超限多标签学习(XML)成为一项重要的任务,并提出了许多有效的方法。为了充分理解XML,东南大学最新学者《超限多标签学习XML》进行了调研综述。

近几十年来,多标签学习受到了学术界和产业界的广泛关注。虽然现有的多标签学习算法在各种任务中都取得了良好的性能,但它们隐含地假设目标标签空间的大小并不大,这对现实场景有一定的限制。此外,由于计算和内存开销,直接将它们调整到超大的标签空间是不可行的。因此,超限多标签学习(XML)成为一项重要的任务,并提出了许多有效的方法。为了充分理解XML,我们在本文中进行了调研综述。我们首先从监督学习的角度阐明XML的正式定义。然后,根据不同的模型体系结构和问题所面临的挑战,我们对每种方法的优缺点进行了深入的讨论。为了进行实证研究,我们收集了大量关于XML的资源,包括代码实现和有用的工具。最后,我们提出了XML可能的研究方向,例如新的评估指标、尾部标签问题和弱监督XML。
https://arxiv.org/abs/2210.03968
引言
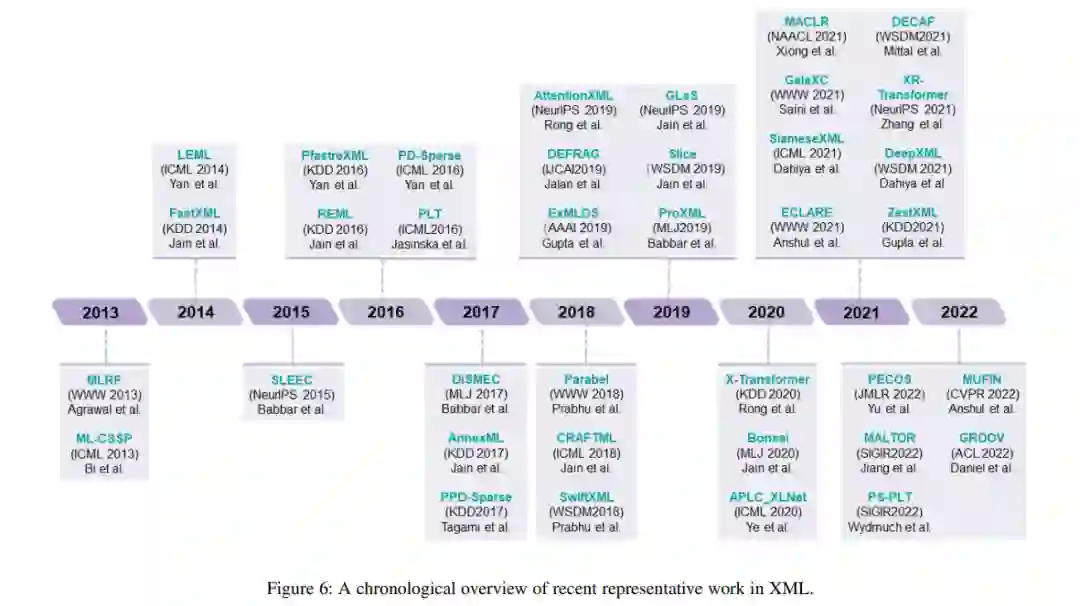
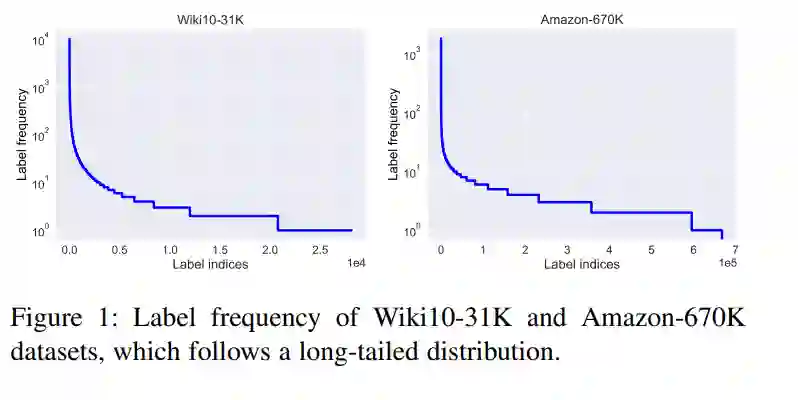
多标签学习[1],[2],[3],[4]是最重要的机器学习范例之一,其中每个现实世界的对象用一个实例(特征向量)表示,并与多个标签相关联。在过去的几十年里,许多多标签学习算法被提出。例如,二进制相关性[5]分别学习每个标签的二进制分类器,它忽略了标签关系。ECC[6]以顺序的方式学习每个标签的单独分类器,这意味着随后学习的分类器可以利用之前的标签信息。RAKEL[7]通过将标签的随机子集映射为自然数,即2 |Y|→N,将多标签学习任务转化为多类分类任务,从而能够对标签之间的高阶相关性进行建模。随着训练数据的快速增长,深度学习被广泛用于充分利用标签相关性[8],[9],[10]。 超限多标签学习(Extreme Multi-label Learning, XML)旨在从大量的候选标签中标注出具有相关标签的对象。近年来,XML在推荐系统、搜索引擎等领域得到了广泛的应用。特别是,图1展示了Wikipedia和Amazon的两个真实的XML数据集,它们具有大量的标签,其频率通常遵循长尾分布。由于标签空间的高维数,传统的多标签学习方法如ML-KNN[16]、RAKEL[7]、ECC[6]、Lead[17]、Binary Relevance[5]都变得不可用,需要新的算法。此外,在处理长尾数据时,这个问题变得更加严重。在不考虑长尾标签分布的情况下,模型在尾标签上的性能很不理想。此外,诸如内存开销和缺少标签等其他挑战也阻碍了XML的应用。幸运的是,在过去的十年中,XML逐渐引起了机器学习、数据挖掘和相关团体的广泛关注,并被广泛应用于各种问题[10]、[15]、[18]、[19]、[20]、[21]、[22]、[23]、[24]、[25]、[26]、[27]、[28]、[29]、[30]、[31]、[32]、[33]、[34]、[35]。具体来说,近8年(2014-2022年),在大型机器学习和数据挖掘会议(包括ICML/ECMLPKDD/IJCAI/AAAI/KDD/ICLR/NeurIPS)上,出现了50多篇论文中以“超限多标签”(或“大规模多标签”)为关键词的论文。因此,了解现有的工作对于研究者和实践者都是很重要的,并分析该领域的未来方向。
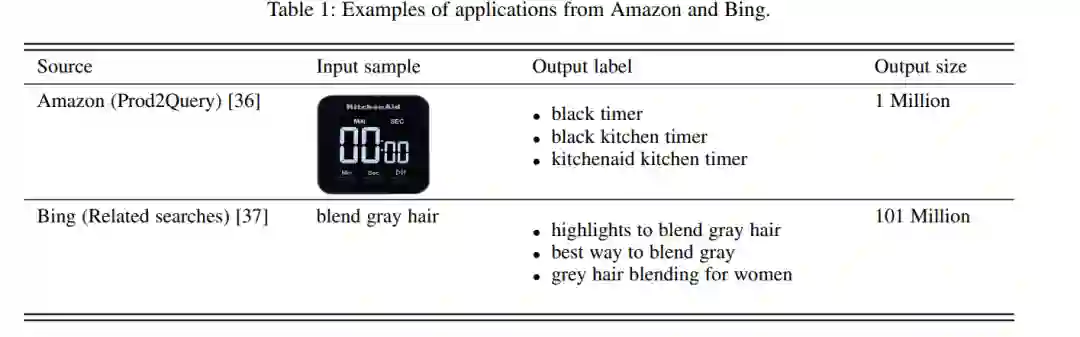
1.1 实际的例子
1.1.1 推荐系统
在亚马逊的产品搜索[38]和阿里巴巴的零售[39]中,每个产品都被视为一个标签,用户可能想从大量的候选集合中为用户推荐他们可能喜欢的产品列表。在这种设置下,收集用户信息作为输入特征,并利用其购物历史构建观察标签。很容易看出,这个问题可以表述为一个多标签学习任务。由于平台上的产品和用户数量巨大,对训练和推理速度的要求非常高。此外,推荐要个性化,学习到的模型不偏向热门产品,很少推荐稀有产品。这对推荐系统中的XML提出了挑战。
1.1.2 搜索引擎
在搜索引擎中,例如Bing[37],推荐相关查询的问题可以重新表述为一个超限的多标签学习任务。在用户提交查询之后,搜索引擎需要从大量候选集合中推荐可能满足用户需求的最相关的查询。由于标签集的大小可以达到数百万,现有的排名算法遭受不可接受的计算成本。因此,为搜索引擎设计合适的排名算法是一项极具挑战性的任务。
1.2 动机与贡献
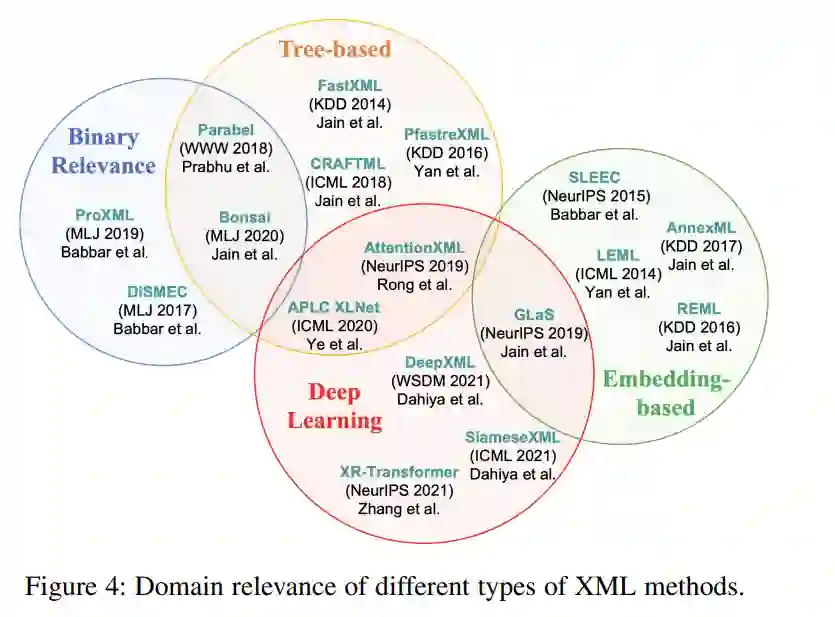
**据我们所知,这是第一次与XML相关的先驱综述。本次调研的贡献可以概括为:**1)综合综述。我们将全面回顾XML,包括核心挑战及其相应的解决方案。2)新分类法。我们提出了一种XML分类法,它从三个不同的角度对现有的XML方法进行了分类:1)模型体系结构; 2) 尾标签学习; 3) 弱监督XML。3) 资源丰富。我们收集了大量关于XML的资源,包括XML方法的开源实现、数据集、工具和纸列表。4)未来的发展方向。我们讨论并分析了现有XML方法的局限性。并提出了未来可能的研究方向。
1.3 调研组织
调研的其余部分组织如下。第2节概述XML,包括背景概念、XML与其他相关设置之间的比较以及XML的核心挑战。第3节从三个角度介绍现有的XML算法。第4节列出了常用的数据集、评估指标和资源。第5节讨论了当前的挑战,并提出了未来几个有前途的方向。最后,第6节结束了调研。
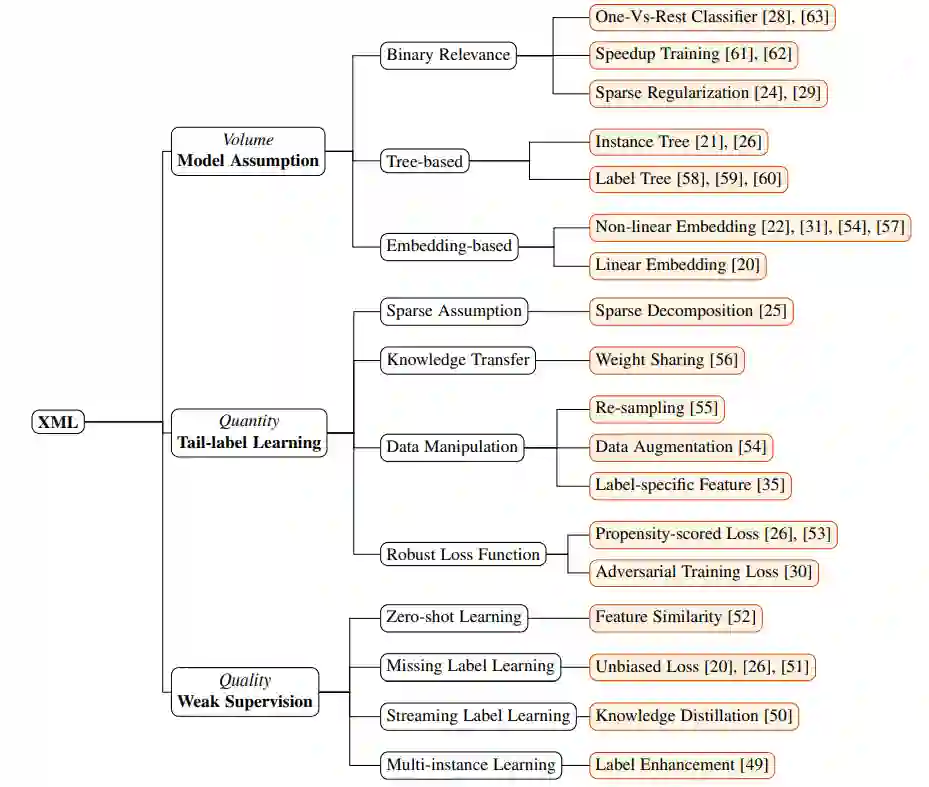
图2:XML的分类和代表性示例。
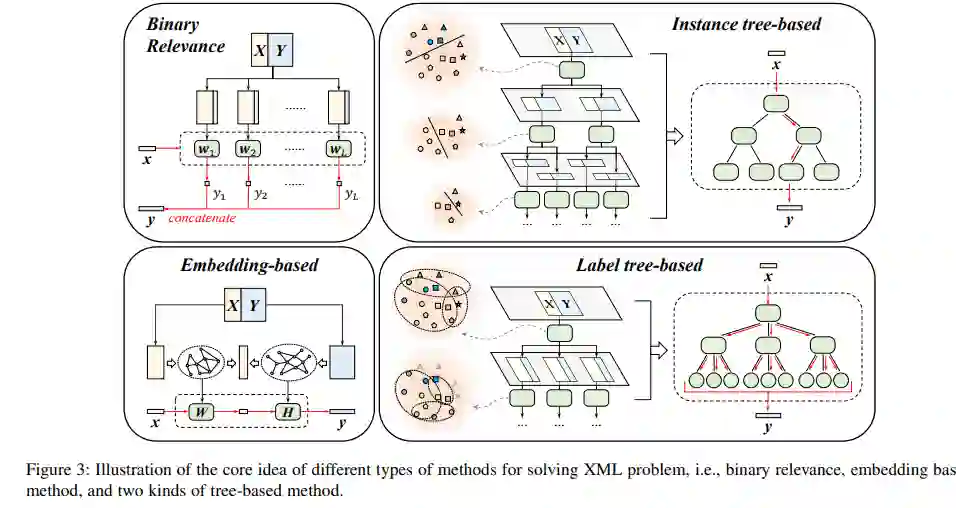
算法开发一直是机器学习研究的核心问题,XML也不例外。在过去的十年中,人们提出了大量的算法来从超限多标记数据中学习。根据每种算法的特性和XML的关键挑战,我们提出了一种新的XML分类法,即:1)模型体系结构;2)尾标签学习;3)弱监督。考虑到在有限的篇幅内浏览所有现有的算法是不可能的,在这篇综述中,我们选择仔细调研每个研究方向的代表XML算法。根据解决XML问题的角度,大多数方法可以分为三个分支:二进制关联法、基于嵌入的方法和基于树的方法。我们在图2中提供了一个说明。