为什么说对抗性图像攻击不是闹着玩的?

在过去的五年间,人们往往对利用特定的对抗性图像攻击图像识别系统这一概念一笑而过,认为其虽然有趣但却不值得深究。然而,澳大利亚的一项研究表明,在商用人工智能项目中随意使用常用图像数据集,很可能会造成影响深远的安全问题。
几年来,一群阿德莱德大学的学者们一直在努力证明,基于人工智能的图像识别系统中一些重要问题的存在。
这些问题目前很难得到解决,或者是解决起来代价高昂。而一旦当前的图像识别研究中的趋势在五到十年内全面的发展为商业化和工业化的部署,那补救的成本将令人完全无法接受。
在开始之前,让我们先看一个例子。
这是阿德莱德大学研究团队发布在项目页上的六个视频之一,展示了一朵花是如何被分类为前总统奥巴马的。
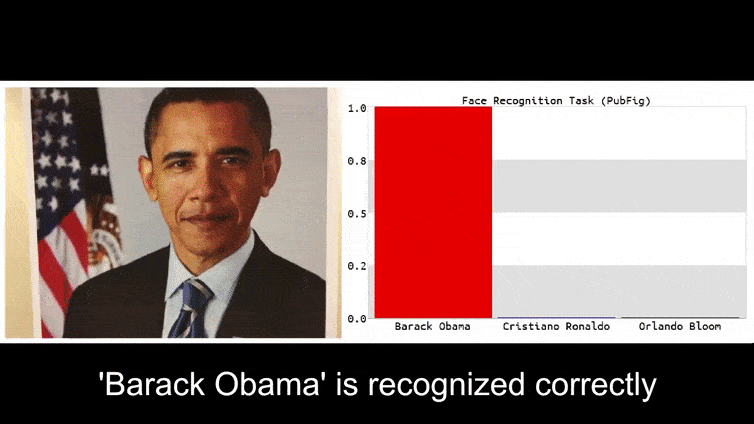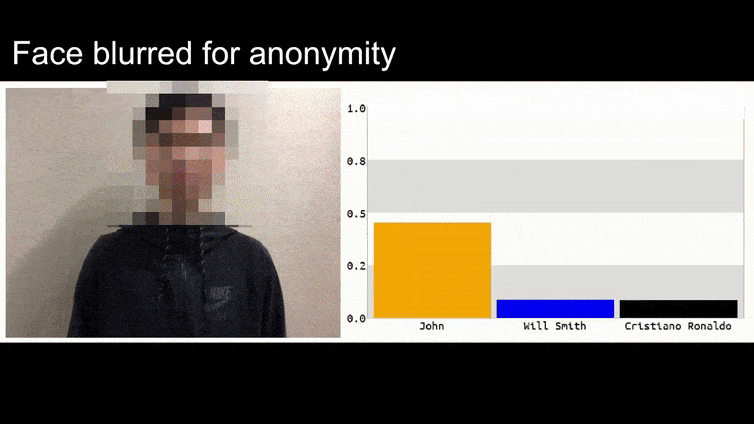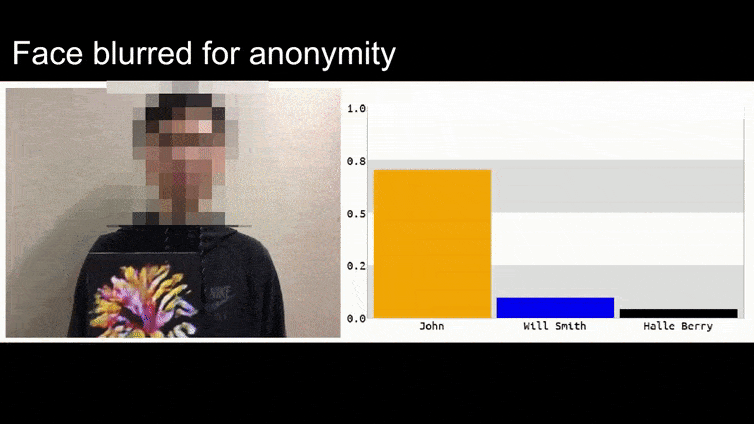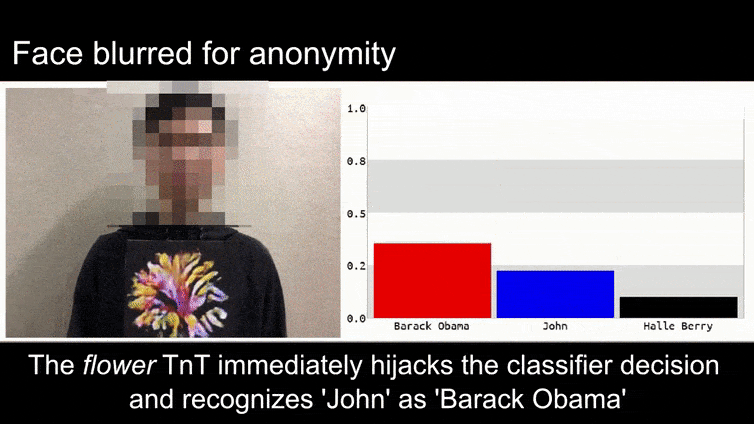
在这个动图里,一个明显会辨认奥巴马的人脸识别系统被骗了,它认为一个脸上打码的男人举着一朵花(人工合成的对抗图片)有 80% 的可能性也是奥巴马。这个系统甚至完全没管这个“假脸”是长在了男人的胸上而不是脖子上。
在这个例子中,研究人员已经能够通过生成连贯的图像(一朵花)而不是通常的随机噪声来完成这种身份捕获。这种愚弄图像识别系统的漏洞实际在 计算机视觉 的研究中经常出现,比如 2016 年 曾出现过的可以骗过人脸识别的带奇怪图案的眼镜,以及尝试 通过特制对抗图像混淆路标辨认 的项目。
上面例子里被攻击的 卷积神经网络(CNN)模型是 VGGFace(VGG-16),使用的训练集是哥伦比亚大学的 PubFig 数据集。其他例子里被攻击的模型都是用了多种资源相结合进行的开发。
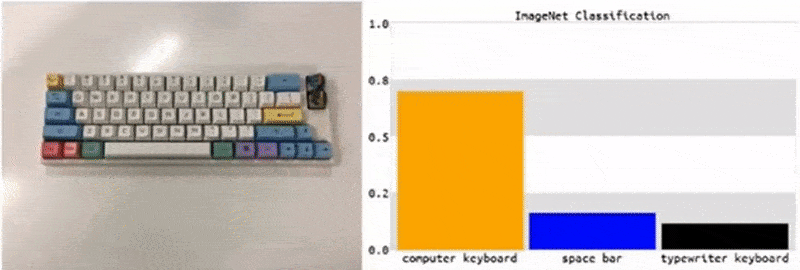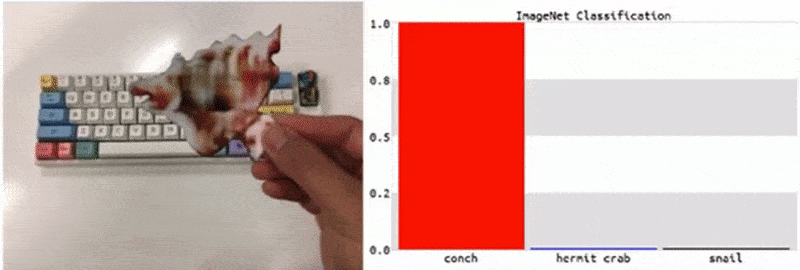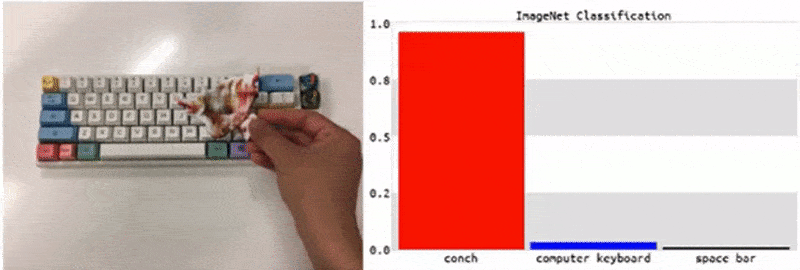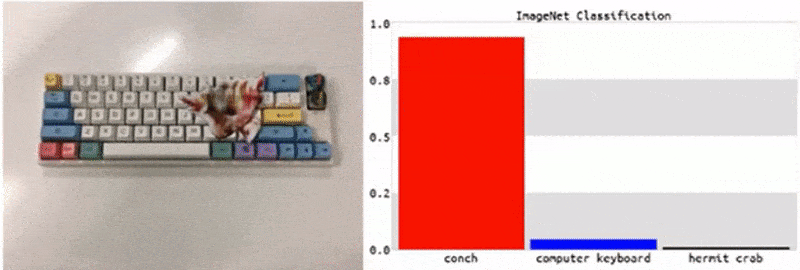
从研究统计出的各类案例可以看出,这类攻击往往在广大 ML 从业者看来不值一提,小伎俩的攻击并不会针对某个特定的数据集或机器学习架构,而无论是更换训练数据集或 ML 模型,还是重新训练模型,这些“简单”的补救措施都无法轻松对其防御。
而阿德莱德团队的研究则揭露了当前图像识别 AI 开发中整个框架的核心弱点,如果不解决这个问题,那么未来许多的图像识别系统都将暴露于黑客操纵的风险,并且后续任何的防御措施都将于事无补。
可以想象,未来将有无数与时俱进的对抗性攻击图像(比如之前例子里的花)以“零日漏洞”的形式存在于各种安全系统中,开发者得像现在的反恶意软件和防病毒框架一样,每天更新病毒的定义。
新型对抗性图像攻击的可能性无穷无尽,因为 ML 系统基础架构没有考虑过下游问题,这就和互联网、千年虫以及比萨斜塔 一样。
那么问题来了,这一切都是什么造成的?
像是之前例子里合成花图片这类的对抗性图像,直接用模型使用的图像数据集就可以生成,不需要骇入或特意去访问训练数据 / 模型架构,这是因为目前这些常用的数据集和模型都可以在一个长期更新维护、拥有海量数据的 Torrent 网站中找到齐全的版本。
举例来说,计算机视觉数据集中的传奇经典,ImageNet,它的所有迭代版本都可以在 Torrent 里下载,免去了原网站设置的各种 限制条件,还让 验证集 这类 ML 模型训练需要的次要元素更易获得。
在拿到数据之后,下一步要考虑的就是该怎么高效地“逆向工程”任何常用的数据集了,比如 CityScapes 或者 CIFAR。
在之前用 PubFig 数据集训练结果误判了一朵“奥巴马花”的例子里,哥伦比亚大学 的研究人员针对现今愈发严重的图片数据集版权问题,提出数据集在再利用的过程中不应直接提供汇编版本,而是应以链接形式进行数据集的复制,“这一现象似乎已是其他大型基于 Web 的数据库当前的发展模式了”。
然而这种担忧在多数情况下是杞人忧天。Kaggle预估 计算机视觉中最常用的十大图像数据集及其对应可用情况有:CIFAR-10 和 CIFAR-100 都可以直接下载,CALTECH-101 和 256 都可用,且可以直接种子下载;MNIST 有官方下载链接,同样可以直接种子下载;ImageNet 见前文;Pascal VOC 可用且可种子;MS COCO 可用且可种子;Sport-1M 可用;YouTube-8M 可用。
十大常用数据集的公开可用,意味着互联网上还能找到更多可用于计算机视觉研究的图像数据集。毕竟在“酒香不怕巷子深”的时代已经一去不复返,压箱底的数据集面临的只有消失一条路。
但无论如何,可管理的 新数据集稀缺,图像数据集开发的成本高昂,对“旧收藏”的依赖,宁愿 直接套用旧数据集 的趋势等等,这些现象无疑都加剧了阿德莱德新论文中概述的问题。
面对这些不断出现的对抗性图像攻击技术,在机器学习工程师们对其有效性的评价中,最常见也最经久不衰的论调就是,这种攻击只会针对某个特定的数据集、某个特定的模型,最多是二者都有,但绝对不会波及到其他的系统。他们会借此得出结论,这类威胁的影响微乎其微,完全不用担心。
第二常见的评论是:因为对抗性图像是“白盒攻击”,所以黑客得拿到训练环境或数据的直接访问权限,然而这在大多数情况下确实不太可能发生。
举个例子,如果我们想对伦敦大都会警局的面部识别系统的训练过程做点什么,那么我们有两个选择,控制台骇入 NEC 或者找把斧头物理骇进去。
至于“对抗性图像攻击只针对个别系统”的言论,或许我们可以先反思下计算机视觉这个行业本身的问题。一是,这几年来只有少数主流的数据集在主导各类研究的发展,多种类型对象的问题用 ImageNet,驾驶相关的场景用 CityScapes,面部识别的用 FFHQ,这些几乎都是行业默认的。二是,各类研究使用的标记后图片数据,是“和平台无关”的,并且高度可转移。
虽然功能各不相同,但几乎所有的计算机视觉训练架构都可以在 ImageNet 数据集里找到自己需要的对象。有的架构可能会有更多的重叠功能,或者与其他体系机构相比能建立更有效的链接,但至少所有的体系结构都应是能找到最高级的特征:
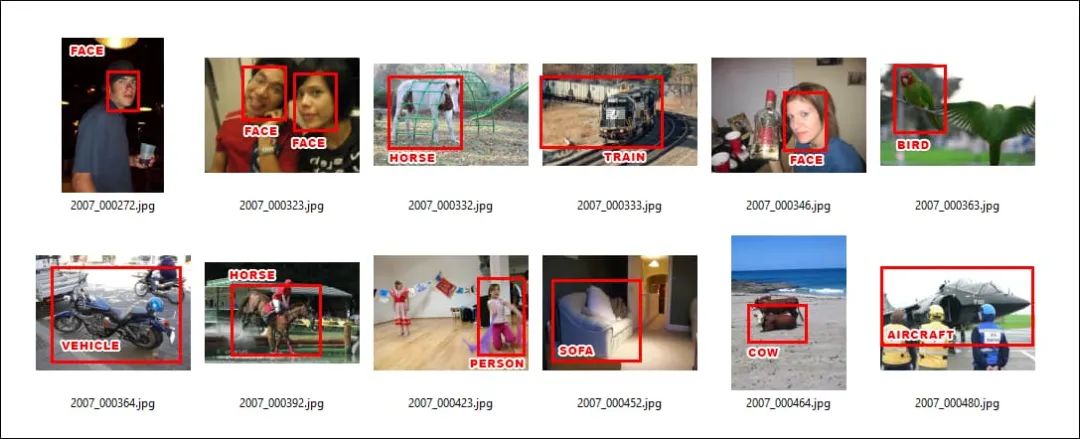
上图中的这些标注可以说用于辨认数据集的“指纹”,但同时也为各种放长线钓大鱼的对抗性图像攻击提供了可靠的鱼钩,让他们能发起跨系统的攻击,并与旧数据集一起共存亡同发展,毕竟这些“老古董”数据集会一直存在于各种新研究和新产品中。
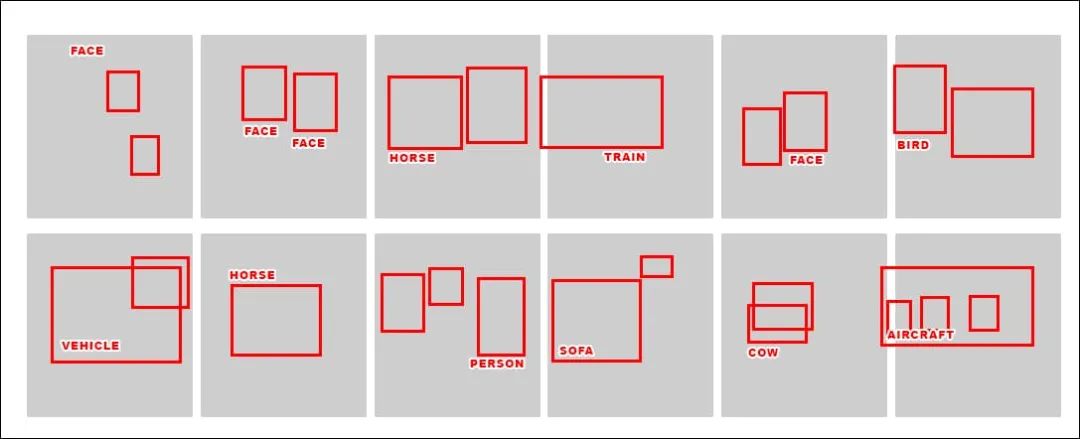
而更复杂的架构将产生更准确和更精细的标识、特征和类:

然而,如果对抗性攻击的生成器更依赖于这些较低等级的特征,比如选择“年轻白种男性(Young Caucasian Male)”而不是“人脸(Face)”,那么在针对使用跨框架或多个版本的原始数据集时(比如子集或过滤后的数据集,其中多数原始数据集中的图片是没有的),攻击效率将愈发低下。

如果我只是下载了个在非常流行的数据集上预训练的模型,然后喂给它全新的数据呢?
举个例子,这个模型之前用 ImageNet 训练过,里面现在只剩了 权重 的数据,如果彻底清空得花几周几个月来重新训练。现在这个模型已经可以用来直接辨别和原数据集中相类似的物体。
这些权重数据很有用。没有权重和数据的框架基本一无是处,得花费大量的时间和计算资源重新进行训练,论文的作者们就是这么干的,不过他们的硬件资源和预算恐怕都比在座的各位都要更多。
但现在的问题是,这些重要的权重数据已经基本成型,尽管在后续的训练中会重新适应新数据,但它们的表现会基本类似,导致其生成的特征是对抗性攻击系统可以追踪到的。
从长远的角度来讲,这也算是保留了计算机视觉数据集的“DNA”。这些古董数据集自诞生起已经有 至少 12 年的历史 了,从开源到商业化部署一路饱经沧桑,就算项目开始使用的最原始的训练数据也被彻底抛弃,就算有的项目在几年内恐怕都看不到商业化部署的未来,它们依然存在。
至于前文提到的第二种评论,澳论文作者发现,这些他们生成的、可以欺骗识别系统的花型图像在一些架构中具有高度可转移性。
虽然他们开发出的“通用自然对抗性 paTches”(TnT)方法是首个使用可识别图像而非随机干扰噪音来欺骗图像识别系统,但作者同时也表示:
“(TnTs)对多种顶尖的分类器都很有效,无论是用 ImageNet 训练后,可在大规模视觉识别任务中广泛使用的 WideResNet50,还是使用 PubFig 数据集训练的人脸识别 VGG 脸部模型,无论是在有目标还是无目标的攻击。
“TnTs 拥有特洛伊木马攻击模式中触发器的自然可实现性,以及生成对抗性样本在各类网络中的通用性和可转移性。
“这为目前和未来即将部署的 DNN 提出了安全保障方面的挑战,攻击者可以通过具有自然外表、不显眼的物体补丁来误导神经网络系统,并不会对模型进行篡改从而被发现。”
澳论文作者认为,如降低神经网络未受攻击时模型预测准确率(Clean Acc),这一类的传统的解决策略理论上可以在一定程度上防御 TnT 补丁,但“TnTs 仍可绕过这些被 SOTA 判定为可靠的防御策略,并让多数防护系统的鲁棒性降为 0%。”
其他可能的解决方案也有很多,如谷歌提出的联合学习,保护了数据集中图像的原始来源;或南京航空航天大学最近发表的,在训练时直接“加密”数据的新方法。
但即使我们真的应用了这些防护措施,我们也需要确保训练时使用的数据要完全与旧数据区分开。目前,最广为流传的 CV 数据集中的一小部分图像和相关注释已经嵌入全球各地项目的开发周期中,以至于这些更像是软件而非数据,当然这些“软件”多年来都没有大更新过了。
机器学习实践让对抗性图像攻击得以实现,而企业化的人工智能开发文化则让其越发成长,在这种开发文化中,成熟的计算机视觉数据集在不断被重复利用,一是因为这些数据集确实有效,二则是重复利用远比从头开始要划算得多,再则是这些数据集都是有学术界和工业界的领军人物和组织进行维护和更新的,其资金和人员配置水平是单个公司难以复刻的。
除此之外,大多数情况下项目使用的数据都不是自己收集的(除了 CityScapes),这些图像都是在近期关于隐私和数据收集的争议之前收集的。因此,这些古董数据集可以说是处于一个 法律的灰色地带,从公司的角度来看,确实是个安全的“避风港”,非常令人欣慰。
《TnT 攻击!针对深度神经网络系统的通用自然对抗补丁》,由阿德莱德大学 BaoBao Gia Doan,Minhui Xue,Ehsan Abbasnejad,Damith C. Ranasinghe,及罗格斯大学计算机科学系 Shiqing Ma 共同撰写。
原文链接:
https://www.unite.ai/why-adversarial-image-attacks-are-no-joke/

你也「在看」吗?👇



