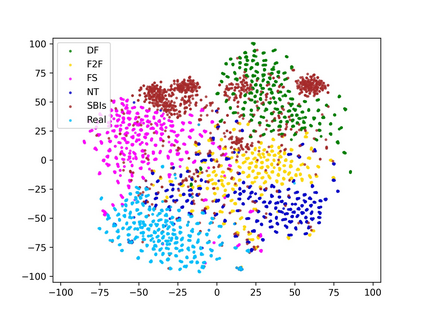
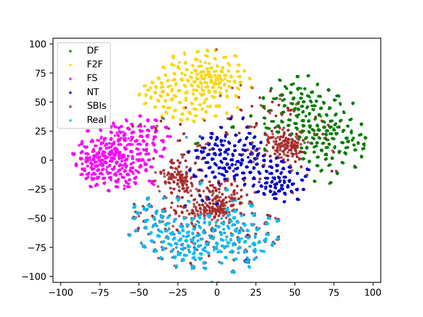
In this paper, we present novel synthetic training data called self-blended images (SBIs) to detect deepfakes. SBIs are generated by blending pseudo source and target images from single pristine images, reproducing common forgery artifacts (e.g., blending boundaries and statistical inconsistencies between source and target images). The key idea behind SBIs is that more general and hardly recognizable fake samples encourage classifiers to learn generic and robust representations without overfitting to manipulation-specific artifacts. We compare our approach with state-of-the-art methods on FF++, CDF, DFD, DFDC, DFDCP, and FFIW datasets by following the standard cross-dataset and cross-manipulation protocols. Extensive experiments show that our method improves the model generalization to unknown manipulations and scenes. In particular, on DFDC and DFDCP where existing methods suffer from the domain gap between the training and test sets, our approach outperforms the baseline by 4.90% and 11.78% points in the cross-dataset evaluation, respectively.
翻译:在本文中,我们提供了称为自我混合图像(SBIs)的新合成培训数据,以探测深假。履行机构是通过混合单一原始图像的假源和目标图像,复制常见的伪造文物(例如,混合源和目标图像之间的界限和统计不一致)。履行机构的主要想法是,更加笼统和难以辨认的假样品鼓励分类者学习通用和稳健的表示方式,而不会过度适应特定操作工艺品。我们将我们的方法与FFF++、CDF、DFD、DFDC、DFDDDDD和FFFIW数据集的最新方法进行比较,方法是遵循标准的交叉数据集和交叉管理协议。广泛的实验表明,我们的方法改进了模型对未知操纵和场景的概括性。特别是,在DFDC和DDDCPD中,现有方法因培训和测试设置之间的领域差距而受到影响,我们的方法比交叉数据集评价中的基线分别高出4.90%和11.78%。