机器之心 & ArXiv Weekly Radiostation
本周主要论文包括阿里达摩院获 KDD 2022 最佳论文,这是国内企业首次获奖;Meta 发布 110 亿参数模型,击败谷歌 PaLM 等研究。
目录
-
FederatedScope-GNN: Towards a Unified, Comprehensive and Efficient Package for Federated Graph Learning
-
High-Resolution Image Synthesis with Latent Diffusion Models
-
Few-shot Learning with Retrieval Augmented Language Models
-
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
-
High-Resolution Image Synthesis with Latent Diffusion Models
-
MorphMLP: An Efficient MLP-Like Backbone for Spatial-Temporal Representation Learning
-
Efficient and Scalable Neural Architectures for Visual Recognition
-
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:FederatedScope-GNN: Towards a Unified, Comprehensive and Efficient Package for Federated Graph Learning
-
-
论文地址:https://arxiv.org/pdf/2204.05562.pdf
摘要:
阿里巴巴达摩院智能计算实验室提出并基于联邦学习框架 FederatedScope 实现了针对图学习的库 FederatedScope-GNN,获 KDD 2022 最佳论文,这是国内企业首次获奖。
FederatedScope-GNN 针对图学习提供了 DataZoo 和 ModelZoo,分别为用户提供了丰富多样的联邦图数据集和相应的模型与算法。DataZoo 既包含若干新引入的数据集,也实现了大量不同类型的 splitters,用于通过单机图数据集来构造联邦图数据集。DataZoo 提供的大量数据集涵盖了不同领域、不同任务类型、不同统计异质性的联邦图数据,大大方便了使用者对所关注算法进行全面的评估。
基于事件驱动的底层框架 FederatedScope 来实现联邦图学习算法 FedSage+。
推荐:
阿里达摩院获 KDD 2022 最佳论文,国内企业首次获奖。
论文 2:High-Resolution Image Synthesis with Latent Diffusion Models
-
作者:Robin Rombach 、 Andreas Blattmann 等
-
论文地址:https://arxiv.org/pdf/2112.10752.pdf
摘要:
来自慕尼黑大学和 Runway 的研究者基于其 CVPR 2022 的论文《High-Resolution Image Synthesis with Latent Diffusion Models》,并与 Eleuther AI、LAION 等团队合作,共同开发了一种可在消费级 GPU 上运行的文本转图像模型 Stable Diffusion,目前项目代码已开源。
Stable Diffusion 可以在消费级 GPU 上的 10 GB VRAM 下运行,并在几秒钟内生成 512x512 像素的图像,无需预处理和后处理,这是速度和质量上的突破。
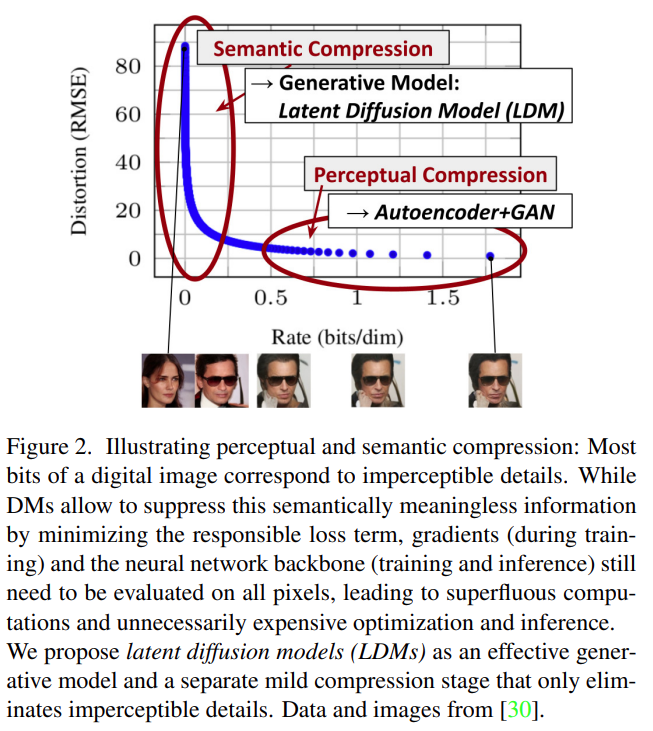
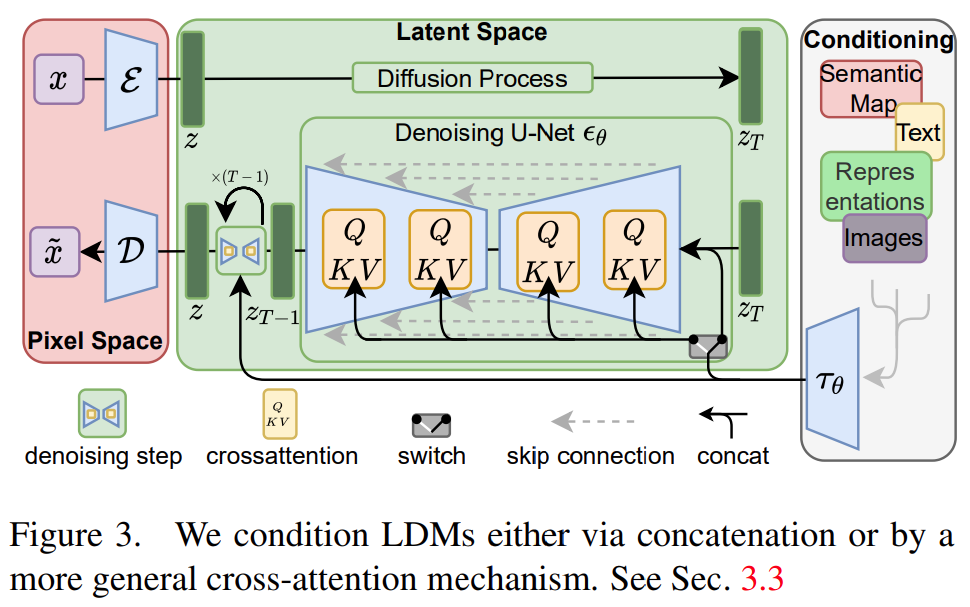
该研究试图利用扩散模型实现文字转图像。尽管扩散模型允许通过对相应的损失项进行欠采样(undersampling)来忽略感知上不相关的细节,但它们仍然需要在像素空间中进行昂贵的函数评估,这会导致对计算时间和能源资源的巨大需求。该研究通过将压缩与生成学习阶段显式分离来规避这个问题,最终降低了训练扩散模型对高分辨率图像合成的计算需求。
该研究使用一个自动编码模型学习一种空间,该空间在感知上与图像空间等效,却能显著降低计算复杂度。
推荐:消费级 GPU 可用,文本转图像开源新模型 Stable Diffusion 生成宇宙变迁大片。
论文 3:Few-shot Learning with Retrieval Augmented Language Models
-
作者:Gautier Izacard、 Patrick Lewis 等
-
论文地址:https://arxiv.org/pdf/2208.03299.pdf
摘要:
本文中,来自 Meta AI Research 等机构的研究者提出小样本学习是否需要模型在其参数中存储大量信息,以及存储是否可以与泛化解耦。他们提出 Atlas,其是检索增强语言模型的一种,拥有很强的小样本学习能力,即使参数量低于目前其它强大的小样本学习模型。模型采用非参数存储,即使用基于大型外部非静态知识源上的神经检索器去增强参数语言模型。除了存储能力,此类架构在适应性、可解释性和效率方面都存在优势,因此很有吸引力。
在只有 11B 个参数的情况下,Atlas 使用 64 个训练示例在 NaturalQuestions(NQ)上实现了 42.4% 准确率,比 540B 参数模型 PaLM( 39.6% ) 高出近 3 个百分点,在全数据集设置中(Full)达到 64.0% 准确率。
推荐:
参数量 1/50,Meta 发布 110 亿参数模型,击败谷歌 PaLM。
论文 4:LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
-
作者:Tim Dettmers 、 Mike Lewis 、
-
论文地址:https://arxiv.org/pdf/2208.07339.pdf
摘要:
语言模型的规模一直在变大,PaLM 有 540B 参数,OPT、GPT-3 和 BLOOM 有大约 176B 参数,模型还在朝着更大的方向发展。
这些模型很难在易于访问的设备上运行。例如,BLOOM-176B 需要在 8 个 80GB A100 GPU(每个约 15000 美元)上运行才能完成推理任务,而微调 BLOOM-176B 则需要 72 个这样的 GPU。PaLM 等更大的模型将需要更多的资源。
我们需要找到方法来降低这些模型的资源需求,同时保持模型的性能。领域内已经开发了各种试图缩小模型大小的技术,例如量化和蒸馏。
BLOOM 是去年由 1000 多名志愿研究人员在一个名为「BigScience」的项目中创建的,该项目由人工智能初创公司 Hugging Face 利用法国政府的资金运作,今年 7 月 12 日 BLOOM 模型正式发布。
使用 Int8 推理会大幅减少模型的内存占用,却不会降低模型的预测性能。基于此,来自华盛顿大学、Meta AI 研究院等(原 Facebook AI Research )机构的研究员联合 HuggingFace 开展了一项研究,试图让经过训练的 BLOOM-176B 在更少的 GPU 上运行,并将所提方法完全集成到 HuggingFace Transformers 中。
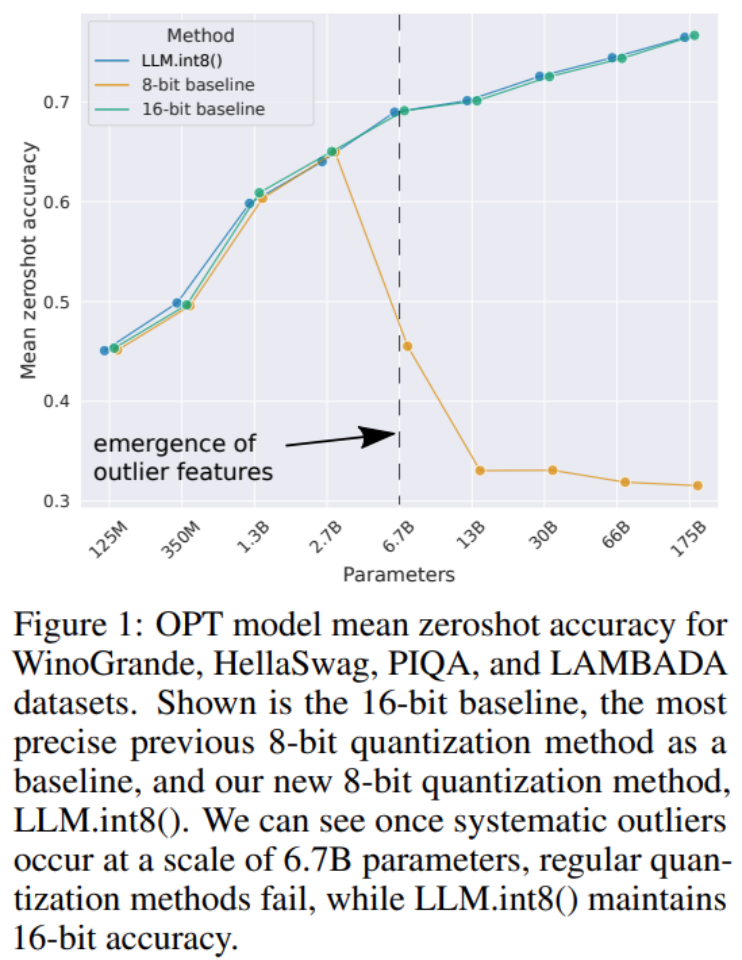
该研究为 transformer 提出了首个数十亿规模的 Int8 量化过程,该过程不会影响模型的推理性能。它可以加载一个具有 16-bit 或 32-bit 权重的 175B 参数的 transformer,并将前馈和注意力投影层转换为 8-bit。
该研究将向量量化和混合精度分解的组合命名为 LLM.int8()。实验表明,通过使用 LLM.int8(),可以在消费级 GPU 上使用多达 175B 参数的 LLM 执行推理,而不会降低性能。该方法不仅为异常值对模型性能的影响提供了新思路,还首次使在消费级 GPU 的单个服务器上使用非常大的模型成为可能,例如 OPT-175B/BLOOM。
推荐:
面向 Transformer 的 8 比特矩阵乘法,消费级 GPU 可用。
论文 5:High-Resolution Image Synthesis with Latent Diffusion Models
-
-
论文地址:https://arxiv.org/pdf/2112.10752.pdf
摘要:
根据文本生成图像是近来大火的一个研究方向。无论是英伟达的 GauGAN,还是 OpenAI 的 DALL·E,都获得了令人印象深刻的结果。但这些模型都是参数量过亿的超大模型,普通的消费级 GPU 根本无法支持。现在,来自慕尼黑大学和 Runway 的研究者基于其 CVPR 2022 的论文《High-Resolution Image Synthesis with Latent Diffusion Models》,并与 Eleuther AI、LAION 等团队合作,共同开发了一种可在消费级 GPU 上运行的文本转图像模型 Stable Diffusion,目前项目代码已开源。
推荐:
消费级 GPU 可用,文本转图像开源新模型 Stable Diffusion 生成宇宙变迁大片。
论文 6:MorphMLP: An Efficient MLP-Like Backbone for Spatial-Temporal Representation Learning
-
-
论文地址:https://arxiv.org/abs/2111.12527
摘要:
本文中,美图影像研究院(MT Lab)与新加坡国立大学提出高效的 MLP(多层感知机模型)视频主干网络,用于解决极具挑战性的视频时空建模问题。该方法仅用简单的全连接层来处理视频数据,提高效率的同时有效学习了视频中细粒度的特征,进而提升了视频主干网络框架的精度。此外,将此网络适配到图像域(图像分类分割),也取得了具有竞争力的结果。研究被 ECCV 2022 会议接收。
推荐:
仅用全连接层处理视频数据,美图 & NUS 实现高效视频时空建模。
论文 7:Efficient and Scalable Neural Architectures for Visual Recognition
-
-
论文地址:https://www2.eecs.berkeley.edu/Pubs/TechRpts/2022/EECS-2022-205.pdf
摘要:
UC 伯克利博士生刘壮(Zhuang Liu)在其博士论文《 Efficient and Scalable Neural Architectures for Visual Recognition 》中,从两个方面展开研究:(1)开发直观的算法以实现高效灵活的 ConvNet 模型推理;(2) 研究基线方法以揭示扩展方法成功的原因。具体而言,首先,本文介绍了关于密集预测的第一个随时算法研究。然后,该研究将模型剪枝算法与简单的基线方法进行比较来检查模型的有效性。最后研究者提出了这样一个问题,即通过采用 Transformer 中的设计技巧对传统的 ConvNet 进行现代化改造,来测试纯 ConvNet 所能达到的极限,并探索在视觉任务上自注意力机制在 Transformer 中的可扩展性上所起的作用。
推荐:
DenseNet 共一、CVPR 2017 最佳论文得主刘壮博士论文,从另一视角看神经网络架构。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Manual-Guided Dialogue for Flexible Conversational Agents. (from Minlie Huang)
2. Transformer Vs. MLP-Mixer Exponential Expressive Gap For NLP Problems. (from Alex M. Bronstein)
3. Exploiting Unlabeled Data for Target-Oriented Opinion Words Extraction. (from Hao Wu)
4. TexPrax: A Messaging Application for Ethical, Real-time Data Collection and Annotation. (from Iryna Gurevych)
5. Mining Legal Arguments in Court Decisions. (from Iryna Gurevych)
6. Automated Utterance Labeling of Conversations Using Natural Language Processing. (from Yan Liu)
7. SynKB: Semantic Search for Synthetic Procedures. (from Alan Ritter)
8. An Efficient Coarse-to-Fine Facet-Aware Unsupervised Summarization Framework based on Semantic Blocks. (from Zhoujun Li)
9. What Artificial Neural Networks Can Tell Us About Human Language Acquisition. (from Samuel R. Bowman)
10. SelF-Eval: Self-supervised Fine-grained Dialogue Evaluation. (from Weinan Zhang)
1. Where is VALDO? VAscular Lesions Detection and segmentatiOn challenge at MICCAI 2021. (from Frederik Barkhof, Meike W. Vernooij)
2. Differentiable Architecture Search with Random Features. (from Xiangyu Zhang, Jian Sun)
3. PDRF: Progressively Deblurring Radiance Field for Fast and Robust Scene Reconstruction from Blurry Images. (from Rama Chellappa)
4. MoCapDeform: Monocular 3D Human Motion Capture in Deformable Scenes. (from Bernt Schiele, Christian Theobalt)
5. Category-Level Pose Retrieval with Contrastive Features Learnt with Occlusion Augmentation. (from Tinne Tuytelaars)
6. Memory-Driven Text-to-Image Generation. (from Philip H. S. Torr)
7. Subtype-Aware Dynamic Unsupervised Domain Adaptation. (from C.-C. Jay Kuo)
8. Unsupervised Domain Adaptation for Segmentation with Black-box Source Model. (from C.-C. Jay Kuo)
9. Two-person Graph Convolutional Network for Skeleton-based Human Interaction Recognition. (from Tong Zhang)
10. Visual Localization via Few-Shot Scene Region Classification. (from Marc Pollefeys)
1. Position-aware Structure Learning for Graph Topology-imbalance by Relieving Under-reaching and Over-squashing. (from Philip S. Yu)
2. Knowledge-Injected Federated Learning. (from Jian Pei)
3. Teacher Guided Training: An Efficient Framework for Knowledge Transfer. (from Rob Fergus, Sanjiv Kumar)
4. Adan: Adaptive Nesterov Momentum Algorithm for Faster Optimizing Deep Models. (from Zhouchen Lin, Shuicheng Yan)
5. Riemannian Diffusion Models. (from Aaron Courville)
6. USB: A Unified Semi-supervised Learning Benchmark. (from Bhiksha Raj, Bernt Schiele)
7. Domain-Specific Risk Minimization. (from Liang Wang, Dacheng Tao)
8. Gaussian process surrogate models for neural networks. (from Thomas L. Griffiths)
9. Acceleration of Subspace Learning Machine via Particle Swarm Optimization and Parallel Processing. (from C.-C. Jay Kuo)
10. Metric Residual Networks for Sample Efficient Goal-conditioned Reinforcement Learning. (from Peter Stone)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com