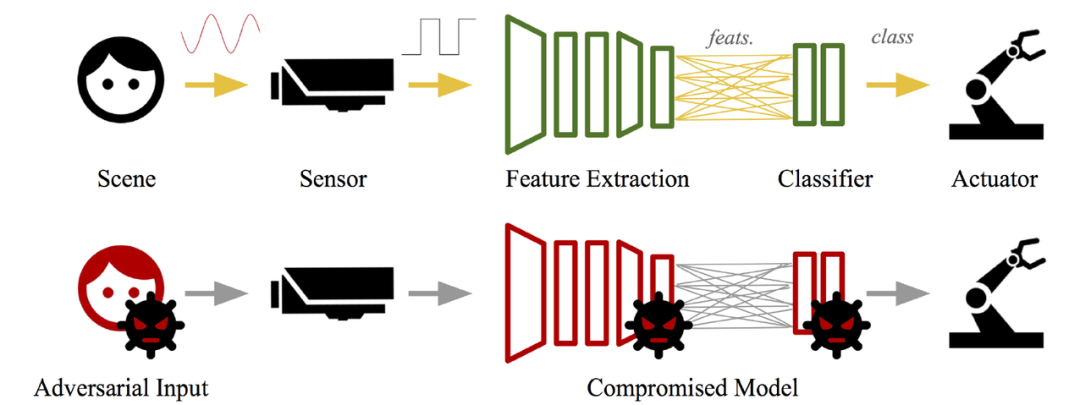
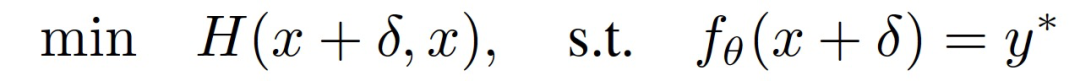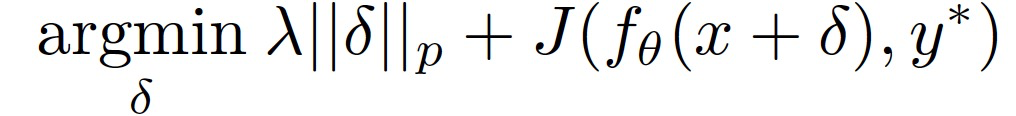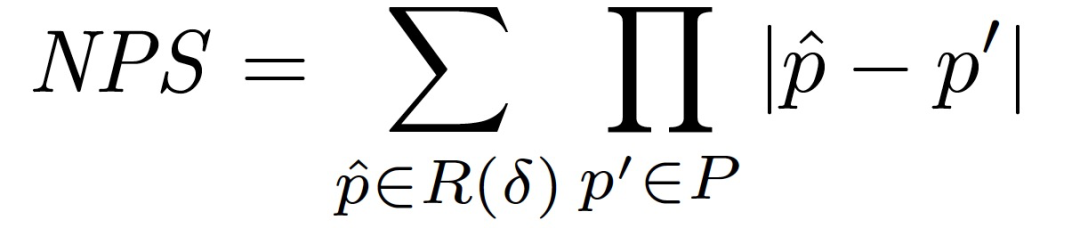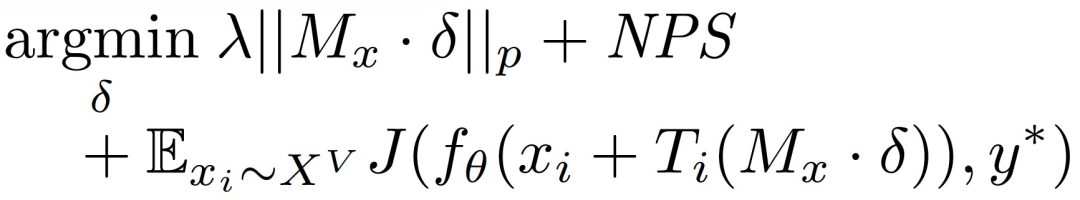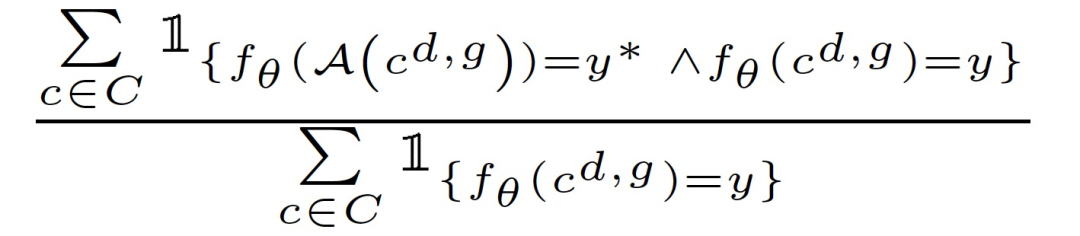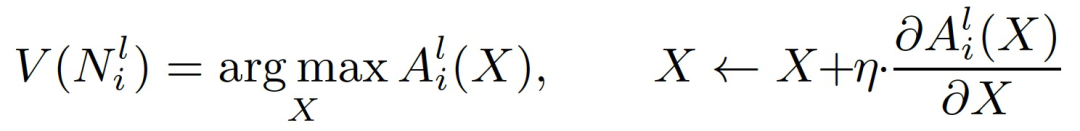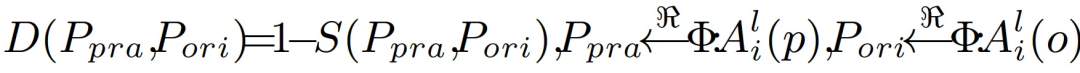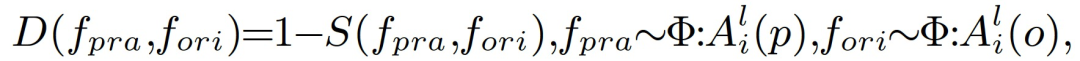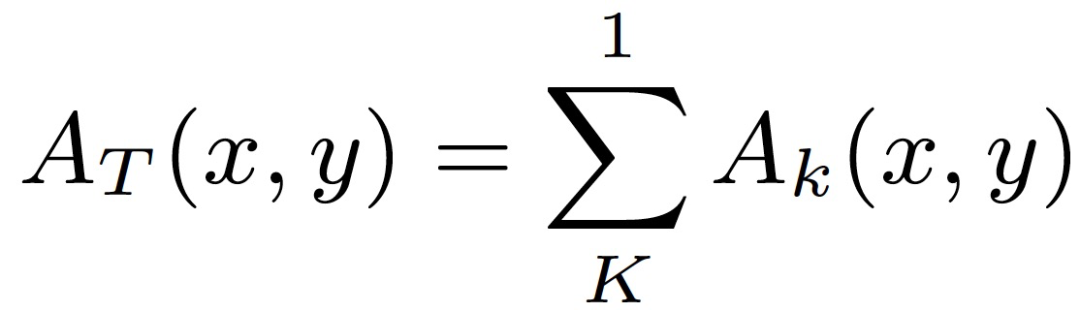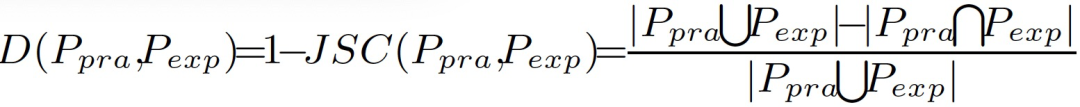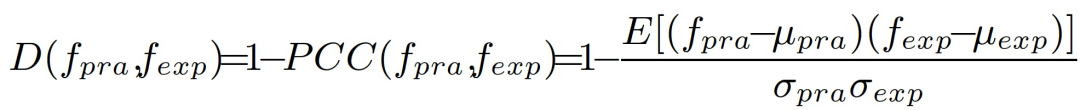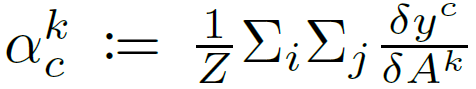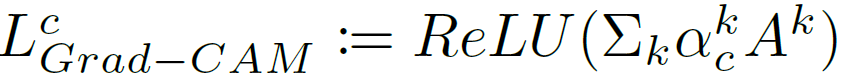本文结合三篇最新的论文具体讨论计算机视觉领域中的物理攻击及检测方法,包括视觉领域和音频领域。
对抗性攻击的概念首先由 Goodfellow 等人提出 [6],近年来,这一问题引起了越来越多研究人员的关注,对抗性攻击的方法也逐渐从算法领域进入到物理世界,出现了物理对抗性攻击。文献[1] 中首次提出了利用掩模方法将对抗性扰动集中到一个小区域,并对带有涂鸦的真实交通标志实施物理攻击。与基于噪声的对抗性攻击相比,物理攻击降低了攻击难度,进一步损害了深度学习技术的实用性和可靠性。
我们都知道,深度学习系统在计算机视觉、语音等多媒体任务上都取得了非常好的效果,在一些应用场景中甚至获得了可以与人类相媲美的性能。基于这些成功的研究基础,越来越多的深度学习系统被应用于汽车、无人机和机器人等物理系统的控制。但是,随着物理攻击方法的出现,这些对视觉、语音等多媒体信息输入进行的篡改会导致系统出现错误行为,进而造成严重的后果。本文重点关注的就是针对多媒体领域的深度学习系统的物理攻击问题。
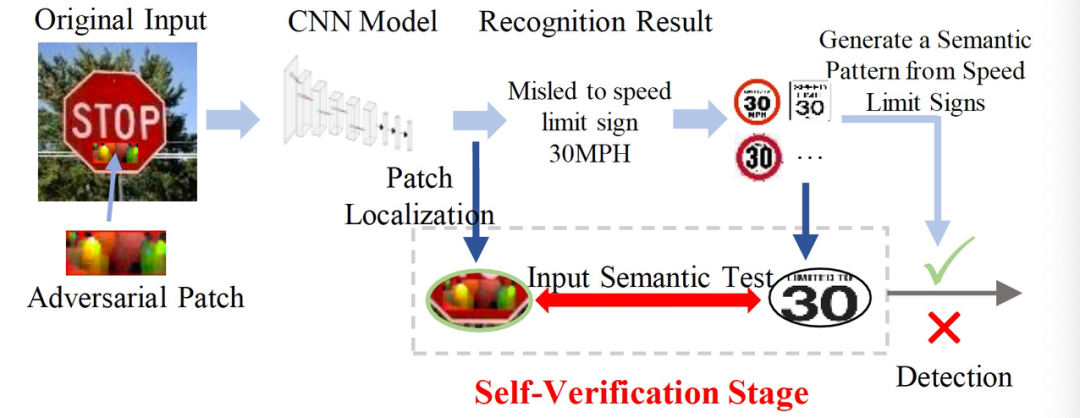
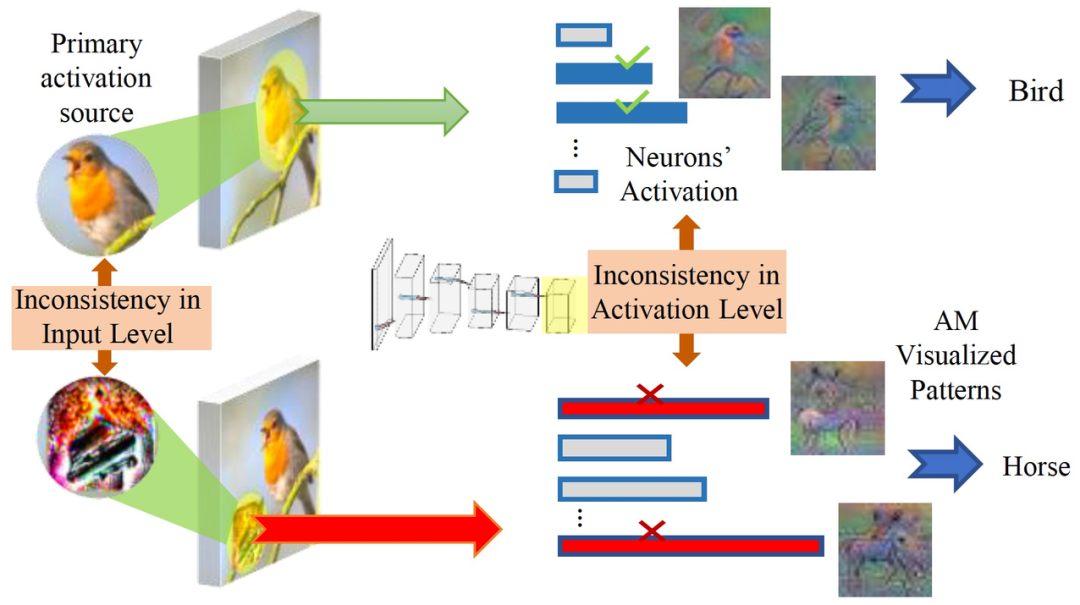
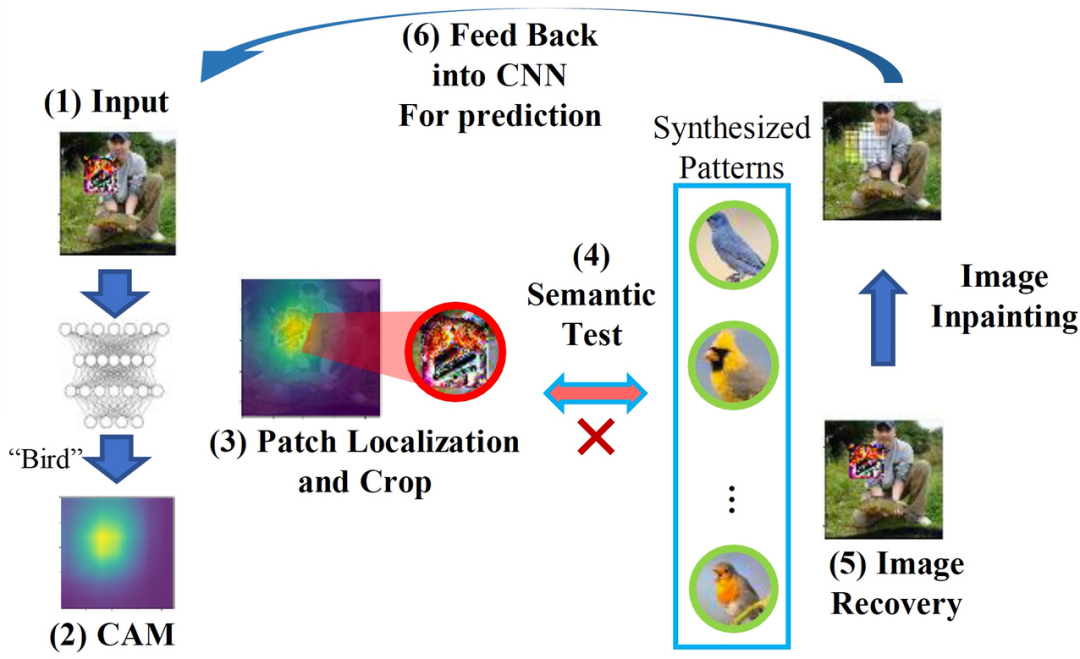
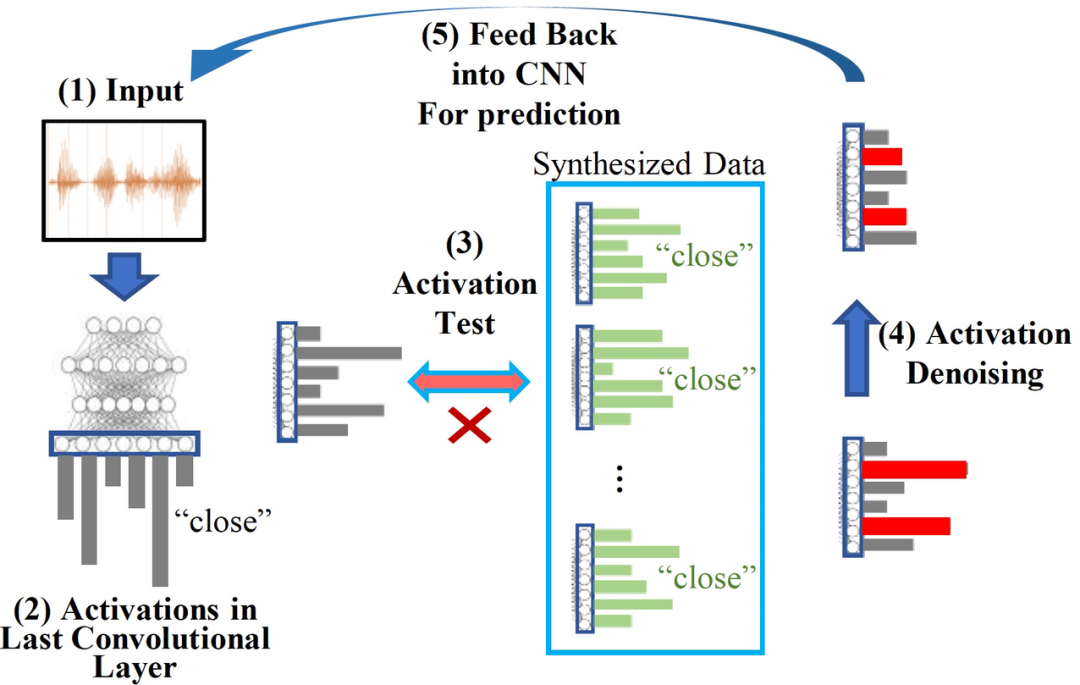
以 [1] 中给出的针对视觉领域的攻击为例,通过向输入数据注入特定的扰动,对抗性攻击可以误导深度学习系统的识别结果。通过物理攻击性方法,对抗性扰动可以集中到一个小区域并附着在真实物体上,这很容易威胁到物理世界中的深度学习识别系统。图 1 给出一个应对物理攻击的实际案例。图 1 中左图显示了一个关于交通标志检测的物理对抗样本。当在原始停车标志上附加一个对抗补丁时,交通标志检测系统将被误导输出限速标志的错误识别结果。图 1 右图展示了交通标志对抗性攻击的自我验证过程。对于每张输入图像,经过一次 CNN 推理后,验证阶段将定位重要的激活源(绿圈),并根据预测结果计算出输入语义与预期语义模式的不一致性(右圈)。一旦不一致性超过预定的阈值,CNN 将进行数据恢复过程以恢复输入图像。关于这一过程,我们会在后面详细解释。
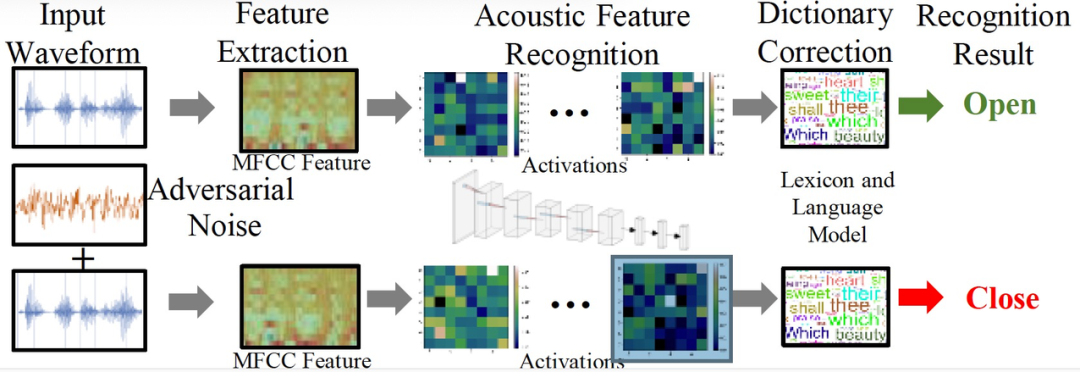
图 2 给出一个典型的音频识别过程和相应的物理对抗性攻击。首先,提取音频波形的梅尔倒谱系数 MeI-Freguency CeptraI Coefficients (MFCC) 特征。然后利用 CNN 来实现声学特征识别,从而获得候选音素。最后,应用词库和语言模型得到识别结果 "open"。将对抗性噪声注入到原始输入波形中时,最终的识别结果会被误导为 "close"。
我们在这篇文章中结合三篇最新的论文具体讨论计算机视觉领域中的物理攻击及检测方法,包括视觉领域和音频领域。首先,我们介绍 Kevin Eykholt 等在 CVPR 2018 上发表的关于生成鲁棒物理攻击的工作,其主要目的是生成对观察摄像机的距离和角度的巨大变化具有很强的适应性的物理扰动攻击。然后,第二篇论文提出了一个针对图像和音频识别应用的物理对抗性攻击的 CNN 防御方法。最后,第三篇文章聚焦于图像的局部物理攻击问题,即将对手区域限制在图像的一小部分,例如 “对手补丁” 攻击:
Robust Physical-World Attacks on Deep Learning Visual Classification,CVPR 2018
LanCe: A Comprehensive and Lightweight CNN Defense Methodology against Physical Adversarial Attacks on Embedded Multimedia Applications,ASP-DAC 2020
Chou E , F Tramèr, Pellegrino G . SentiNet: Detecting Physical Attacks Against Deep Learning Systems. PrePrint 2020. https://arxiv.org/abs/1812.00292
这篇文章重点关注的是如何对计算机视觉任务的深度学习方法进行鲁棒的物理攻击,是从攻击角度进行的分析。作者具体选择了道路标志分类作为目标研究领域。
生成鲁棒的物理攻击所面临的的主要挑战是环境变异性。对于本文选择的应用领域,动态环境变化具体是指观察摄像机的距离和角度。此外,生成物理攻击还存在其他实用性的挑战:(1) 数字世界的扰动幅度可能非常小,由于传感器的不完善,相机很可能无法感知它们。(2)构建能够修改背景的鲁棒性攻击是非常困难的,因为真实的物体取决于视角的不同可以有不同的背景。(3)具体制造攻击的过程(如扰动的打印)是不完善的。在上述挑战的启发下,本文提出了 Robust Physical Perturbations(RP2)--- 一种可以产生对观察摄像机的广泛变化的距离和角度鲁棒的扰动方法。本文目标是从攻击角度进行研究,探讨是否能够针对现实世界中的物体创建强大的物理扰动,使得即使是在一系列不同的物理条件下拍摄的图像,也会误导分类器做出错误的预测。
对物体的物理攻击必须能够在不断变化的条件下存在,并能有效地欺骗分类器。本文具体围绕所选择的道路标志分类的例子来讨论这些条件。本文的研究内容可以应用于自动驾驶汽车和其他安全敏感领域,而本文分析的这些条件的子集也可以适用于其他类型的物理学习系统,例如无人机和机器人。
为了成功地对深度学习分类器进行物理攻击,攻击者应该考虑到下述几类可能会降低扰动效果的物理世界变化。
环境条件。自主车辆上的摄像头与路标的距离和角度不断变化。获取到的被送入分类器的图像是在不同的距离和角度拍摄的。因此,攻击者在路标上添加的任何扰动都必须能够抵抗图像的这些转换。除角度和距离外,其他环境因素还包括照明 / 天气条件的变化以及相机上或路标上存在的碎片。
空间限制。目前专注于数字图像的算法会将对抗性扰动添加到图像的所有部分,包括背景图像。然而,对于实体路牌,攻击者并不能操纵背景图像。此外,攻击者也不能指望有一个固定的背景图像,因为背景图像会根据观看摄像机的距离和角度而变化。
不易察觉性的物理限制。目前对抗性深度学习算法的一个优点是,它们对数字图像的扰动往往非常小,以至于人类观察者几乎无法察觉。然而,当把这种微小的扰动迁移到现实世界时,我们必须确保摄像机能够感知这些扰动。因此,对不可察觉的扰动是有物理限制的,并且取决于传感硬件。
制造误差。为了实际制造出计算得到的扰动,所有的扰动值都必须是可以在现实世界中复制实现的。此外,即使一个制造设备,如打印机,确实能够产生某些颜色,但也会有一些复制误差。
作者首先分析不考虑其它物理条件的情况下生成单一图像扰动的优化方法,然后再考虑在出现上述物理世界挑战的情况下如何改进算法以生成鲁棒的物理扰动。
单一图像优化问题表述为:在输入 x 中加入扰动δ,使扰动后的实例 x’=x+δ能够被目标分类器 f_θ(·)错误分类:
其中,H 为选定的距离函数,y * 为目标类别。为了有效解决上述约束性优化问题,作者利用拉格朗日松弛形式重新表述上式:
其中,J(·,·)为损失函数,其作用是衡量模型的预测和目标类别标签 y * 之间的差异。λ为超参数,用于控制失真的正则化水平。作者将距离函数 H 表征为 ||δ||_p,即δ的 Lp 范数。
接下来,作者具体讨论如何修改目标函数以考虑物理环境条件的影响。首先,对包含目标对象 o 的图像在物理和数字变换下的分布进行建模 X^V 。我们从 X^V 中抽出不同的实例 x_i。一个物理扰动只能添加到 x_i 中的特定对象 o。具体到路标分类任务中,我们计划控制的对象 o 是停车标志。
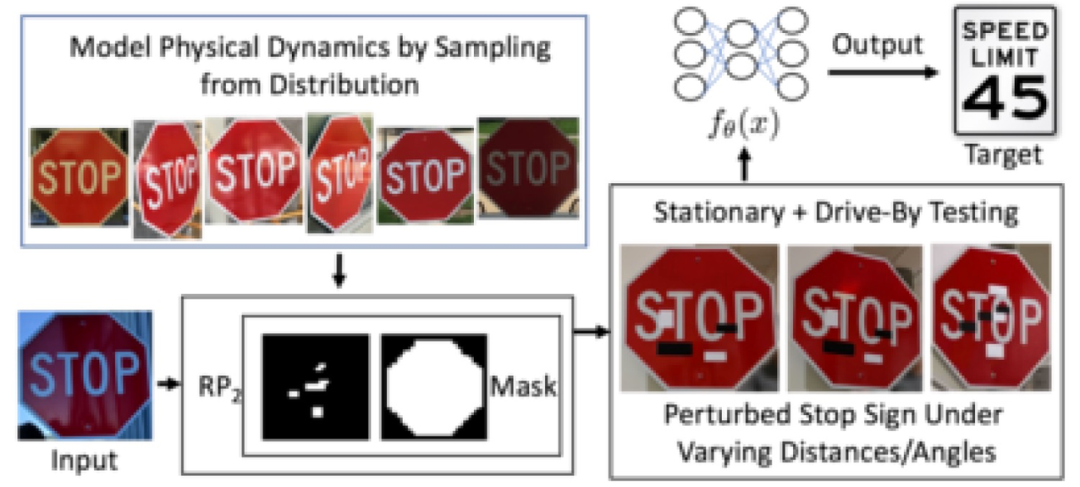
为了更好地捕捉变化的物理条件的影响,作者通过生成包含实际物理条件变化的实验数据以及合成转换,从 X^V 中对实例 x_i 进行采样。图 3 中给出了以道路标识为例的鲁棒物理攻击(Robust Physical Perturbations ,RP2)过程示例。
图 3. RP2 示例。输入一个目标停止标志。RP2 从一个模拟物理动态的分布中取样(在本例中是不同的距离和角度),并使用一个掩模将计算出的扰动投射到一个类似于涂鸦的形状上。攻击者打印出所产生的扰动,并将其贴在目标停止标志上
本文所讨论的道路标志的物理条件涉及在各种条件下拍摄道路标志的图像,如改变距离、角度和光照等。而对于合成转换,作者随机裁剪图像中的物体,改变其亮度,并增加空间变换以模拟其他可能的条件。为了确保扰动只适用于目标对象的表面区域 o(考虑到空间限制和对不可知性的物理限制),作者引入了一个掩模。该掩模的作用是将计算出的扰动投射到物体表面的一个物理区域(如路标)。除了实现空间定位外,掩模还有助于生成对人类观察者来说可见但不明显的扰动。为了做到这一点,攻击者可以将掩模塑造得像一个涂鸦—- 一种在大街上很常见的破坏行为。从形式上看,将扰动掩模表征为一个矩阵 M_x,其尺寸与路标分类器的输入尺寸相同。M_x 在没有添加扰动的区域为“0”,在优化期间添加扰动的区域中为“1”。作者表示,在他们进行实验的过程中发现掩模的位置对攻击的有效性是有影响的。因此,作者假设,从分类的角度来看物体的物理特征有强有弱,因此,可以将掩模定位在攻击薄弱的地方。具体来说,作者使用下述方法来发现掩模位置。(1) 使用 L1 正则化计算扰动,并使用占据整个道路标志表面区域的掩模。L1 使优化器倾向于稀疏的扰动向量,因此将扰动集中在最脆弱的区域。对所产生的扰动进行可视化处理,为掩模的放置位置提供指导。(2) 使用 L2 重新计算扰动,并将掩模定位在先前步骤中确定的脆弱区域上。
考虑到在实际应用中会存在制造误差,作者在目标函数中增加了一个额外的项,该项用来模拟打印机的颜色复制误差。给定一组可打印的颜色(RGB 三元组)P 和一组在扰动中使用的、需要在物理世界中打印出来的(唯一的)RGB 三元组 R(δ),利用下式计算不可打印性得分 non-printability score (NPS):
这里我们用函数 T_i( )来表示对齐函数,它将物体上的变换映射到扰动的变换上。
最后,攻击者打印出优化结果,剪下扰动(M_x),并将其放到目标对象 o 上。
实验构建了两个用于路标分类的分类器,执行的是标准的裁剪 - 重新确定大小 - 分类的任务流程。第一个分类器 LISA-CNN 对应的实验训练图像来自于 LISA,一个包含 47 个不同道路标志的美国交通标志数据集。不过,这个数据集并不平衡,导致不同标志的表述有很大差异。为了应对这个问题,作者根据训练实例的数量,选择了 17 个最常见的标志。实验中使用的深度学习 LISA-CNN 的架构由三个卷积层和一个 FC 层组成。它在测试集上的准确度为 91%。
第二个分类器是 GTSRB-CNN,它是在德国交通标志识别基准(GTSRB)上训练得到的。深度学习方法使用了一个公开的多尺度 CNN 架构,该架构在路标识别方面表现良好。由于作者在实际实验中无法获得德国的停车标志,因此使用 LISA 中的美国停车标志图像替换了 GTSRB 的训练、验证和测试集中的德国停车标志。GTSRB-CNN 在测试集上准确度为 95.7%。当在作者自己构建的 181 个停车标志图像上评估 GTSRB-CNN 时,它的准确度为 99.4%。
作者表示,据他所知,目前还没有评估物理对抗性扰动的标准化方法。在本实验中,作者主要考虑角度和距离因素,因为它们是本文所选的用例中变化最快的元素。靠近标志的车辆上的相机以固定的时间间隔拍摄一系列图像。这些图像的拍摄角度和距离不同,因此可以改变任何特定图像中的细节数量。任何成功的物理扰动必须能够在一定的距离和角度范围内引起有针对性的错误分类,因为车辆在发出控制器动作之前,可能会对视频中的一组帧(图像)进行投票确定。在该实验中没有明确控制环境光线,从实验数据可以看出,照明从室内照明到室外照明都有变化。本文实验设计借鉴物理科学的标准做法,将上述物理因素囊括在一个由受控的实验室测试和现场测试组成的两阶段评估中。
静态(实验室)测试
。主要涉及从静止的、固定的位置对物体的图像进行分类。
1. 获得一组干净的图像 C 和一组在不同距离、不同角度的对抗性扰动图像。使用 c^(d,g)表示从距离 d 和角度 g 拍摄的图像。摄像机的垂直高度应保持大致不变。当汽车转弯、改变车道或沿着弯曲的道路行驶时,摄像机相对于标志的角度通常会发生变化。
其中,d 和 g 表示图像的相机距离和角度,y 是地面真值,y 是目标攻击类别。
注意,只有当具有相同相机距离和角度的原始图像 c 能够正确分类时,引起错误分类的图像 A(c)才被认为是成功的攻击,这就确保了错误分类是由添加的扰动而不是其他因素引起的。
驾车(现场)测试。
作者在一个移动的平台上放置一个摄像头,并在真实的驾驶速度下获取数据。在本文实验中,作者使用的是一个安装在汽车上的智能手机摄像头。
1. 在距离标志约 250 英尺处开始录制视频。实验中的驾驶轨道是直的,没有弯道。以正常的驾驶速度驶向标志,一旦车辆通过标志就停止记录。实验中,速度在 0 英里 / 小时和 20 英里 / 小时之间变化。这模拟了人类司机在大城市中接近标志的情况。
2. 对 "Clean" 标志和施加了扰动的标志按上述方法进行录像,然后应用公式计算攻击成功率,这里的 C 代表采样的帧。
由于性能限制,自主车辆可能不会对每一帧进行分类,而是对每 j 个帧进行分类,然后进行简单的多数投票。因此,我们面临的问题是确定帧(j)的选择是否会影响攻击的准确性。在本文实验中使用 j = 10,此外,作者还尝试了 j=15。作者表示,这两种取值情况下没有观察到攻击成功率的任何明显变化。作者推断,如果这两种类型的测试都能产生较高的成功率,那么在汽车常见的物理条件下,该攻击很可能是成功的。
作者通过在 LISA-CNN 上生成三种类型的对抗性示例来评估算法的有效性(测试集上准确度为 91%)。表 1 给出了实验中用到的静止的攻击图像的样本示例。
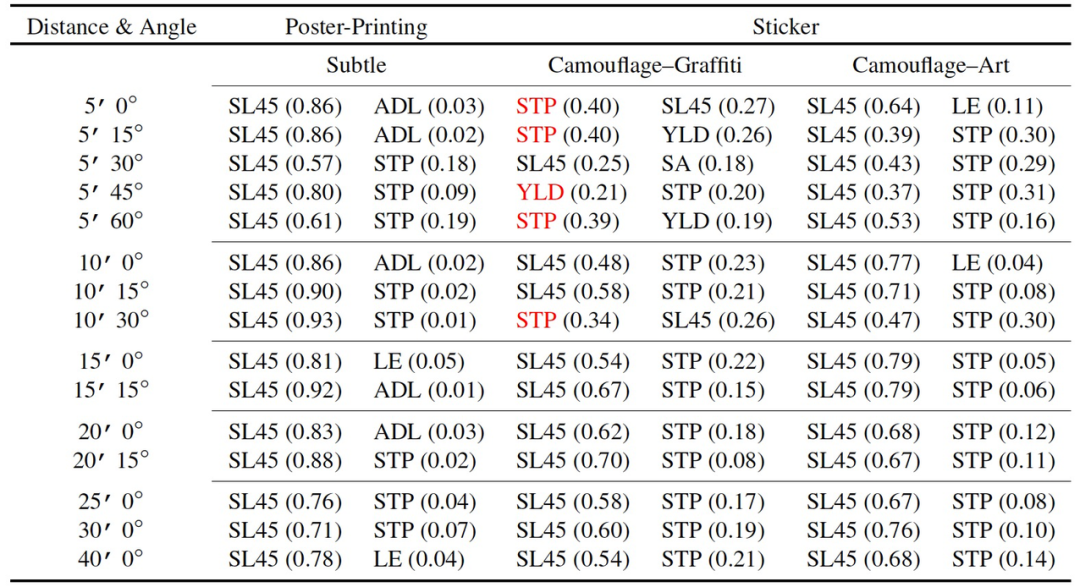
表 1. 针对 LISA-CNN 和 GTSRB-CNN 的物理对抗性样本示例
对象受限的海报打印攻击(Object-Constrained Poster-Printing Attacks)。实验室使用的是 Kurakin 等人提出的攻击方法[4]。这两种攻击方法的关键区别在于,在本文攻击中,扰动被限制在标志的表面区域,不包括背景,并且对大角度和距离的变化具有鲁棒性。根据本文的评估方法,在实验 100% 的图像中停车标志都被错误地归类为攻击的目标类别(限速 45)。预测被操纵的标志为目标类别的平均置信度为 80.51%(表 2 的第二列)。
贴纸攻击(Sticker Attacks),作者还展示了通过将修改限制在类似涂鸦或艺术效果的区域中,以贴纸的形式产生物理扰动的有效性。表 1 的第四列和第五列给出了这类图像样本,表 2(第四列和第六列)给出了实验成功率与置信度。在静止状态下,涂鸦贴纸攻击达到了 66.67% 的定向攻击成功率,伪装艺术效果贴纸攻击则达到了 100% 的定向攻击成功率。
表 2. 在 LISA-CNN 上使用海报印刷的停车标志牌(微小攻击)和真正的停车标志牌(伪装的涂鸦攻击,伪装的艺术效果攻击)的有针对性的物理扰动实验结果。对于每幅图像,都显示了前两个标签和它们相关的置信度值。错误分类的目标是限速 45。图例:SL45 = 限速 45,STP = 停车,YLD = 让步,ADL = 增加车道,SA = 前方信号,LE = 车道尽头
作者还对停车标志的扰动进行了驾车测试。在基线测试中,从一辆行驶中的车辆上记录了两段清洁停车标志的连续视频,在 k = 10 时进行帧抓取,并裁剪标志。此时,所有帧中的停止标志都能够正确分类。同样用 k=10 来测试 LISA-CNN 的扰动。本文攻击对海报攻击实现了 100% 的目标攻击成功率,而对伪装抽象艺术效果攻击的目标攻击成功率为 84.8%。见表 3。
表 3. LISA-CNN 的驾车测试总结。在基线测试中,所有的帧都被正确地分类为停车标志。在所有的攻击案例中,扰动情况与表 2 相同。手动添加了黄色方框进行视觉提示
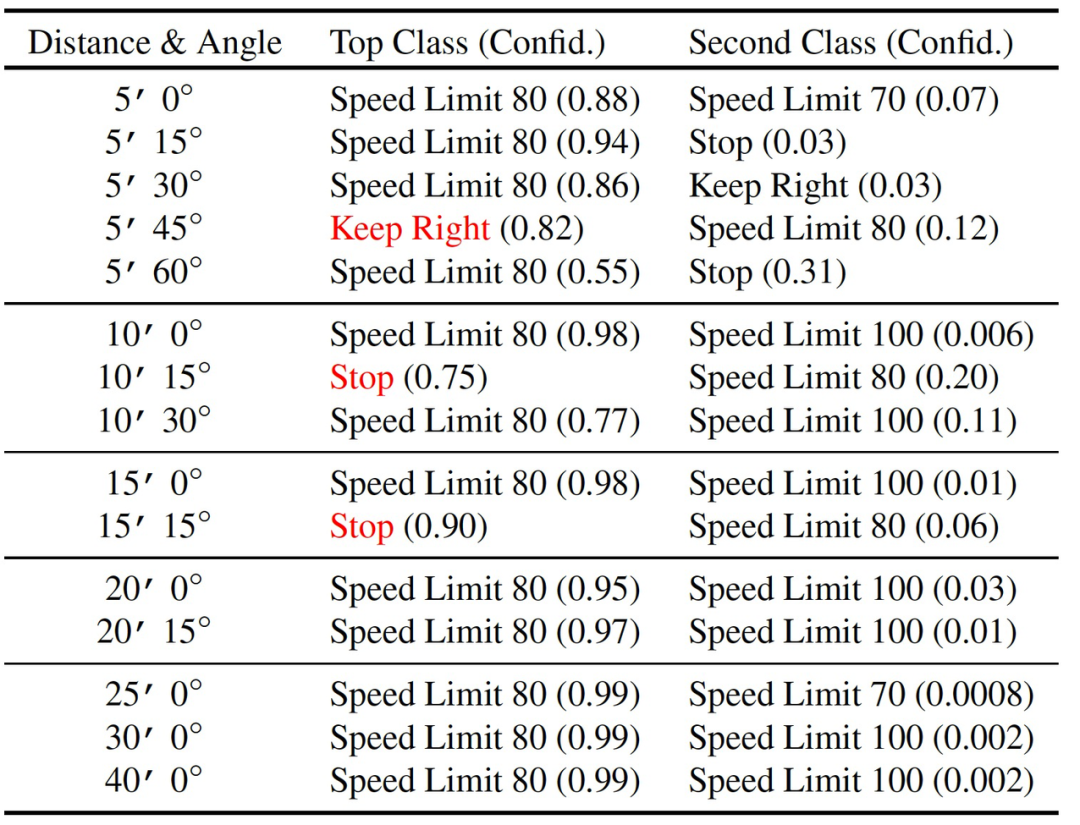
为了展示本文所提出的攻击算法的多功能性,作者为 GTSRB-CNN 创建并测试了攻击性能(测试集上准确度为 95.7%)。表 1 中最后一列为样本图像。表 4 给出了攻击结果—在 80% 的静止测试条件下,本文提出的攻击使分类器相信停止标志是限速 80 的标志。根据本文评估方法,作者还进行了驾车测试(k=10,两个连续的视频记录),最终攻击在 87.5% 的时间里成功欺骗了分类器。
表 4. 对 GTSRB-CNN 的伪装艺术效果攻击。有针对性的攻击成功率为 80%(真实类别标签:停止,目标:限速 80)
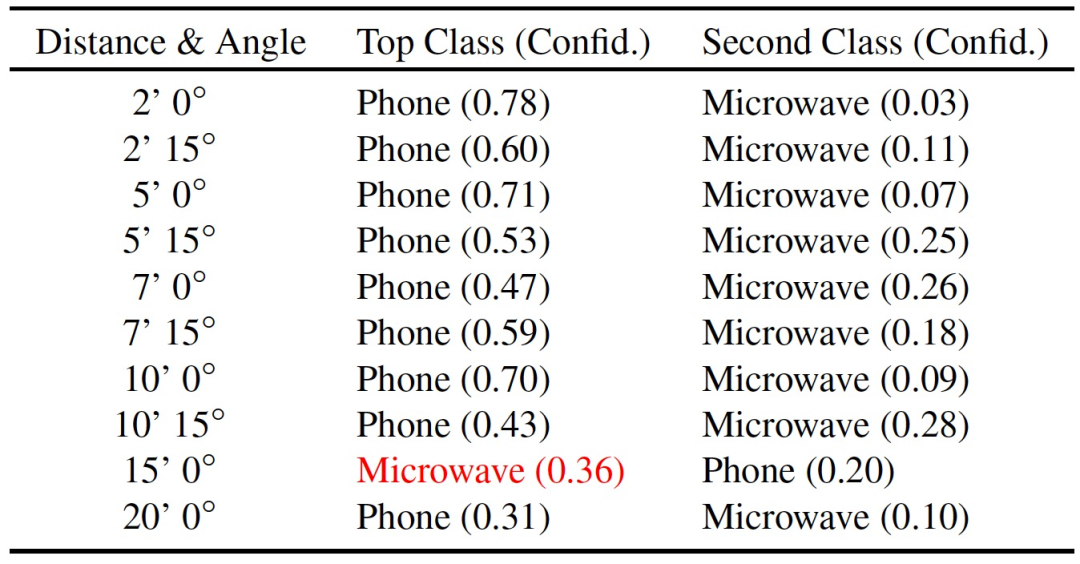
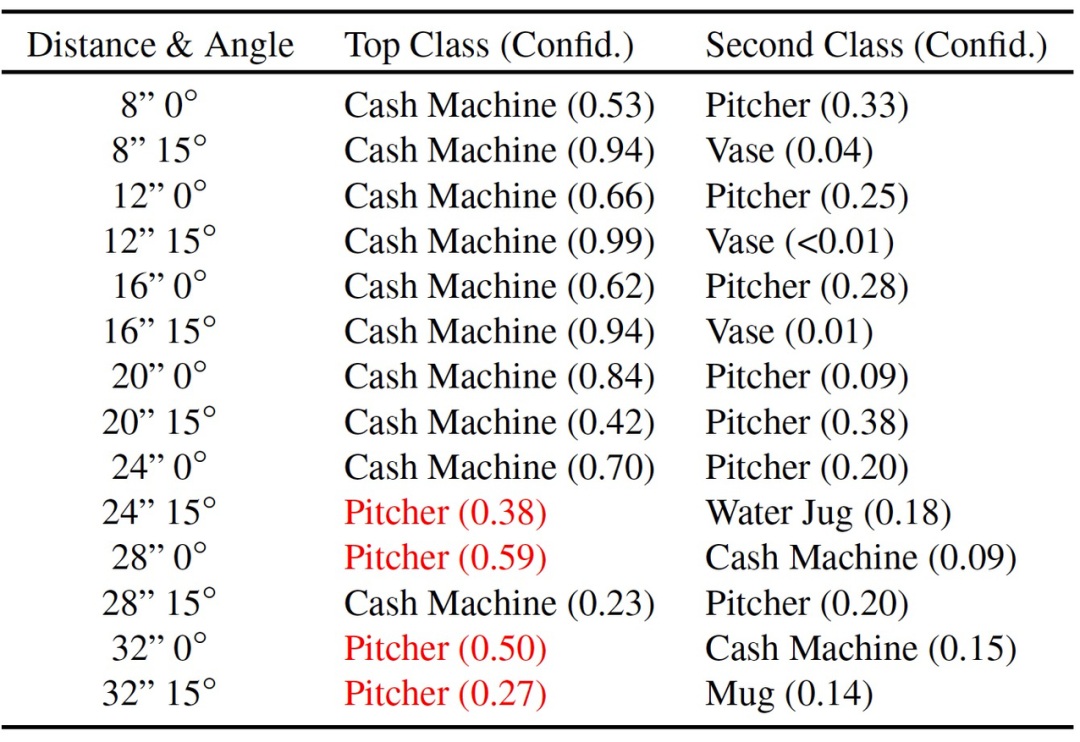
最后,为了证明 RP2 的通用性,作者使用两个不同的物体,一个微波炉和一个咖啡杯,计算了标准 Inception-v3 分类器的物理扰动情况。作者选择了贴纸攻击方法,因为使用海报攻击方法为物体打印一个全新的表面很容易引起人的怀疑。由于杯子和微波炉的尺寸比路标小,作者减少了使用的距离范围(例如,咖啡杯高度 - 11.2 厘米,微波炉高度 - 24 厘米,右转标志高度 - 45 厘米,停止标志 - 76 厘米)。表 5 给出了对微波炉的攻击结果,表 6 则给出了对咖啡杯的攻击结果。对于微波炉,目标攻击的成功率是 90%。对于咖啡杯,目标攻击成功率为 71.4%,非目标成功率为 100%。
表 5. 对 Inception-v3 分类器的贴纸扰动攻击。原始分类是微波,攻击目标是电话
表 6. 对 Inception-v3 分类器的贴纸扰动攻击。原始分类是咖啡杯,攻击目标是提款机
黑盒攻击。
考虑到对目标分类器的网络结构和模型权重的访问,RP2 可以产生各种强大的物理扰动来欺骗分类器。通过研究像 RP2 这样的白盒攻击,我们可以分析使用最强攻击者模型的成功攻击的要求,并更好地指导未来的防御措施。在黑盒环境下评估 RP2 是一个开放的问题。
图像裁剪和攻击性检测器。
在评估 RP2 时,作者每次在分类前都会手动控制每个图像的裁剪。这样做是为了使对抗性图像与提供给 RP2 的清洁标志图像相匹配。随后,作者评估了使用伪随机裁剪的伪装艺术效果攻击,以保证至少大部分标志在图像中。针对 LISA-CNN,我们观察到平均目标攻击率为 70%,非目标攻击率为 90%。针对 GTSRB-CNN,我们观察到平均目标攻击率为 60%,非目标攻击率为 100%。作者在实验中考虑非目标攻击的成功率,是因为导致分类器不输出正确的交通标志标签仍然是一种安全风险。虽然图像裁剪对目标攻击的成功率有一定的影响,但作者在其它工作中的研究结果表明,RP2 的改进版可以成功地攻击物体检测器,在这种情况下就不需要再进行裁剪处理了[5]。
2、LanCe: 针对嵌入式多媒体应用的物理对抗性攻击的
全面和轻量级 CNN 防御方法[2]
与关注 “攻击” 的上一篇文章不同,这篇文章关注的是“防御”。本文提出了:LanCe—一种全面和轻量级的 CNN 防御方法,以应对不同的物理对抗性攻击。通过分析和论证 CNN 存在的漏洞,作者揭示了 CNN 的决策过程缺乏必要的定性语义辨别能力(qualitative semantics distinguishing ability):输入的非语义模式可以显著激活 CNN 并压倒输入中的其它语义模式,其中,语义模式是指表示语句成分之间的语义关系的抽象格式,而非语义模式是指不包含任何语义关系信息的抽象格式。利用对抗性攻击的特征不一致性,作者增加了一个自我验证阶段来改进 CNN 的识别过程。回顾图 1,对于每张输入图像,经过一次 CNN 推理后,验证阶段将定位重要的激活源(绿圈),并根据预测结果计算出输入语义与预期语义模式的不一致性(右圈)。一旦不一致性值超过预定的阈值,CNN 将进行数据恢复过程以恢复输入图像。我们的防御方法涉及最小的计算组件,可以扩展到基于 CNN 的图像和音频识别场景。
解释和假设。
在一个典型的图像或音频识别过程中,CNN 从原始输入数据中提取特征并得出预测结果。然而,当向原始数据注入物理对抗性扰动时,CNN 将被误导出一个错误的预测结果。为了更好地解释这个漏洞,作者以一个典型的图像物理对抗性攻击—对抗性补丁攻击为例进行分析。
在图 1 中,通过与原始输入的比较,我们发现一个对抗性补丁通常在颜色 / 形状等方面没有限制约束。这样的补丁通常会牺牲语义结构,从而导致明显的异常激活,并压倒其他输入模式的激活。因此,作者提出了一个假设:
CNN 缺乏定性的语义辨别能力,在 CNN 推理过程中可以被非语义的对抗性补丁激活。
假设验证。
根据上述假设,输入的非语义模式会导致异常的激活,而输入的语义模式会产生正常的激活。作者提出通过调查 CNN 中每个神经元的语义来评估这种差异,并引入一种可视化的
CNN 语义分析方法—激活最大化可视化
(Activation Maximization Visualization,AM)。AM 可以生成一个 pattern,将每个神经元最活跃的语义输入可视化。图案 V((N_i)^l)的生成过程可以被看作是向 CNN 模型合成一个输入图像,使第 l 层中的第 i 个神经元(N_i)^l 的激活度最大化。该过程可以表征为:
其中,(A_i)^l(X)为输入图像 X 的(N_i)^l 的激活,(A_i)^l 表征第 l 层的第 i 个神经元对应的激活,(N_i)^l 为第 l 层的第 i 个神经元,η为梯度下降步长。
图 4 展示了使用 AM 的可视化输入的语义模式。由于原始的 AM 方法是为语义解释而设计的,在生成可解释的可视化模式时,涉及许多特征规定和手工设计的自然图像参考。因此,我们可以得到图 4(a)中平均激活幅度值为 3.5 的三个 AM 模式。这三种模式中的对象表明它们有明确的语义。然而,当我们在 AM 过程中去除这些语义规定时,我们得到了三种不同的可视化 patterns,如图 4(b)所示。我们可以发现,这三个 patterns 是非语义性的,但它们有明显的异常激活,平均幅值为 110。这一现象可以证明作者的假设,即
CNN 神经元缺乏语义辨别能力,可以被输入的非语义模式显著激活。
不一致性识别。
为了识别用于攻击检测的输入的非语义模式,我们通过比较自然图像识别和物理对抗性攻击,检查其在 CNN 推理过程中的影响。图 5 展示了一个典型的基于对抗性补丁的物理攻击。左边圆圈中的图案是来自输入图像的主要激活源,右边的条形图是最后一个卷积层中的神经元的激活。从输入模式中我们识别出原始图像中的对抗性补丁和主要激活源之间的显著差异,称为
输入语义不一致
(Input Semantic Inconsistency)。从预测激活量级方面,我们观察到对抗性输入和原始输入之间的另一个区别,即
预测激活不一致
(Prediction Activation Inconsistency)。
不一致性度量的表述。
作者进一步定义两个指标来表述上述两个不一致的程度。
1)输入语义不一致度量:
该度量用于衡量非语义对抗性补丁与自然图像的语义局部输入模式之间的输入语义不一致性。具体定义为:
其中,P_pra 和 P_ori 分别代表来自对抗性输入和原始输入的输入模式(input patterns)。Φ:(A_i)^l(p)和Φ:(A_i)^l(o)分别表征由对抗性补丁和原始输入产生的神经元激活的集合。R 将神经元的激活映射到主要的局部输入模式。S 代表相似性指标。
2)预测激活不一致度量:
第二个不一致度量指标是在激活层面上,它用于衡量最后一个卷积层中对抗性输入和原始输入之间的激活幅度分布的不一致性。我们也使用一个类似的指标来衡量,具体如下:
其中,f_pra 和 I_ori 分别代表最后一个卷积层中由对抗性输入和原始输入数据产生的激活的幅度分布。
对于上述两个不一致度量中使用到的信息,我们可以很容易地得到 P_pra 和 f_pra,因为它们来自于输入数据。然而,由于自然输入数据的多样性,P_ori 和 f_ori 并不容易得到。因此,我们需要合成能够提供输入的语义模式和激活量级分布的标准输入数据。可以从标准数据集中获得每个预测类别的合成输入数据,以及,通过向 CNN 输入一定数量的标准数据集,我们可以记录最后一个卷积层的平均激活幅度分布。此外,我们可以定位每个预测类别的主要输入的语义模式。
2.1.3 基于 CNN 自我验证和数据恢复的物理对抗性攻击防御
上述两个不一致展示了物理对抗性攻击和自然图像识别之间的区别,即输入模式和预测激活。通过利用不一致性指标,作者提出了一种防御方法,其中包括 CNN 决策过程中的自我验证和数据恢复。具体来说,整个方法流程描述如下。
自我验证。
(1)首先将输入项输入到 CNN 推理中,获得预测类别结果。(2) 接下来,CNN 可以从实际输入中定位主要激活源,并在最后一个卷积层中获得激活。(3)然后,CNN 利用所提出的指标来衡量实际输入与预测类别的合成数据之间的两个不一致指标。(4) 一旦任何一个不一致指标超过了给定的阈值,CNN 将认为该输入是一个对抗性输入。
数据恢复。
(5) 在自我验证阶段检测到物理对抗性攻击后,进一步应用数据恢复方法来恢复被攻击的输入数据。具体来说,作者利用图像修复和激活去噪方法分别来恢复输入的图像和音频。
主要激活模式定位。
对于图像物理对抗性攻击的防御,主要依赖于输入模式层面的
输入语义不一致
。因此,作者采用 CNN 激活可视化方法—类别激活映射(Class Activation Mapping,CAM)来定位输入图像的主要激活源 [8]。令 A_k(x, y) 表示在空间位置 (x, y) 的最后一个卷积层的第 k 个激活值。我们可以计算出最后一个卷积层中空间位置 (x, y) 的所有激活的总和,即:
其中,K 是最后一个卷积层中激活的总数。A_T(x, y)的值越大,表明输入图像中相应空间位置 (x, y) 的激活源对分类结果越重要。
不一致推导。
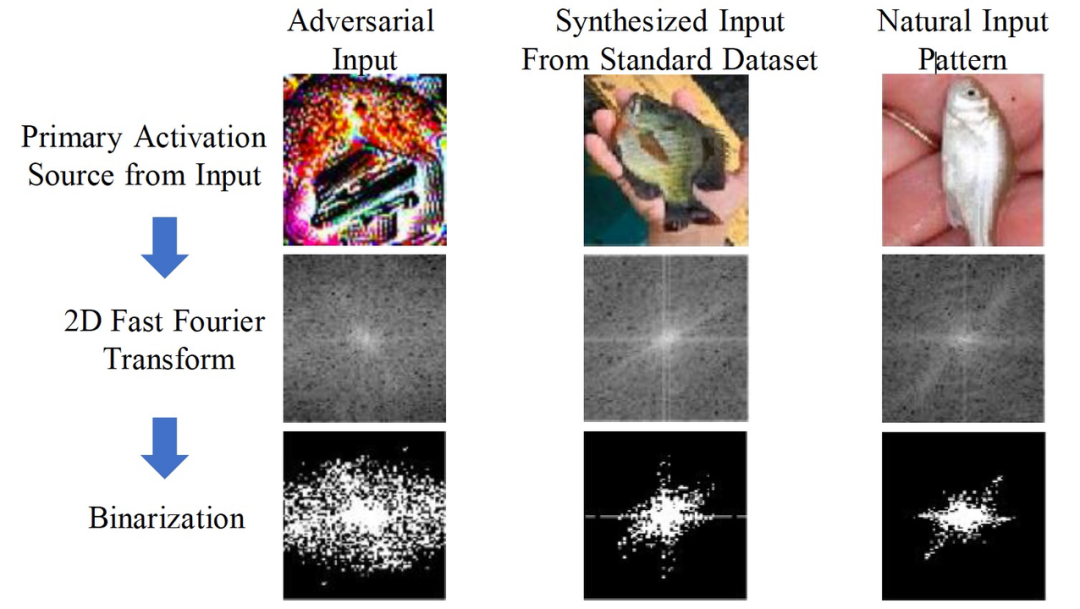
根据初步分析,输入的对抗性补丁比自然输入的语义模式包含更多的高频信息。因此,作者用一系列的变换来转换这些 patterns,如图 6 所示。经过二维快速傅里叶变换(2D-FFT)和二进制转换,我们可以观察到对抗性输入和语义合成输入之间的显著差异。
作者将 S(I_pra, I_ori)替换为 Jaccard 相似性系数(Jaccard Similarity Coefficient,JSC),并提出如下图像不一致性指标:
其中,I_exp 是具有预测类别的合成语义模式,P_pra ∩ P_exp 为 P_pra 和 P_exp 的像素值都等于 1 的像素数。基于上述不一致性指标,作者提出了具体的防御方法,包括自我验证和图像恢复两个阶段。整个过程在图 7 中描述。
检测的自我验证。
在自我验证阶段,应用 CAM 来定位每个输入图像中最大模型激活的源头位置。然后对图像进行裁剪,以获得具有最大激活度的 pattern。在语义测试期间,计算 I_pra 和 I_exp 之间的不一致性。如果该不一致性指标高于预定义的阈值,我们认为检测到了一个对抗性输入。
图像的数据恢复。
检测到对抗性补丁后,通过直接从原始输入数据中删除补丁的方式来进行图像数据恢复。在该案例中,为了确保轻量级的计算工作量,作者利用最近邻插值 --- 一种简单而有效的图像插值技术来修复图像并消除攻击效果。具体来说,对于对抗性补丁中的每个像素,利用该像素周围八个像素的平均值取代该像素。插值处理后,将恢复的图像反馈给 CNN,再次进行预测。通过以上步骤,我们可以在 CNN 推理过程中保护图像的物理对抗性攻击。
不一致推导:
作者利用预测激活的不一致性来检测音频中的物理对抗性攻击,即,衡量预测类别相同的实际输入和合成数据之间的激活幅度分布不一致性指标。作者利用皮尔逊相关系数(Pearson Correlation Coefficient,PCC)定义不一致度量如下:
其中,I_pra 和 I_exp 分别代表最后一个卷积层对实际输入和合成输入的激活。μ_a 和μ_o 表示 f_pre 和 f_exp 的平均值,σ_pra 和σ_exp 是标准差,E 表示总体期望值。
自我验证的检测。
进一步的,将自我验证应用于 CNN 的音频物理对抗性攻击。首先,通过用标准数据集测试 CNN,获得最后一个卷积层中每个可能的输入词的激活值。然后,计算不一致度量指标 D(I_pra, I_exp)。如果模型受到对抗性攻击,D(I_pra, I_exp)会大于预先定义的阈值。作者表示,根据他们用各种攻击进行的初步实验,对抗性输入的 D(I_pra, I_exp)通常大于 0.18,而自然输入的 D(I_pra, I_exp)通常小于 0.1。因此,存在一个很大的阈值范围来区分自然和对抗性的输入音频,这可以有利于我们的准确检测。
音频数据恢复。
在确定了对抗性的输入音频后,对这部分音频进行数据恢复以满足后续应用的需要。作者提出了一个新的解决方案—"激活去噪" 作为音频数据的防御方法,其目标是从激活层面消除对抗性影响。激活去噪利用了上述最后一层的激活模式,这些模式与确定的预测标签有稳定的关联性。对抗性音频数据恢复方法如图 8 所示。基于检测结果,我们可以识别错误的预测标签,并在最后一层获得错误类别的标准激活模式。然后我们可以找到具有相同索引的激活。这些激活最可能是由对抗性噪声引起的,并取代了原始激活。因此,通过压制这些激活就可以恢复原始激活。
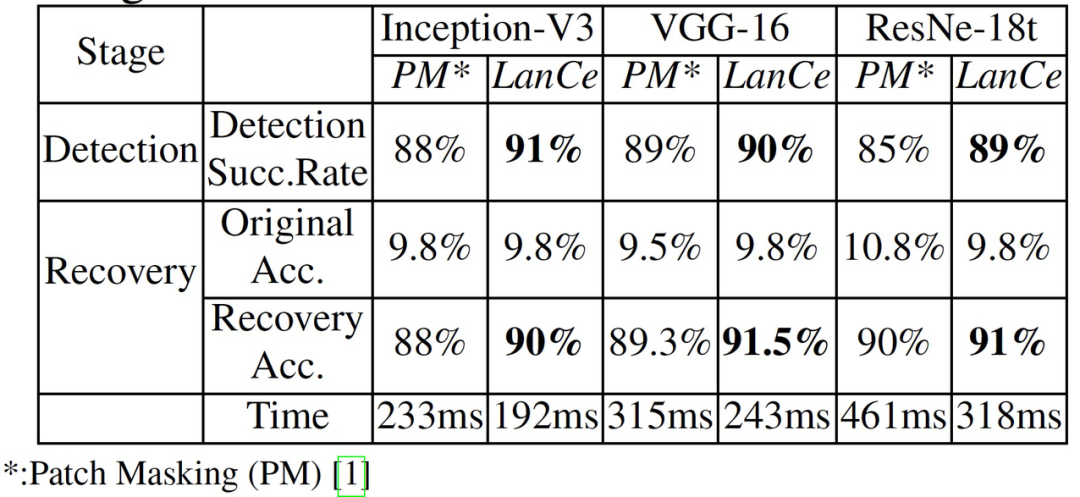
在本文实验中,作者使用 Inception-V3 作为基础模型生成对抗性补丁,然后利用由此生成的高迁移性的补丁攻击两个 CNN 模型:VGG-16 和 ResNet-18。然后将本文提出的防御方法应用于所有三个模型,并测试其检测和恢复的成功率。实验中的基准方法是 Patch Masking,这是一种最先进的防御方法[7]。不一致性的阈值设为 0.46。
表 7 给出了总体检测和图像恢复性能。在所有三个模型上,LanCe 的检测成功率始终高于 Patch Masking。进一步,本文提出的图像恢复方法可以帮助纠正预测,在不同的模型上获得了 80.3%~82% 的准确度改进,而 Patch Masking 的改进仅为 78.2% ~79.5%。
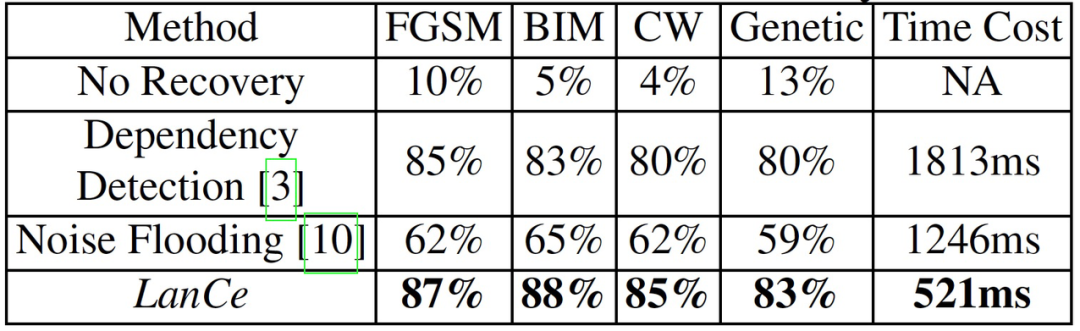
对于音频场景,作者在谷歌语音命令数据集上使用命令分类模型(Command Classification Model)进行实验。对抗性检测的不一致性阈值是通过网格搜索得到的,在本实验中设置为 0.11。作为比较,作者重新实现了另外两种最先进的防御方法:Dependency Detection [8]和 Multiversion[9]。
LanCe 对所有的音频物理对抗性攻击都能达到 92% 以上的检测成功率。相比之下,Dependency Detection 平均达到 89% 的检测成功率,而 Multiversion 的平均检测成功率只有 74%。然后,作者评估了 LanCe 的恢复性能。TOP-K 指数中的 K 值被设定为 6。由于 Multiversion[9]不能用于恢复,作者重新实现了另一种方法 Noise Flooding[10]作为比较。作者使用没有数据恢复的原始 CNN 模型作为基线方法。
表 8 给出了整体的音频恢复性能评估。应用本文提出的恢复方法 LanCe 后,预测准确率明显提高,从平均 8% 提高到了平均 85.8%,即恢复准确率为 77.8%。Dependency Detection 和 Noise Flooding 的平均准确率都较低,分别为 74% 和 54%。
3、SentiNet:针对深度学习系统的物理攻击检测[3]
这篇文章重点关注的是图像处理领域的物理攻击检测问题,具体是指针对图像的局部物理攻击,即将对手区域限制在图像的一小部分,生成 “对抗性补丁” 攻击。这种局部限制有利于设计鲁棒的且物理上可实现的攻击,具体攻击形式可以是放置在视觉场景中的对手对象或贴纸。反过来,这些类型的攻击通常使用无界扰动来确保攻击对角度、照明和其他物理条件的变化具有鲁棒性。局部物理攻击的一个缺点是,它们通常是肉眼可见和可检测的,但在许多情况下,攻击者仍然可以通过在自主环境中部署或伪装这些方式来逃避检测。
图 9 给出一个深度学习系统示例,该系统为人脸识别系统,其作用是解锁移动设备或让用户进入建筑物。场景包括了用户的脸和其他背景对象。传感器可以是返回场景数字图像的相机的 CCD 传感器。图像由预测用户身份的人脸分类器处理。如果用户身份有效,执行器将解锁设备或打开闸门。
图 9. 部署在真实环境中的物理攻击,使用物理模式和对象而不是修改数字图像
本文提出了一种针对视觉领域物理攻击检测的方法:SentiNet。SentiNet 的目标是识别会劫持模型预测的对手输入。具体而言,SentiNet 的设计目标是在无需事先了解攻击内容的情况下,保护网络免受对抗性样本、触发特洛伊木马和后门的攻击。SentiNet 的核心思想是利用对手错误分类行为来检测攻击。首先,SentiNet 使用模型可解释性和对象检测技术从输入场景中提取对模型预测结果影响最大的区域。然后,SentiNet 将这些提取的区域应用于一组良性测试输入,并观察模型的行为。最后,SentiNet 使用模糊技术将这些合成行为与模型在良性输入上的已知行为进行比较,以确定预测攻击行为。SentiNet 完整结构见图 10。
图 10. SentiNet 架构概述。使用输入的输出和类别生成掩模,然后将掩模反馈到模型中以生成用于边界分析和攻击分类的值
本文方法的第一步是在给定的输入上定位可能包含恶意对象的区域,即识别输入 x 中有助于模型预测 y 的部分。因为物理攻击很小并且是局部的,在不包含攻击部分的输入上评估模型可能能够恢复 x 的真实类别。
分段类别建议。
本文提出的攻击检测从识别一组可能由模型 f_m 预测的类别开始。第一类是实际预测,即 y=f_m(x)。通过对输入 x 进行分段,然后对每个分段上的网络进行评估来识别其他类别。Algorithm 1 给出了通过输入分段判断类别的算法。可以使用不同的方法分割给定的输入 x,包括滑动窗口和基于网络的区域建议等。本文方法使用了选择性搜索图像分割算法:选择性搜索根据在自然场景中发现的模式和边缘生成区域列表,然后,对每个给出的分段建议进行评估,并返回前 k 个置信度预测,其中 k 是 SentiNet 的配置参数。
掩模生成。
针对模型预测的解释和理解问题,在过去几年中已经提出了多种针对性的方法。其中一种方法是 “量化” 输入的单个像素的相关性。这种方法聚焦于单个像素,因此可能会生成非连续像素的掩模。而稀疏掩模则可能会丢失恶意对象的元素,并且不适用于模型测试阶段。另外一种替代方法不在单个像素上操作,而是尝试恢复模型用于识别同类输入的可分性图像区域。但是,其中许多方法需要对基本模型进行修改和微调,例如类别激活映射(Class Activation Mapping,CAM)[8],这些修改可能会改变模型的行为,甚至包括 SentiNet 执行检测并防止被利用的恶意行为。
作者表示,适合本文目标的方法是 Grad-CAM[9],这是一种模型解释技术,可以识别输入的连续空间区域,而不需要对原始模型进行修改。Grad-CAM 使用网络最后几层计算得到的梯度来计算输入区域的显著性。对于类别 c,Grad-CAM 计算模型输出 y^c 相对于模型最终汇聚层的 k 个特征图 A^k 的梯度(模型对类别 c 的 logit 得分),以得到(δ y^c)/(δ A^k)。每个过滤图的平均梯度值,或 "神经元重要性权重" 记作:
最后,按神经元的重要性加权处理特征图 A^k,并汇总以得到最终的 Grad-CAM 输出:
Grad-CAM 的输出是图像正向重要性的一个粗略热图,由于模型的卷积层和池化层的下采样处理,其分辨率通常比输入图像低。最后,通过对热图进行二值化处理,以最大强度的 15% 为阈值生成掩模。作者使用这个掩模来分割 salient 区域,以便进行下一步的工作。
精确的掩模生成。
尽管 Grad-CAM 可以成功地识别与对抗性目标相对应的鉴别性输入区域,但它也可能识别良性的 salient 区域。图 11 给出了一个说明性示例,Grad-CAM 为一个人脸识别网络生成的热图既覆盖了木马的触发补丁,也覆盖了原始的人脸区域。为了提高掩模准确性,作者提出需要对输入图像的选定区域进行额外预测。然后,对于每个预测,使用 Grad-CAM 来提取一个与预测最相关的输入区域的掩模。最后,结合这些额外的掩模来完善初始预测 y 的掩模。
图 11. 上一行:使用渐变 CAM 生成掩模。左图显示了与目标 “0” 类别相关的 Grad-CAM 热图,右图显示了覆盖了物理攻击以外区域的提取掩模。下一行:左图是相对于目标 “0” 类别的 Grad-CAM 热图,该行中间的图是对应于给定类别的 Grad-CAM
一旦得到了图片中可能存在的类别列表,我们就会划出与每个预测类别更相关的区域 x。为简单起见,作者假设每个输入只能包含一个恶意对象。Algorithm 2 给出了从 x 中提取输入区域的过程。
首先,使用 Grad-CAM 对输入的 x 和预测的 y 提取掩模,同时还为每一个建议的类别 y_p 提取一个掩模。在其他的建议类别上执行 Grad-CAM,可以让我们在对抗性攻击之外找到图像的重要区域。此外,由于对抗性区域通常与非目标类别呈负相关性,热图主动避免突出图像的对抗性区域。我们可以使用这些热图来生成二级掩模,通过减去掩模重叠的区域来改进原始掩模。这能够保证掩模只突出局部攻击,而不会突出图像中的其他 salient 区域。由图 11 我们可以看到使用这种方法生成了一个更精确的掩模,其中只包含了大部分对抗性区域。
攻击检测需要两个步骤。首先,如上所述,SentiNet 提取可能包含对抗性补丁的输入区域。然后,SentiNet 在一组良性图像上测试这些区域,以区分对抗性区域和良性区域。
测试
- 一旦定位了输入区域,SentiNet 就会观察该区域对模型的影响,以确定该区域是对手的还是良性的。为此,SentiNet 将可疑区域叠加在一组良性测试图像 X 上。将测试图像反馈到网络中,网络计算被欺骗的样本数量并用于对抗性图像。直观地说,可能欺骗模型的变异图像数量越多,疑似区域就越有可能是对抗性攻击。当恢复的掩模较小时,这种反馈技术能有效区分对抗性和良性输入,因为小的良性物体通常不能影响到网络的预测。然而,这种方法的一个问题是,一个覆盖了输入图像较大区域的掩模在叠加到其他图像上时,很可能会造成错误的分类。例如,考虑一个输入图像 x 的较大掩模,当叠加时,掩模内的特征可能比外面的特征相关性更强,这就提高了将变异的测试输入分类为 y 的可能性。为了解决这一问题,作者引入了惰性模式(inert patterns),其作用是抑制掩模内部的特征,从而提高网络对掩模外特征的反应。
检测的决策边界
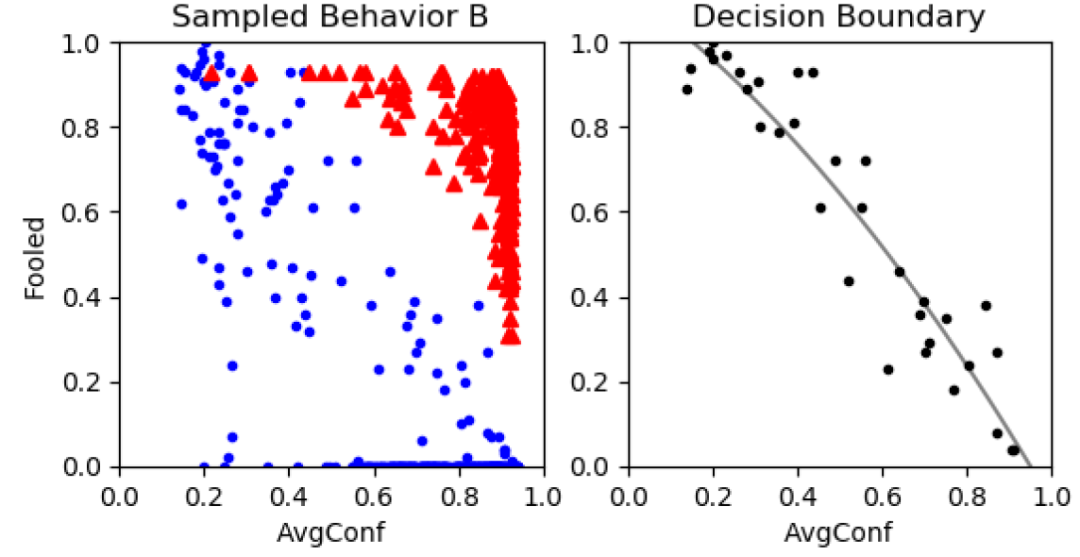
- 有了这两个指标(被欺骗的图像数量和平均惰性模式置信值),我们可以确定在哪些条件下输入的 x 是对抗性的。下一步,作者希望引入一种技术,使我们能够根据攻击无关的指标,将未见过的对抗性输入识别为攻击。图 12 给出一个示例,其中红色的三角点代表的是在对抗性样本中发现的指标,蓝色的圆点是根据清洁样本计算得到的。我们可以看到对抗性样本大多聚集在图中右上角的位置。
图 12. 边界检测示例,左侧,对抗性和良性指标分别被绘制成红色三角形和蓝色圆圈;右侧,来自采样点的曲线建议
作者提出,可以使用在清洁样本上收集到的度量来近似一个曲线,其中位于曲线函数之外的点可以被归类为对抗性攻击。具体的,通过提取 x 间隔的最高 y 值的点来收集目标点,然后使用非线性最小二乘法函数来拟合生成目标曲线。然后,使用近似曲线计算曲线和点之间的距离(使用线性近似的约束优化(the Constrained Optimization by Linear Approximation,COBYLA)方法)并确定该距离是否在由位于曲线之外的清洁样本的距离所估计的阈值之内,来实现对攻击的分类。具体的边界决策过程如 Algorithm 4 所示。
作者利用三个公共可用网络评估 SentiNet,其中包括两个受损网络和一个未受损网络。受损网络包括一个用于阅读标志检测的后门 Faster-RCNN 网络 [11] 以及一个用于人脸识别的 VGG-16 trojaned 网络[12]。未受损网络是在 Imagenet 数据集上训练的 VGG-16 网络[13]。此外,SentiNet 还需要一个良性测试图像集 X 和一个惰性模式 s 来生成决策边界。作者利用实验中所选网络的每个测试集 X 生成良性测试图像集,以及使用随机噪声作为惰性模式。SentiNet 利用 Tensorflow 1.5 为未受损网络、利用 BLVC Caffe 为 trojaned 网络以及利用 Faster-RCNN Caffe 为污染网络生成对抗补丁。为了能够并行生成类别建议,SentiNet 利用了由 Fast RCNN Caffe 版本实现的 ROI 池化层。最后,作者通过收集每次攻击的 TP/TN 和 FP/FN 比率从准确性和性能两个方面衡量 SentiNet 的有效性和鲁棒性。
首先,作者评估了 SentiNet 在保护选定的网络免受三种攻击的有效性,即后门、特洛伊木马触发器和对手补丁。在实验中,分别考虑了引入和未引入掩模改进的效果。对于对抗性补丁攻击,作者考虑了另一种变体,即攻击者同时使用多个补丁。实验整体评估结果见表 9 所示。
接下来,作者考虑攻击者已知 SentiNet 的存在及其工作机制情况下,可能避免 SentiNet 检测的情况。作者具体考虑了 SentiNet 的三个组件的情况:热图建议、类别建议和攻击分类。
本文方法的关键是能够使用 Grad-CAM 算法成功定位图像中的对抗性区域。Grad-CAM 算法生成 salient 区域的热图进而生成分类结果。一旦攻击破坏了 Grad-CAM 并影响区域的检测和定位,那么框架的后续组件将会失效。Grad-CAM 使用网络反向传播来衡量区域的重要性。因此,理论上我们可以使用有针对性的梯度扰动来修改热图输出。作者通过实验表明,在作者给出的防御背景下,Grad-CAM 对对抗性攻击是稳健的,Grad-CAM 对区域的捕捉能力并不会轻易被操纵。
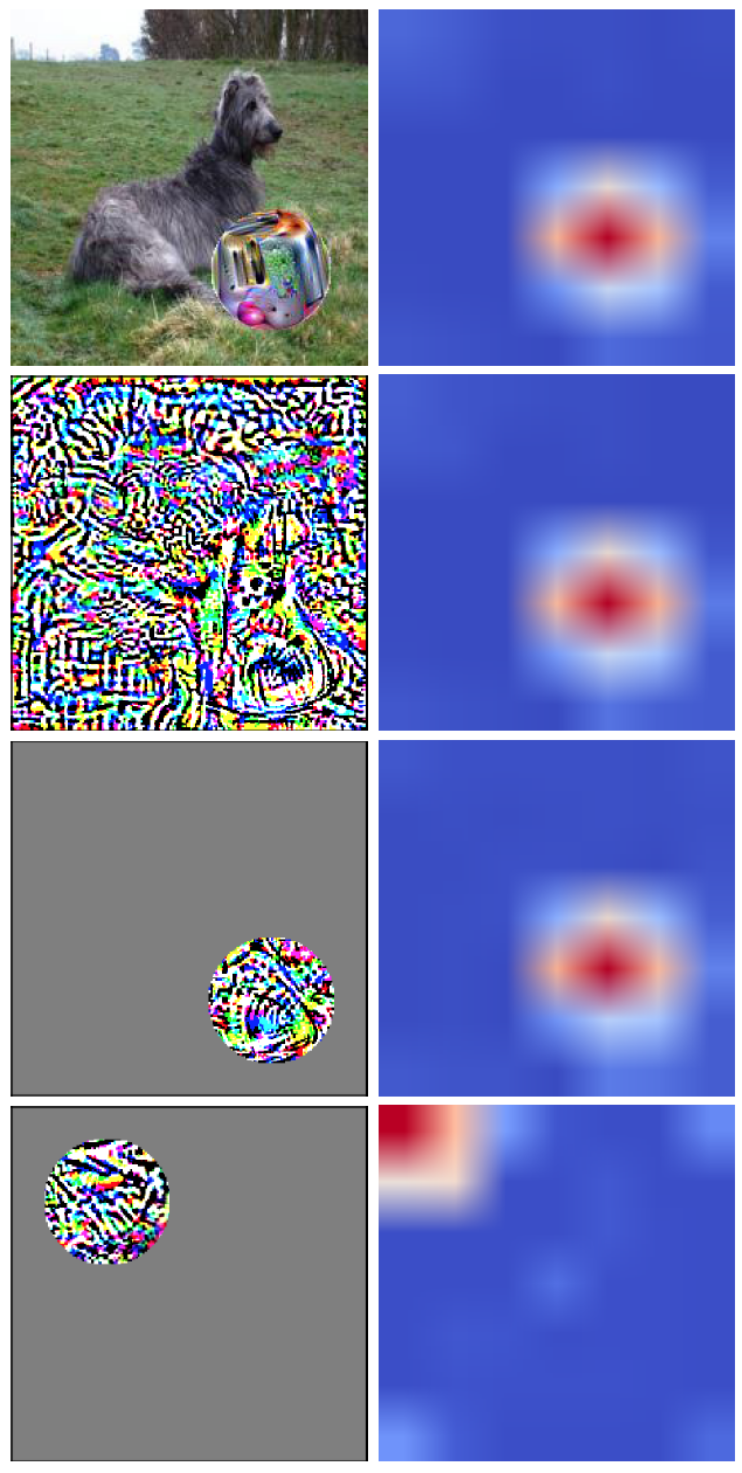
图 13 左上为一张狗的图像,上面覆盖着一个对抗性补丁。右侧为对目标类别 "toast" 的 Grad-CAM 热图。我们从随机噪声开始,其中没有任何 "toast" 类别的突出区域,对损失函数进行优化输入。图 13 证明了在收敛时生成的噪声的热图输出与原始热图在视觉上是一致的。这表明,Grad-CAM 的输出是可以通过梯度优化来精确操纵的。然而,为了发动这样的有效攻击,攻击者需要在整个图像上添加噪声,这在实际上是不可行的。
攻击者还有一种攻击策略:生成一个误导热图区域(heatmap region misdirection),在该图中增加一个不覆盖对手区域的区域,以扩大捕获的区域或完全规避检测。
攻击者也有可能通过误导热图区域,即热图提出一个不包括对抗区域的区域,以扩大定位的区域或完全避免检测。但是这种操作在对手对整幅图像添加扰动噪声时会失效,所以作者在实验中限定攻击者不能在局部攻击区域之外添加噪声,Grad-CAM 扰动也必须限制在对手区域中。因此,我们要考虑的威胁是攻击者可以在图像的一个区域中增加噪声,从而增加不相交区域中的 Grad-CAM 输出值。由图 13 给出的实验结果,如果噪声区域与我们想要修改的 Grad-CAM 位置重叠,我们就能够成功修改热图。图 13 还显示,如果噪声区域与目标 Grad-CAM 区域不相交,则 Grad-CAM 优化无法实现视觉相似性或与之等效的最终收敛损失。这些实验表明,局部噪声只会影响相应的 Grad-CAM 区域,同时表明不可能发生错误方向的攻击。
图 13. 计算每个输入上标签 “toaster” 的 Grad-CAM。第一行显示叠加在狗图像上的对抗性补丁的 Grad-CAM 输出。第二行为使用梯度扰动再现的 Grad-CAM 输出。第三行显示,如果补丁位于目标热图附近,仍然可以生成类似的热图。第四行显示,如果不能在目标 Grad-CAM 位置上附加干扰噪声,则无法直接影响 Grad-CAM 输出
类别建议模块是使用选择性搜索(Selective search)和一个根据包含 ROI 池化层的原始网络修改后得到的建议网络。选择性搜索是一种传统的图像处理算法,它使用基于图形的方法根据颜色、形状、纹理和大小分割图像。与 Faster-RCNN 中的网络生成建议机制不同,选择性搜索中不存在会被攻击者扰乱的梯度成分,也不存在会严重限制攻击者攻击机制的会污染的训练过程。本文的选择性搜索算法还设计用于捕获对手类别以外的类别建议,攻击者将无法影响对手区域以外的选择性搜索结果。此外,由于我们的建议网络使用原始网络权重,因此不会在原始网络和建议网络之间产生不同的行为。最后,攻击者攻击网络类别建议过程的动机是有限的,因为成功的攻击将破坏攻击检测的准确性,而不是破坏整个过程。由此,作者得出结论:类别建议机制是鲁棒的,因为各个组件的属性会共同抵抗扰动或污染攻击。
最后,通过分析攻击分类的鲁棒性,作者针对决策过程进行了实验论证。本文的分类过程没有使用梯度下降方法进行训练,这就避免了使用梯度扰动来误导分类的可能性。本文使用的阈值是根据可信数据集 X、X 误导概率和 X 平均置信度确定的二维数据点。其中,X 平均置信度利用模式 s 来计算。
如果对手能够操纵模型对惰性模式做出反应,那么他们就可以绕过防御后在良性输入和对手输入之间生成类似的输出。作者通过使用标准随机噪声模式和一个新的棋盘格模式(如图 14 所示),证明了我们可以保证模式 s 的隐私性。由表 9,我们可以看到随机噪声模式和棋盘格模式的 TP 和 TN 率在 ≤0.25% 范围内。此外,防御方始终能够通过使用梯度下降找到惰性模式,以最小化所有类别的响应置信度。只要模式 s 是保密的,SentiNet 的这个组件就是安全的。
图 14. 惰性模式:本文使用的惰性模式为左侧显示的随机噪声;可能使用的另一种模式是右侧的棋盘格模式
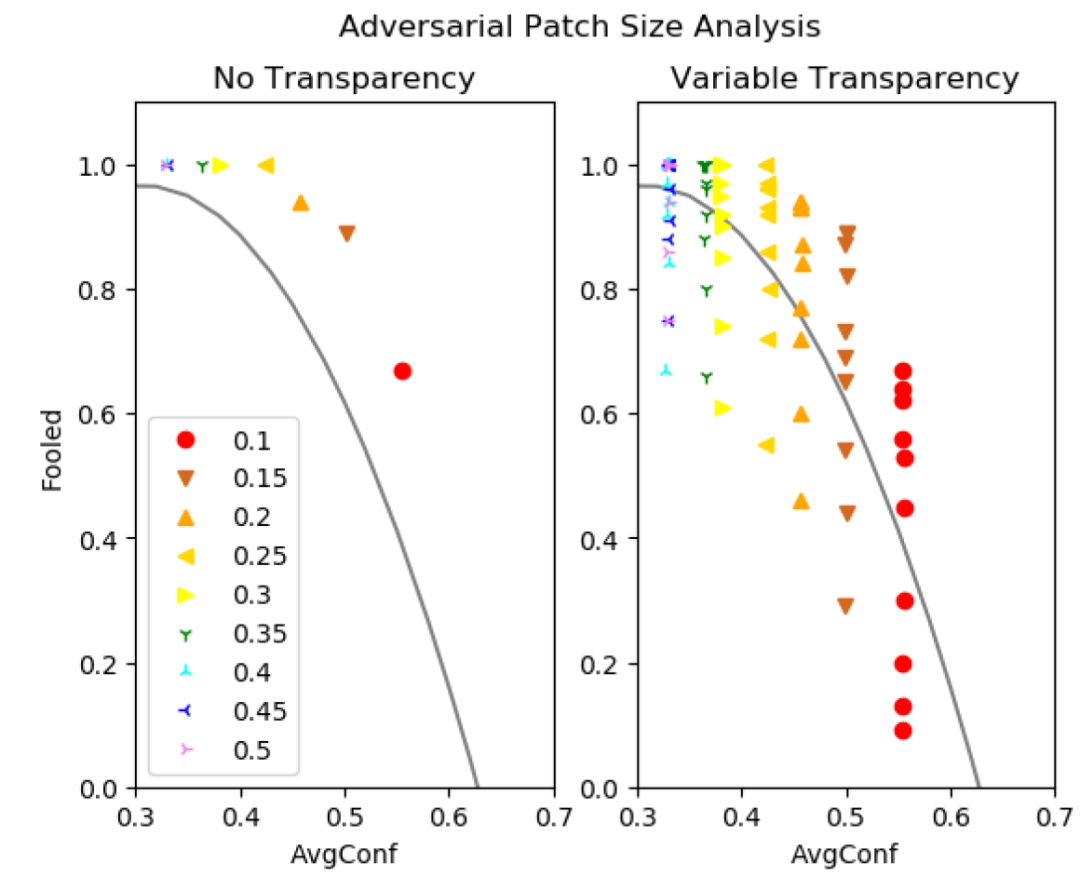
如果攻击者使用足够大的补丁,X 上的平均置信度将降低,从而降低防御的有效性。由图 15 可以看出,对于对抗性补丁,攻击的 avgConf 随着补丁大小的增加而下降。通过增加补丁的透明度,我们可以将攻击降低到阈值以下,同时保持非常高的攻击成功率。
我们在这篇文章中讨论了多媒体领域的物理攻击问题,包括图像领域、音频领域等。与算法攻击相比,在图像或音频上施加物理攻击的难度性低,进一步损害了深度学习技术的实用性和可靠性。我们选择了三篇文章从攻击和防御的角度分别进行了探讨,同时包括了图像领域和音频领域的攻击。由于物理攻击对于人类来说是易于发现的,所以从文章给出的实验结果来看,不同方法的防御效果都不错。不过,几篇文章中谈到的防御都是限定攻击类型的防御,如何对不可知的攻击进行有效防御仍值得进一步研究和探讨。
[1] Kevin Eykholt; Ivan Evtimov; Earlence Fernandes; Bo Li; Amir Rahmati; Chaowei Xiao; Atul Prakash; Tadayoshi Kohno; Dawn Son,Robust Physical-World Attacks on Deep Learning Visual Classification,CVPR 2018, https://ieeexplore.ieee.org/document/8578273(https://robohub.org/physical-adversarial-examples-against-deep-neural-networks/)
[2] Zirui Xu,Fuxun Yu; Xiang Chen,LanCe: A Comprehensive and Lightweight CNN Defense Methodology against Physical Adversarial Attacks on Embedded Multimedia Applications,25th Asia and South Pacific Design Automation Conference (ASP-DAC),2020,https://ieeexplore.ieee.org/document/9045584
[3] Chou E , F Tramèr, Pellegrino G . SentiNet: Detecting Physical Attacks Against Deep Learning Systems. 2020. https://arxiv.org/abs/1812.00292
[4] A. Kurakin, I. Goodfellow, and S. Bengio. Adversarial examples in the physical world. arXiv preprint arXiv:1607.02533, 2016.
[5] K. Eykholt, I. Evtimov, E. Fernandes, B. Li, D. Song, T. Kohno, A. Rahmati, A. Prakash, and F. Tramer. Note on Attacking Object Detectors with Adversarial Stickers. Dec. 2017.
[6] I. Goodfellow and et al., “Explaining and harnessing adversarial examples,” arXiv preprint arXiv:1412.6572, 2014.
[7] J. Hayes, “On visible adversarial perturbations & digital watermarking,” in Proc. of CVPR Workshops, 2018, pp. 1597–1604.
[8] Z. Yang and et al., “Characterizing audio adversarial examples using temporal dependency,” arXiv preprint arXiv:1809.10875, 2018.
[9] Q. Zeng and et al., “A multiversion programming inspired approach to detecting audio adversarial examples,” arXiv preprint arXiv:1812.10199, 2018.
[10] K. Rajaratnam and et al., “Noise flooding for detecting audio adversarial examples against automatic speech recognition,” in Proc. of ISSPIT, 2018, pp. 197–201.
[11] T. Gu, B. Dolan-Gavitt, and S. Garg, “Badnets: Identifying vulnerabilities in the machine learning model supply chain,” CoRR, vol. abs/1708.06733, 2017. [Online]. Available: http://arxiv.org/abs/1708.06733
[12] Y. Liu, S. Ma, Y. Aafer, W.-C. Lee, J. Zhai, W. Wang, and X. Zhang, “Trojaning attack on neural networks,” in NDSS, 2018.
[13] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” CoRR, vol. abs/1409.1556, 2014. [Online]. Available: http://arxiv.org/abs/1409.1556
本文作者为仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
感兴趣加入机器之心全球分析师网络?点击阅读原文,提交申请。