Pix2Seq:谷歌大脑提出 CV 任务统一接口!

文 | 青豆
最近一个大趋势就是将各类任务统一在一个大一统框架下。大规模预训练语言模型已成功打通各类文本任务,使得不同的NLP任务上,都可以用这种统一的sequence生成框架作为基础模型,只需要通过prompt的方式,指导模型生成目标结果。
这种大一统的sequence生成框架在NLP任务成功的关键是任务描述和任务输出都可以序列化成text tokens。
但CV任务输入输出都更加多样,那不是得为不同的任务定制不同的模型和损失函数?这也是CV任务大一统框架的瓶颈。
以自然语言为输出的任务,比如image captioning、visual question answering这类任务,天然可以转化为生成text token sequence。但模型的输出形式还存在很多其他的形式,例如bounding box、dense masks等。
Pix2Seq在这样的动机下诞生了:既然输出形式不同是难点,能否将各类输出形式都统一成token sequence?
去年Google Brain提出的Pix2Seq就以目标检测作为出发点,建立Pixel-to-Sequence的映射,探索了这种可能性(戳《图灵奖大佬+谷歌团队,为通用人工智能背书!CV 任务也能用 LM 建模!》)。
目前的Pix2Seq v2进一步统一了四个完全不同的视觉任务:目标检测(object detection)、实例分割(instance segmentation)、人体关键点检测(keypoint detection)、图像描述生成(image captioning),尽管他们的输出可以是bounding boxes,也可以是dense masks,都可以表示成token sequence。
这种离散的、统一化的表示,使得多种CV任务能够统一在一个模型架构或损失函数下。
对单个任务,不再需要对模型或损失函数做定制,而是只需要将任务描述放在prompt中,控制output sequence变成所需要的输出格式。
这种大一统的Pix2Seq框架,已经能够在这四个核心视觉任务上,媲美那些专门为各任务定制的state-of-the-art。
论文题目:
A Unified Sequence Interface for Vision Tasks
论文链接:
https://arxiv.org/abs/2206.07669
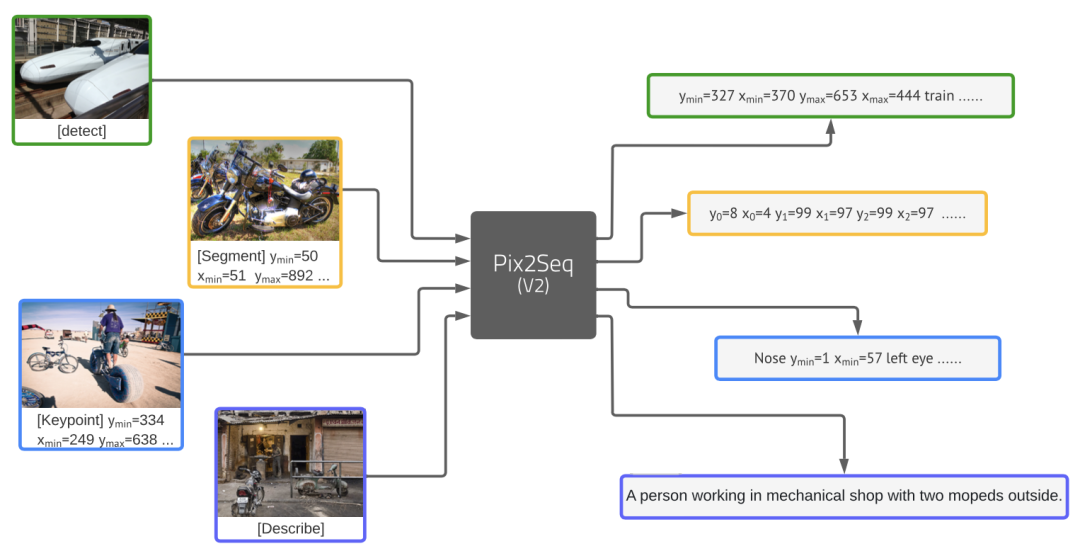
![]() 背景介绍:4个视觉核心任务
背景介绍:4个视觉核心任务![]()
 背景介绍:4个视觉核心任务
背景介绍:4个视觉核心任务-
目标检测(object detection):输入是一张图片,输出是所有object的bounding box和class label。 -
实例分割(instance segmentation):输入是一张图片和其中的objects,输出是对每个object的dense pixel-wise mask。 -
人体关键点检测(keypoint detection):输入是一张图片和其中的person objects,输出是keypoint坐标点来表示head、eyes等person instances。 -
图像描述生成(image captioning):输入是一张图片,输出是一句话。
![]() Sequence建模四步走
Sequence建模四步走![]()
要将CV任务统一建模成sequence生成,主要包括以下几步:
1. 统一输入输出:Tokenization序列化
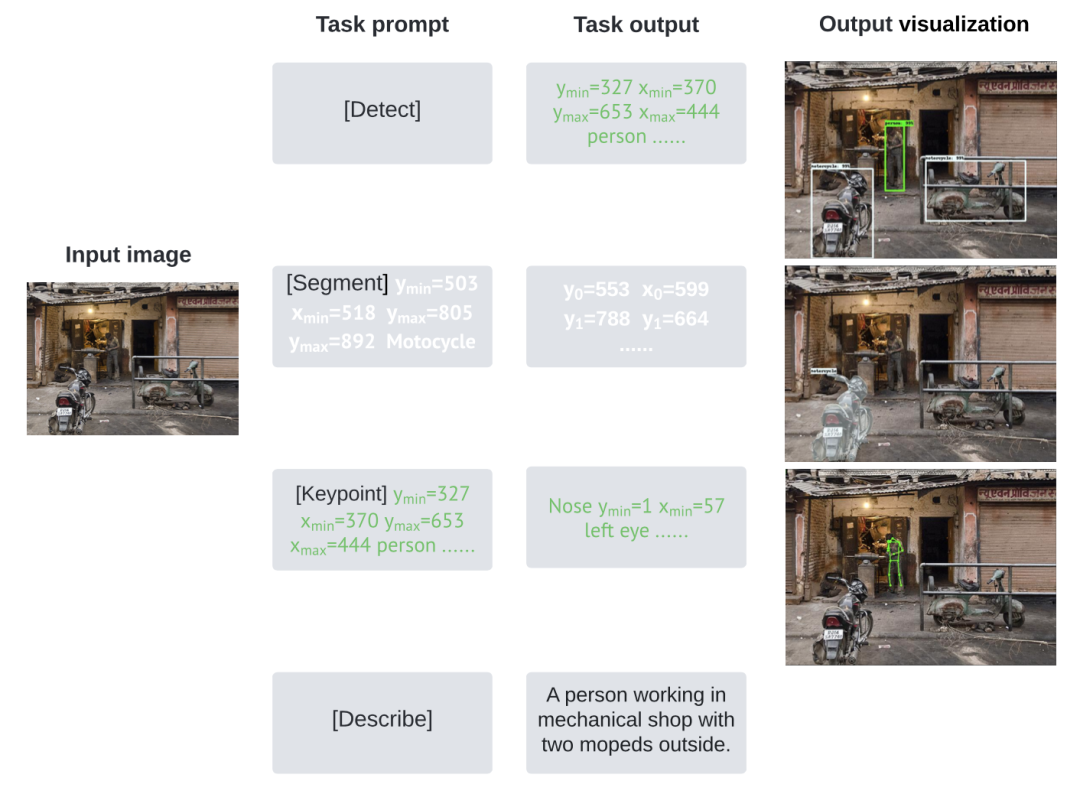
输入是一张image;输出是一个离散的token sequence:task prompt + task output,其中task prompt用于描述具体任务(一般是任务指令+additional input tokens),task output是需要model生成的部分,是目标结果的序列化描述。例如对上述四个任务:
-
目标检测(object detection):task prompt是detect指令,task output包括每个object的bounding box两个坐标点和object label。 -
实例分割(instance segmentation):task prompt包括segment指令和给定的object instance,task output是segmentation多边形的坐标。 -
人体关键点检测(keypoint detection):task prompt包括keypoint指令和给定的object instance,task output是一些keypoint坐标点。 -
图像描述生成(image captioning):task prompt是Describe指令,task output是image caption sentence。
2. 统一损失函数
现在数据变成了统一的image input和sequence output,那么input image可以自然地用一个vision encoder表示(CovNet、Transformer等都可),output sequence可以用一个sequence decoder建模,即给定encoder hidden state和之前生成的sequence,预测下一个token:
这里x代表image,y1:j-1是之前生成的sequence,yj是下一个token。但由于output sequence包括两个部分task prompt和task input,其中task prompt是给定的,不需要生成,因此不需要加到generation loss中。
所以,这里引入wj权重,当yj在task prompt中,wj设置成0,不参与loss计算。
3. 多任务联合训练
由于输入输出形式、损失都是统一的,在优化时可以选择两种联合训练的方式:
(1)直接混合所有数据,随机采样,进行优化:

(2)对各task分别计算loss,然后合并所有task的梯度,优化模型:

第一种更为简单,但涉及到image augmentations对不同output sequence可能是不同的。
同时,第二种可以控制每个task的权重,作者通过贪心策略逐个添加task并调整权重,确定最终的各个task权重。
4. 最终输出:反序列化Detokenization
反序列化就是把token再次数字化,例如对与objection detection,将output token sequence变成5个token一组,每组前4个token代表坐标,第5个token代表object class label。
其中,序列的生成和Pix2Seq第一个版本一样,都采用nucleus sampling。
![]() 实验结果
实验结果![]()
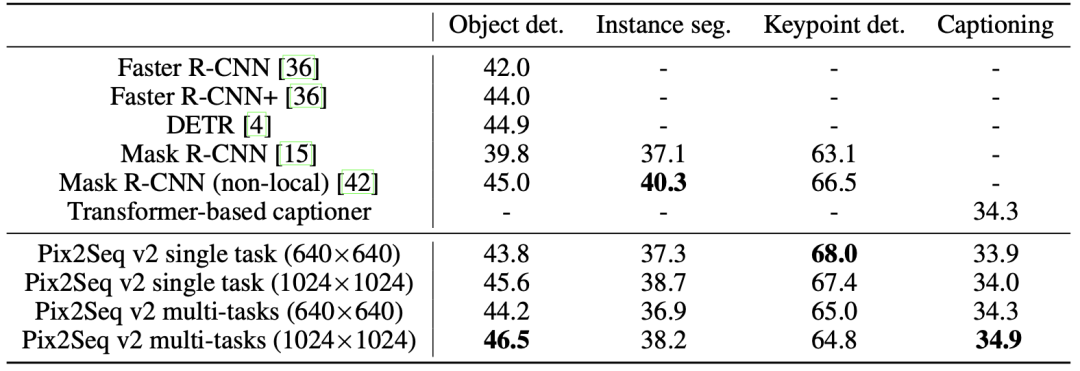
实验的架构和Pix2Seq是一样的,采用了Vision Transformer (ViT-B) encoder和Transformer autoregressive decoder,共有132M的参数。
值得注意的是该论文没有使用大规模图片-文本预训练。模型的初始化来自于Pix2Seq,是在Object Detection数据集上预训练得到的(因此image captioning的结果受限,加入图片-文本数据应该会有提升)。
图片的大小有640x640和1024x1024两种大小。同时作者比较了两个变种:single task单独训练各任务,multi-task会同时一起训练所有任务,即多任务联合训练。
主要的结论包括:
-
该模型在4个任务中都取得了与主流模型相当的效果。 -
多任务训练的影响:并不统一。 -
图片大小的影响:图片越大,结果越好。
![]() 结论
结论![]()
这篇工作的模型架构和第一版的Pix2Seq基本一致,重点在于怎样将这种框架adapt到多种不同输出形式的CV任务上。目前对各个CV任务的序列化非常直观简单,但效果却是不错的。
![]() 最后的话
最后的话![]()
大一统模型近期层出不穷,而这种离散的token序列的表示方式,小编认为是非常有希望的一个方向,因为这种方式同时可以尝试把NLP和CV并入一个框架,同时离散token的方式也天然能够加入speech的处理。
因此,小编也很期待这种统一接口可以加入更多模态(modality),例如video、audio等。
小编在读的时候,主要的concern是这种localization真的可以准确吗?这个quantilize和dequantilize的过程把number变成了token,失去精度不准确怎么办?
作者在实验中针对这个问题,也做了简单的处理,对instance segmentation任务,通过nucleus sampling生成多个结果,并取平均。
但对数值化的token表示应该是需要更多思考的,这种token在未来是否可以具备计算能力,也是很有意思的议题。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜广推与求职讨论群
 后台回复关键词【入群】
后台回复关键词【入群】
