团队新作 | AAAI2021自动化所入选论文速览(二)


09
基于三维网络重建和局部注意力的手势识别
Group-Wise Semantic Mining for Weakly Supervised Semantic Segmentation
手势识别技术具有广泛的应用场景,比如实时地人机交互,虚拟VR技术以及手语识别等。然而,由于背景噪声等与手势无关因素的影响,精确地识别出每个手势的含义往往存在很大的挑战。因此,将网络的注意力集中在人体的手部和手臂区域是非常重要的。同时,与动作识别不同,手势识别重在提取局部区域的特征而无需考虑全局,而且手势往往是一些连续的微小动作,并不涉及大范围的动作,这也是在设计网络结构时需要考虑的方面。
针对上述问题,我们提出了一种基于时空注意力机制和网络局部结构重组的3D卷积神经网络架构,称为RAAR3D网络。
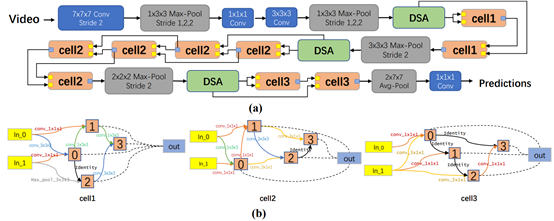
图1. RAAR3D网络结构图
RAAR3D网络包含级联的时空注意力模块DSA和重组的不同结构单元cell1, cell2和cell3。DSA模块包含时间域注意力机制和空间域注意力机制。其中时间域注意力机制主要是捕获手部和手臂的运动信息,而空间域注意力机制则捕获他们的位置信息。捕获的不同域特征最后串联并通过残差结构进行融合。
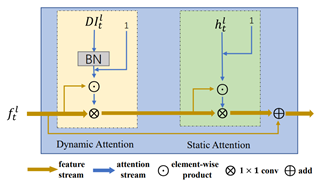
图2. 时空注意力模块(DSA)
结构单元cell1, cell2和cell3基于NAS进行重建,它们对流过不同网络层的特征具有很强的自适应能力,能够在网络的不同深度自适应地捕获强表征信息。
该方法在手势数据库上取得了当前最好的结果。
Benjia Zhou , Yunan Li and Jun Wan: Regional Attention with Architecture-Rebuilt 3D Network for RGB-D Gesture Recognition. The Thirty-Fifth AAAI Conference on Artificial Intelligence(AAAI) 2021
01
基于状态影响力模型的探索方法
Exploration via State Influence Modeling
奖励环境下的复杂探索任务是极具挑战性的研究课题。本文关注稀疏奖励环境中探索问题的第一个阶段——无奖励探索阶段。在传统的方法中,比如基于计数的方法(count-based)、基于好奇心(curiosity)的方法等,在这一阶段的表现并不令人满意,因为这些算法只关注单个状态自身的性质,而忽略了状态之间的影响。
本文指出,只用状态自身的属性来设计内部奖励,不足以指导智能体完成无奖励阶段的探索任务。状态之间的关系应该作为内部奖励的一个新的部分被引入。根据社会影响力中对个体的影响力的定义和判断方法,我们为强化学习中的智能体设计了相似的度量方法,该方法同时考虑了对状态自身的评价和状态之间关联关系的评价。
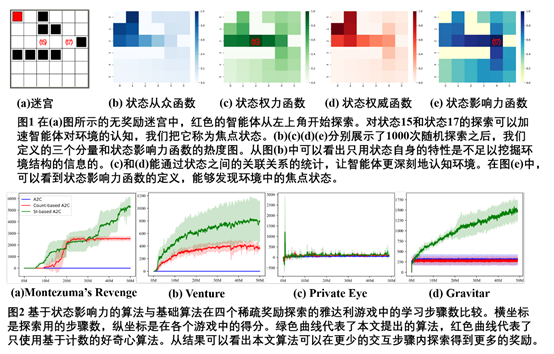
在强化学习的探索任务中,我们把遇到的每一个状态看作一个个体,把它的访问特征看作意见。通过对状态影响力(state influence)的度量(包括三个部分,从众性(conformity), 权力(power),和权威(authority)),智能体能够在没有奖励的情况下,尽快找到已经见过的状态中哪些是焦点状态,通过对焦点状态的进一步探索来提升对当前局部环境的认知能力。其中,从众性函数度量一个状态被访问的频率;状态权力函数定义为多少个状态必须通过与当前状态的信息交换来达到最终目标,它度量了状态之间的关系,可以看作是一个局部探索环境的结构;状态权威函数定义为一个状态的缺席对其他状态的影响,它衡量的是状态之间的另一种关系,表明一个特定状态可以达到多少个未来状态。
基于对状态影响力的定义,我们设计了应用Q-Learning和A2C的通用强化学习框架。并应用到迷宫格与雅达利游戏等带有稀疏奖励信号的复杂探索任务中,得到了比只用状态自身信息设计内部奖励的相关方法更好的效果。
Yongxin Kang, Enmin Zhao, Kai Li, Junliang Xing :Exploration via State Influence Modeling. The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI) 2021
02
基于模型的强化学习中针对生成样本的可学习的重加权方法
Learning to Reweight Imaginary Transitions for Model-‐Based Reinforcement Learning
基于模型的强化学习方法通常先学习一个动力学模型(Dynamics Model)来模拟环境,再使用该模型来生成虚拟数据用于训练策略或在线规划,因而相较于无模型的强化学习方法有着更高的采样效率。然而,基于模型的方法往往受限于动力学模型的预测精度。先前的研究工作通常考虑人工地调整动力学模型的使用范畴来抑制模型误差对训练过程的影响,但这类固定的方案无法在训练过程中自适应地进行调整。
我们的工作考虑,根据每个生成样本对训练过程的影响来调整权重,从而,在抑制模型误差对训练过程的负影响的同时,最大化地利用生成样本。我们构建以下流程来调整权重:针对每个生成样本,首先,使用它来更新价值和策略网络;然后,在真实数据上计算神经网络更新前后损失值的变化;最后,根据损失值的变化调整该样本的权重。为了高效地实现这一权重调节机制,我们构建了一个权重预测网络,并按照上述流程对该网络进行训练:使用权重预测网络对一批生成样本进行权重预测,使用加权后的样本更新价值和策略网络,以更新前后损失值的变化作为优化目标,按照链式法则计算梯度并更新权重预测网络。
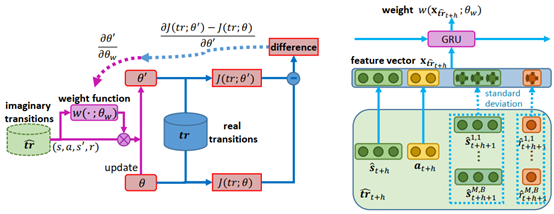
图. 整体框架:权重函数的训练过程(左),权重函数的网络结构(右)
Wenzhen Huang, Qiyue Yin, Junge Zhang, KAIQI HUANG :Learning to Reweight Imaginary Transitions for Model-‐Based Reinforcement Learning. The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI) 2021
03
深度合作网络:用于类增量学习的生成与判别合作模型
DeepCollaboration: Collaborative Generative and Discriminative Models for Class Incremental Learning
在增量式类别学习中,系统需要在学习新类别的同时保留对于旧类别的识别能力。保留部分旧类别的样本,与新类别的样本共同训练是一种重要的解决方案。但是这一策略需要不断增长的样本存贮空间。训练一个生成模型,用于生成,而不是保留旧类别的样本,可以克服存贮能力的局限。但在不断生成更多类别样本的过程中,不同类别的生成图片之间可能存在较大的分布重叠,并且随着生成误差的累积,生成样本与真实样本的分布差距不断加大,最终削弱了判别器的类别辨识能力。
我们提出了一种新的深度生成与判别合作模型,来解决增量式类别学习中这一问题。该方法给出了能将生成模型和判别模型整合为一体的共同优化目标,使得判别模型能为生成模型提供显式的隐变量分布,同时生成模型能够为判别模型提供可保持分类间隔的伪样本。该模型通过双向训练与对抗学习,能够解决生成样本和真实样本的分布不匹配问题。加上有针对性的样本筛选机制,最终在增量式类别学习任务上取得了较好的效果,显著优于基线生成模型,克服了样本存贮瓶颈,并取得了与保留旧类别样本的方法相当的性能。
Speech & Natural Language Processing
01
基于对偶问答的半监督事件元素抽取
What the Role Is vs. What Plays the Role: Semi-Supervised Event Argument Extraction via Dual Question Answering
事件元素抽取旨在从非结构化文本中抽取出结构化的事件元素知识(例如:事件的发生时间、发生地点、参与者等)。传统方法将事件元素抽取建模为分类任务或者序列标注任务。尽管此类有监督学习方法取得了不错的性能,但是仍然存在如下问题:
1)忽略了事件元素扮演角色的语义信息,缺乏不同元素之间的参数共享。
2)在训练样本充足的类别上性能较高,但是在小样本类别上性能较低,无法处理零样本的类别。
针对上述问题,我们提出了一种基于对偶问答的半监督事件元素抽取方法。首先,该方法将事件元素抽取建模为问答任务,在问题构建过程中显式建模角色标签的语义,最大化参数的共享,增加模型在小样本或者零样本场景下的鲁棒性。其次,该方法引入事件元素抽取的对偶子任务,利用对偶学习实现半监督的事件元素抽取,自动扩展标注数据,迭代优化模型,进一步提升模型在小样本和零样本场景下的性能。最后,在国际公开数据集ACE 2005和FewFC上的实验结果验证了该方法的有效性。
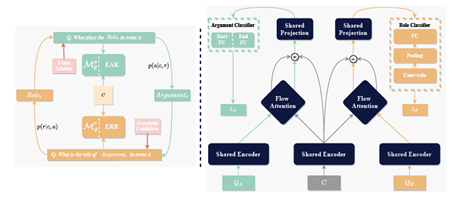
图. 基于对偶问答的半监督事件元素抽取框架图
Yang Zhou, Yubo Chen, Jun Zhao, Yin Wu, Jiexin Xu, JinLong Li :What the Role Is vs. What Plays the Role: Semi-Supervised Event Argument Extraction via Dual Question Answering . The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI) 2021
02
基于同步交互式解码的多语言神经机器翻译方法
Synchronous Interactive Decoding for Multilingual Neural Machine Translation
神经机器翻译技术推动了多语言翻译研究的发展。基于“编码器-解码器”架构的神经网络具有强大的端到端建模能力,单个翻译模型可以同时处理多个语言对,降低了多语言翻译系统的部署成本。然而,现有的神经机器翻译模型在推理过程中预测下一个词汇时,只依赖于语种内和语种间的历史及未来4类信息中的一类或两类,为了充分利用这4类信息以提升不同目标语言的翻译质量,自然语言处理团队提出了基于同步交互式解码的多语言神经机器翻译方法。
该方法主要包括三个部分:
1)同步交互式多语言注意机制模块。让每一路的目标序列分别与语种内和语种间的历史信息、未来信息共4类信息执行注意力计算,得到4类注意力隐状态,再通过一个融合机制得到最终的隐状态输出。
2)同步交互式多语言翻译模型。将所提出的同步交互多语言注意力模块替换标准Transformer中解码器的自注意力模块,得到整体模型结构。
3)同步交互式多语言翻译解码方法。翻译过程中维护所有目标语言的正向反向翻译假设,并且在解码的每一步中,所有翻译假设执行信息交互。
实验表明,所提方法能够有效提升多语言神经机器翻译方法的译文质量。
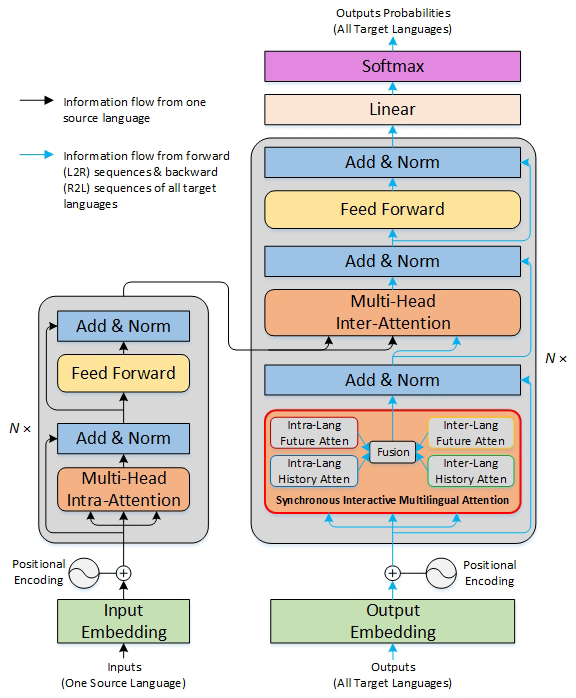
(a) 同步交互多语言翻译模型结构
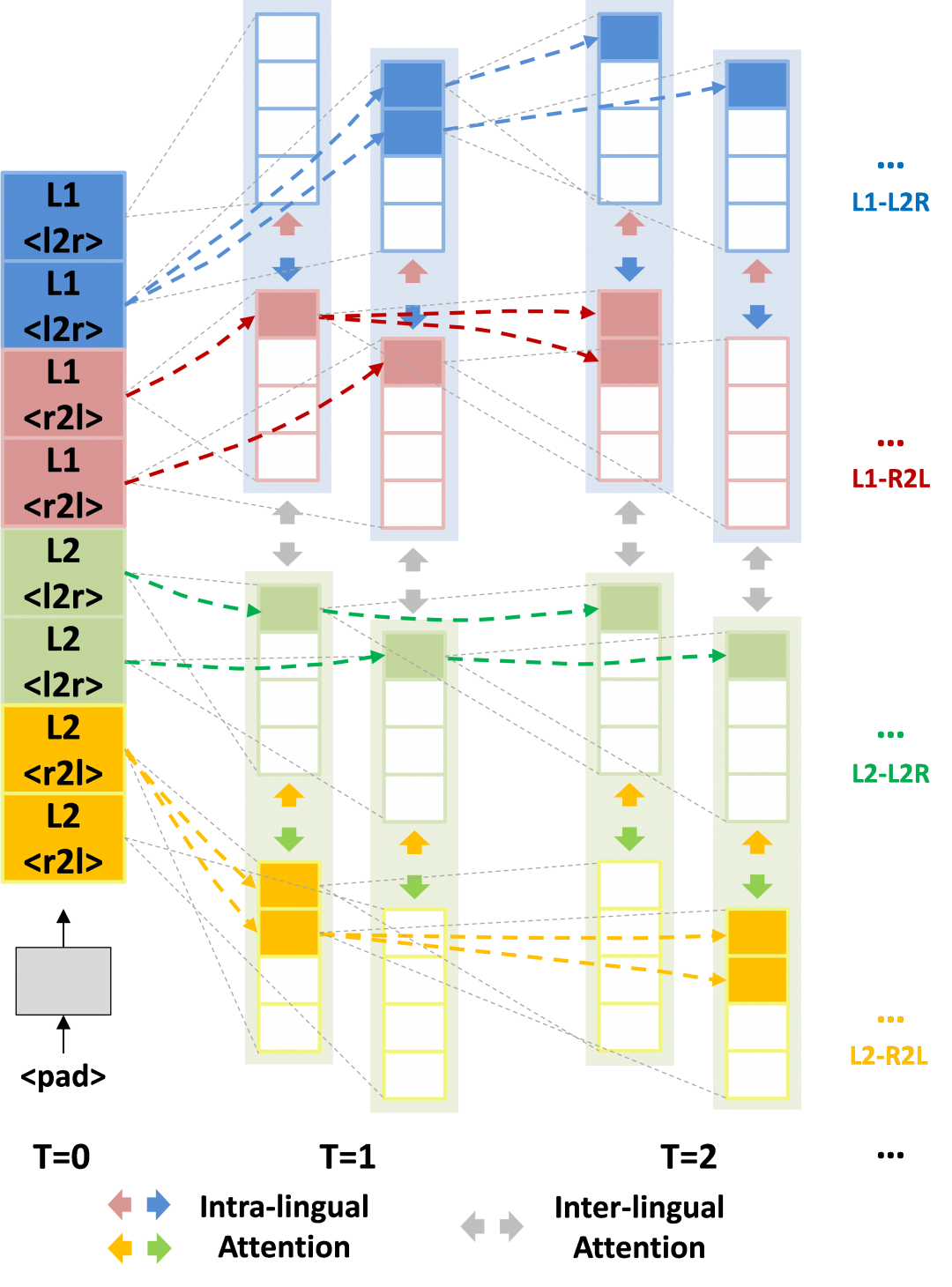
(b) 同步交互多语言翻译解码柱搜索
图. 基于同步交互式解码的多语言神经机器翻译方法
Hao He, Qian Wang, Zhipeng Yu, Yang Zhao, Jiajun Zhang, Chengqing Zong:Synchronous Interactive Decoding for Multilingual Neural Machine Translation. The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI) 2021
03-04
基于多步监督和连续解码的端到端语音翻译模型
随着跨语言交流的日益频繁,语音翻译技术受到了越来越多的关注,其应用场景包括影视出海、跨国旅游、国际贸易等。传统的级联式语音翻译系统通常由独立的语音识别模型(ASR)和文本翻译模型(MT)组成,存在着模型存储大、时延高、计算资源消耗多、错误累积等问题。而端到端语音翻译模型(ST)直接输入源语言的音频,输出目标语言的文本,将语音识别技术和文本翻译技术融合到一个模型中,具备低延迟、误差传播小、易部署等潜力。但由于目前音频及对应的目标语言文本的平行数据还比较匮乏,因此端到端语音翻译是一项非常具有挑战性的任务。
本系列研究就端到端语音翻译任务提出了基于多步监督的解耦合框架和连续解码的联合建模框架。
基于多步监督的解耦合框架(Listen & Understand & Translate,简称LUT)将端到端语音翻译分解为三个阶段,第一阶段是“听”:;第二阶段是“理解”:;第三阶段是“翻译”,分别对应着声学编码器、语义编码器和翻译解码器。具体地来说:“听”的阶段负责提取声学表征;“理解”的阶段负责提取语义表征;“翻译”阶段负责生成目标语言的翻译文本。为了让模型能够显式地建模三个阶段,LUT为每个阶段引入各自的监督信号来对模型的训练过程进行约束。第一阶段使用源语言的识别转写文本作为监督信号,优化目标使用连接时序分类损失函数(CTC);第二阶段使用识别转写文本对应的预训练的语义表示作为监督信号,优化目标使用均方误差损失函数(MSE);第三阶段使用目标语言的翻译文本作为监督信号,优化目标使用交叉熵损失函数(CE)。模型的整体优化目标是三阶段目标的加权求和。LUT利用对ASR数据和ST数据进行采样训练的技巧,能够有效地利用额外的ASR平行数据。
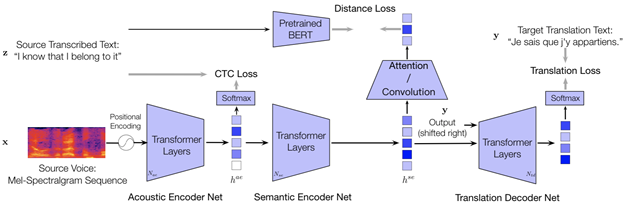
图1. 基于多步监督的解耦合框架
基于连续解码的联合建模框架 (COnsecutive Transcription and Translation,简称COSTT)采用编码器-解码器的框架:编码器用于“声学-语义”建模过程;解码器用于“转写-翻译”的建模过程。COSTT在“转写-翻译”建模阶段使用一个共享的解码器连续地输出源语言的转写序列和目标语言的翻译序列,能够联合建模两种文本序列之间的条件依赖关系。“转写-翻译”建模阶段的优化目标是两个对应文本序列的拼接,使用任务标识符分隔,优化目标为交叉熵损失函数(CE)。另外考虑到解码器对编码器的交叉注意力需要关注的帧序列过长,COSTT在“声学-语义”建模阶段对声学编码进行了压缩。为了完成声学编码的压缩,在“声学-语义”建模的中间层增加源语言转写对应的音素序列的监督信息,优化目标为连接时序分类损失函数(CTC)。模型的整体优化目标为两个阶段目标的加权求和。另外,COSTT利用了跨语言语言模型预训练的技巧预训练解码器,能够有效地利用额外的MT平行数据。
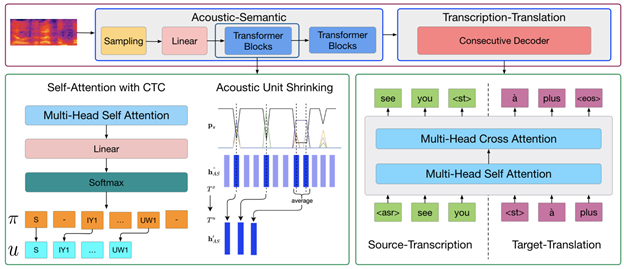
图2. 基于连续解码的联合建模框架
本系列研究提出的端到端语音翻译模型在增广LibriSpeech英法、IWSLT 2018 英德、TED英中语音翻译数据集上取得了SOTA结果。
Qianqian Q Dong, Mingxuan Wang, Hao Zhou, Shuang Xu, Bo Xu, Lei Li:Consecutive Decoding for Speech-to-Text Translation. The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI) 2021
Qianqian Q Dong, Rong Ye, Mingxuan Wang, Hao Zhou, Shuang Xu, Bo Xu, Lei Li :"Listen, Understand and Translate": Triple Supervision Decouples End-to-End Speech-to-Text Translation. The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI) 2021
Data Mining & Knowledge Management
01
基于图神经网络的文本语义匹配算法
A Graph-Based Relevance Matching Model for Ad-Hoc Retrieval
文本匹配是一项研究两段文本之间的相关关系的任务,在如搜索引擎、文档挖掘、智能对话等场景有着广泛应用和重要意义。
在文本匹配任务中,目标文本和候选文本之间的联系以及文本内部的上下文关联都是实现准确匹配的关键。然而,大多数已有的深度神经网络模型只关注了前者,忽略了每个文本内部的上下文语义信息,从而面临着长文本、复杂文本难匹配等问题。
为了解决上述问题,中科院自动化所智能感知与计算研究中心团队提出一种基于文本图神经网络架构的匹配方法,用图(graph)结构表示文本,能够同时建模两个文本之间的交互以及每个文本内部的上下文关联,可以有效缓解现有方法中长文本难匹配的问题,如图1所示。
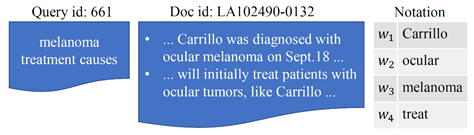
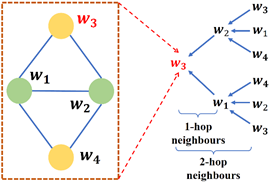
图1. 文本匹配示例
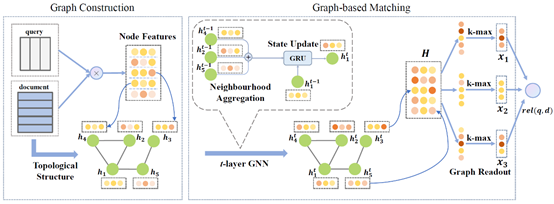
图2. 基于图神经网络的文本匹配框架示例
代码:https://github.com/CRIPAC-DIG/GRMM
Yufeng Zhang, Jinghao Zhang, Zeyu Cui, Shu Wu, Liang Wang:A Graph‐Based Relevance Matching Model for Ad-Hoc Retrieval . The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI) 2021
//////////
此外,另有雷震研究员参与完成的论文《Searching for Alignment in Face Recognition》1 、尹奇跃副研究员参与完成的论文《Adaptive Prior-‐Dependent Correction Enhanced Reinforcement Learning for Natural Language Generation》2被AAAI2021大会接收。
1.Xiaqing Xu, Qiang Meng, Yunxiao Qin, Jianzhu Guo, Chenxu Zhao, Feng Zhou, Zhen Lei:Searching for Alignment in Face Recognition. The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI) 2021
2.Wei Cheng, Ziyan Luo, Qiyue Yin:Adaptive Prior‐Dependent Correction Enhanced Reinforcement Learning for Natural Language Generation. The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI) 2021







