3, 0.3, 0.2, 0.1, 0.1]T由于其不确定性会被 negative learning 方法丢弃,但在 U2PL 中却可以被作为多个 unlikely class 的负样本,实验结果也发现 negative learning 方法的精度不如 U2PL。
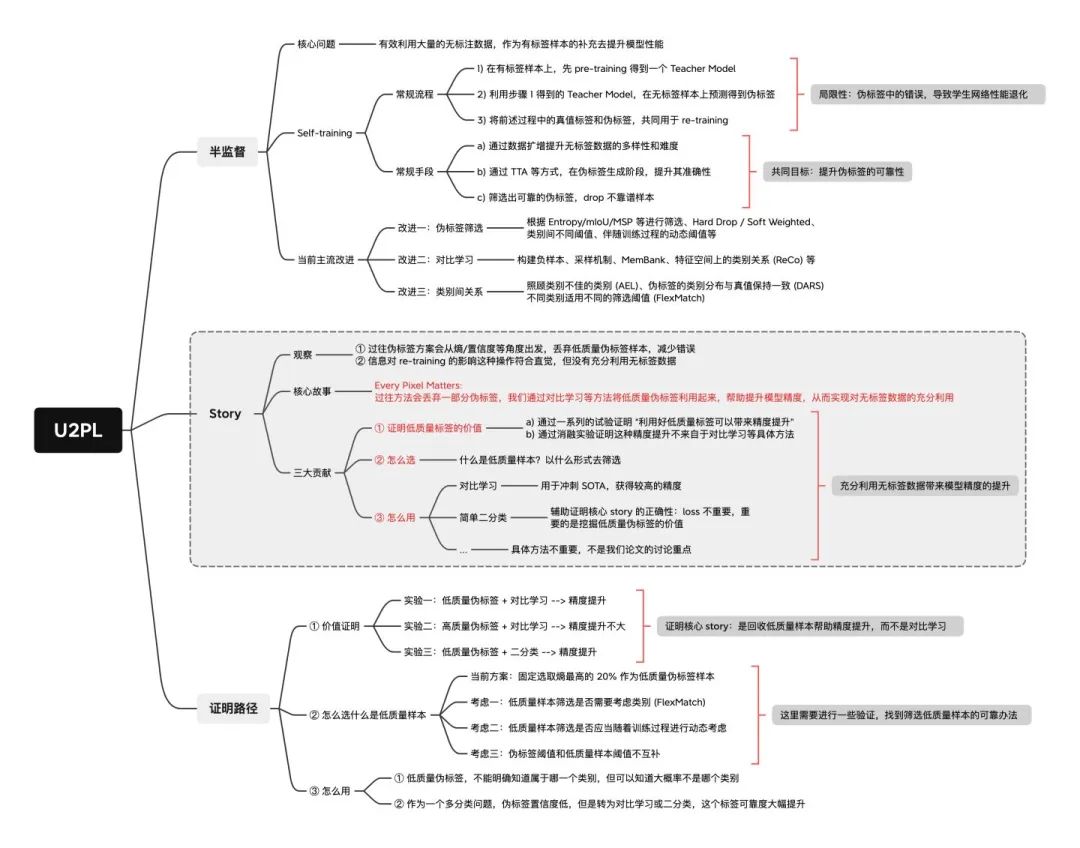
U2PL 技术蓝图
这里贴出技术蓝图,便于大家更好地理解论文的核心 story 和实验设计
参考
^ab[2104.04465] Bootstrapping Semantic Segmentation with Regional Contrast https://arxiv.org/abs/2104.04465
^[1807.03748] Representation Learning with Contrastive Predictive Coding https://arxiv.org/abs/1807.03748
^[2110.05474] Semi-Supervised Semantic Segmentation via Adaptive Equalization Learning https://arxiv.org/abs/2110.05474
^In Defense of Pseudo-Labeling: An Uncertainty-Aware Pseudo-label Selection Framework for Semi-Supervised Learning https://openreview.net/pdf/c979bcaed90f2b14dbf27b5e90fdbb74407f161b.pdf
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-图像分割交流群成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看


