机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周重要论文包括 ECCV 2022各奖项论文以及 DeepMind 的算法蒸馏新研究。
-
In-context Reinforcement Learning with Algorithm Distillation
-
Petabit-per-second data transmission using a chip-scale microcomb ring resonator source
-
DetCLIP: Dictionary-Enriched Visual-Concept Paralleled Pre-training for Open-world Detection
-
A Level Set Theory for Neural Implicit Evolution under Explicit Flows
-
Pose-NDF: Modelling Human Pose Manifolds with Neural Distance Fields
-
On the Versatile Uses of Partial Distance Correlation in Deep Learning
-
UNIF: United Neural Implicit Functions for Clothed Human Reconstruction and Animation
-
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:In-context Reinforcement Learning with Algorithm Distillation
-
-
论文地址:https://arxiv.org/pdf/2210.14215.pdf
摘要:
在近日 DeepMind 的一篇论文中,研究者假设 PD 没能通过试错得到改进的原因是它训练用的数据无法显示学习进度。当前方法要么从不含学习的数据中学习策略(例如通过蒸馏固定专家策略),要么从包含学习的数据中学习策略(例如 RL 智能体的重放缓冲区),但后者的上下文大小(太小)无法捕获策略改进。
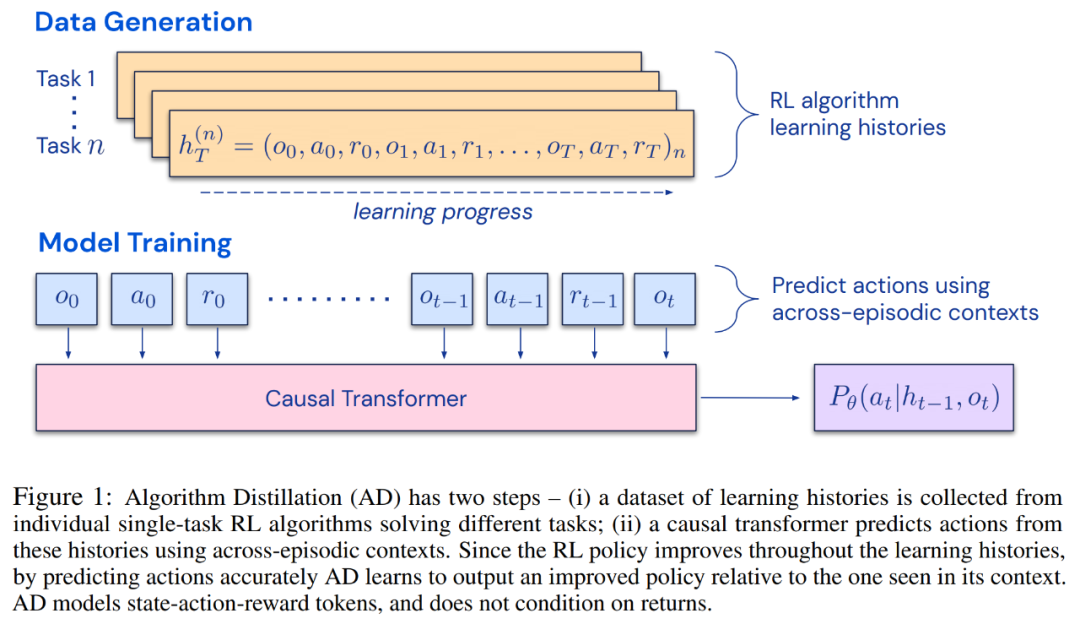
研究者提出了算法蒸馏(Algorithm Distillation, AD),这是一种通过优化 RL 算法学习历史中因果序列预测损失来学习上下文策略改进算子的方法。如下图 1 所示,AD 由两部分组成。首先通过保存 RL 算法在大量单独任务上的训练历史来生成大型多任务数据集,然后 transformer 模型通过将前面的学习历史用作其上下文来对动作进行因果建模。由于策略在源 RL 算法的训练过程中持续改进,因此 AD 不得不学习改进算子以便准确地建模训练历史中任何给定点的动作。至关重要的一点是,transformer 上下文必须足够大(即 across-episodic)才能捕获训练数据的改进。
![]()
推荐:
DeepMind 新作:无需权重更新、提示和微调,transformer 在试错中自主改进。
论文 2:Petabit-per-second data transmission using a chip-scale microcomb ring resonator source
-
-
论文地址:https://www.nature.com/articles/s41566-022-01082-z
摘要:
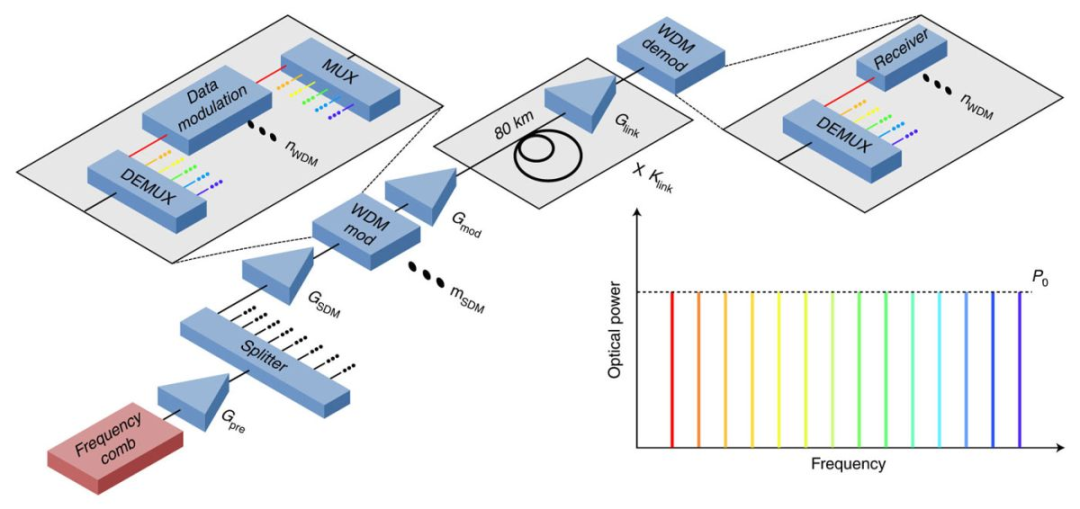
近日,来自丹麦技术大学(DTU)和瑞典哥德堡查尔姆斯理工大学的研究小组实现了迄今为止最高的数据传输效率,并且是世界上第一个仅使用单个激光器和单个光芯片实现每秒传输超过 1 拍比特 (Pbit/s) 的研究。
在实验中,研究人员仅使用一个光源在 7.9 公里的距离上实现了传输速率 1.8 Pbit/s——1 Petabit 相当于 12.5 万 Gigabyte,根据一些估算,全世界使用的平均互联网带宽约为 1 Pbit/s,因此它的速度接近全球带宽的两倍。
![]() 通信系统建模。
通信系统建模。
推荐:
1.84Pb/s,两倍于全球互联网带宽总和:单激光器实现最快数据传输纪录。
论文 3:DetCLIP: Dictionary-Enriched Visual-Concept Paralleled Pre-training for Open-world Detection
-
作者:Lewei Yao、Jianhua Han 等
-
论文地址:https://arxiv.org/abs/2209.09407
摘要:
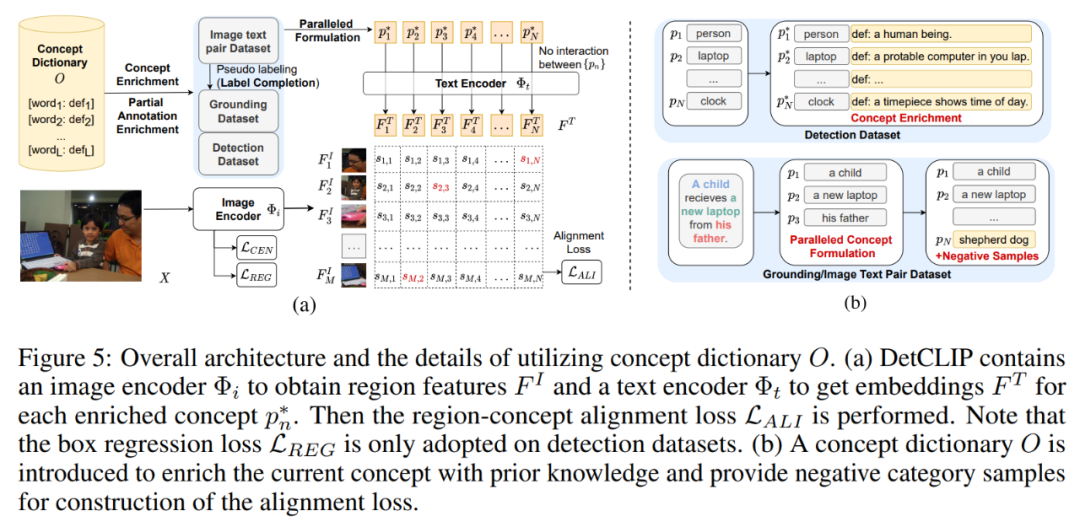
开放域检测问题是指在上游利用大量网上爬取的图文对或一定类别的人工标注数据进行训练,如何在下游场景上实现任意类别检测的问题。开放域检测方法在产业界的应用主要包括自动驾驶系统路面物体检测,云端全场景检测等。
本论文对开放域检测问题提出了一种针对多数据源联合高效的并行训练框架,同时构建了额外的知识库来提供类别间的隐式关系。同时 DetCLIP 在微软举办的 ECCV2022 OdinW (Object Detection in the Wild[1]) 比赛上以 24.9% 的平均检测指标取得了 zero-shot 检测赛道第一名。论文已被 NeurIPS 2022 接收。
![]()
推荐:
NeurIPS 2022 | 开放域检测新方法 DetCLIP,推理效率提升 20 倍。
论文 4:A Level Set Theory for Neural Implicit Evolution under Explicit Flows
-
-
论文地址:https://arxiv.org/pdf/2204.07159.pdf
摘要:
基于坐标的神经网络参数化隐式表面已经成为几何的有效表示,它们高效充当了参数水平集,其中零水平集定义了感兴趣的表面。研究者提出了一个框架,允许将为三角形网格定义的变形操作应用于这类表面。这些操作中的一些可以被视为在显式表面引起瞬时流场的能量最小化问题。他们的方法通过扩展水平集的经典理论,利用流场来实现参数化隐式表面变形。
此外,通过形式化与水平集理论的关联,研究者还为现有的可微表面提取和渲染方法得出一个统一的观点。他们认为这些方法偏离了理论,并展示了自身方法对表面平滑、平均曲率流、逆渲染和用户定义的隐式几何编辑等应用的改进。
![]()
论文 5:Pose-NDF: Modelling Human Pose Manifolds with Neural Distance Fields
-
-
论文地址:https://virtualhumans.mpi-inf.mpg.de/papers/tiwari22posendf/posendf.pdf
摘要:
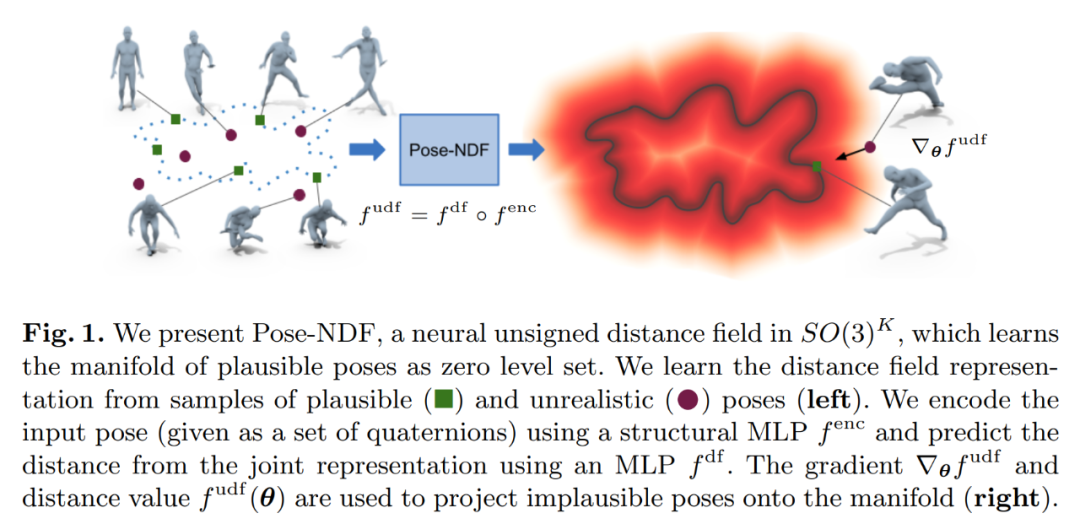
本文提出了一种基于神经距离场 (NDFs) 的人体姿态连续模型:Pose-NDF。众所周知,姿态或动作先验对于生成逼真的新姿态非常重要,对从有噪声或局部观察重建精确的姿态也非常重要。
Pose-NDF 学习一系列各种可能的姿态作为神经隐式函数的零水平集(zero level set),将 3D 建模隐式曲面的思想扩展到高维域 SO(3)^K,其中人体姿态由单个数据点定义,由 K 个四元数表示。由此得到的高维隐函数可以对输入姿态进行微分,因此可以通过在 3 维超球体集合上使用梯度下降将任意姿态投射到流形(manifold)上。
![]()
论文 6:On the Versatile Uses of Partial Distance Correlation in Deep Learning
-
作者:Xingjian Zhen 、Zihang Meng 等
-
论文地址:https://arxiv.org/pdf/2207.09684.pdf
摘要:
比较神经网络模型的功能行为,无论是在训练期间的单个网络,还是训练一段时间后的两个网络(或更多网络),这些是了解模型正在学习什么(以及它们没有学习什么)的重要步骤,同时也是确定规范化或提高效率的重要策略。最近的研究已经取得了一些进展,例如研究者将视觉 transformers 与 CNN 进行比较,但系统地比较功能,特别是在不同的网络之间,仍然存在很多困难,通常的做法是一层一层地进行比较。
CCA(canonical correlation analysis)等方法在原则上适用,但迄今为止用的人很少。本文回顾了统计学中一个鲜为人知的概念,称为距离相关(及其部分变体),它被设计用来评估不同维度特征空间之间的相关性。该研究描述了将其部署到大规模模型的必要步骤,这为一系列应用打开了大门,包括调节一个深度模型,学习解耦表示,以及优化不同的模型,这些模型在应对对抗攻击时,鲁棒性更好。
![]()
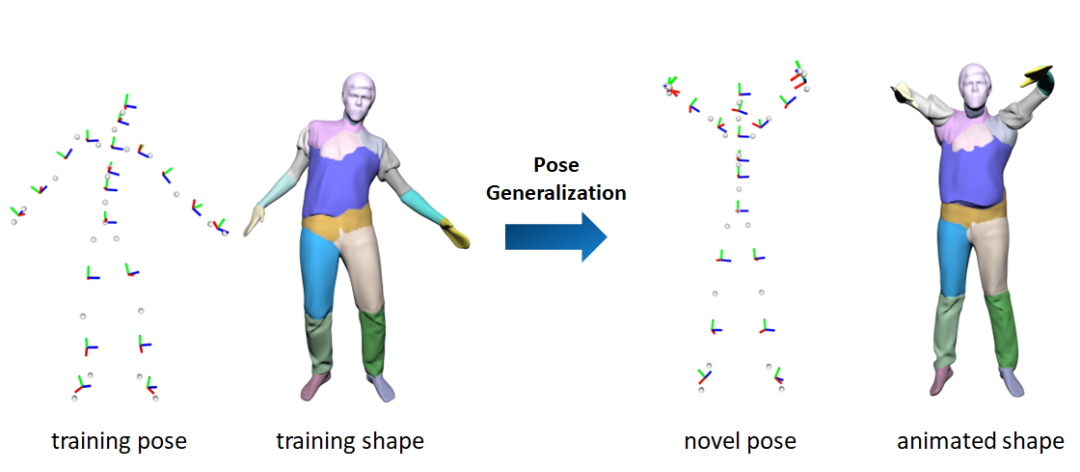
论文 7:UNIF: United Neural Implicit Functions for Clothed Human Reconstruction and Animation
-
-
论文地址:https://arxiv.org/abs/2207.09835
摘要:
上海科技大学和 ZMO.AI 的研究者提出了一套分部件人体重建和驱动的方法 UNIF,借助简洁有效的初始化和正则化手段,使分部件重建方法摆脱对部件划分标签的依赖。通过显式地建模部件之间的相互作用,显著提升了分部件重建方法对人体姿态的泛化能力。ZMO.AI 是国内头部内容生成初创公司,专注于 AI 文字生成内容 Yuan 初 创作平台的搭建。该论文已被 ECCV 2022 接收,并公开了代码。
![]()
推荐:
ECCV 2022 | 摆脱部件标签依赖,上科大 & ZMO.AI 提出分部件 3D 人体重建与驱动新方法 UNIF。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. PALT: Parameter-Lite Transfer of Language Models for Knowledge Graph Completion. (from Jiawei Han)
2. Large Language Models Can Self-Improve. (from Jiawei Han)
3. A Causal Framework to Quantify the Robustness of Mathematical Reasoning with Language Models. (from Bernhard Schölkopf)
4. Truncation Sampling as Language Model Desmoothing. (from Christopher D. Manning)
5. Is Encoder-Decoder Redundant for Neural Machine Translation?. (from Hermann Ney)
6. Revisiting Checkpoint Averaging for Neural Machine Translation. (from Hermann Ney)
7. Monotonic segmental attention for automatic speech recognition. (from Hermann Ney)
8. TASA: Deceiving Question Answering Models by Twin Answer Sentences Attack. (from Dacheng Tao)
9. Unsupervised Text Deidentification. (from Ramin Zabih)
10. Decoding a Neural Retriever's Latent Space for Query Suggestion. (from Thomas Hofmann)
1. Minutiae-Guided Fingerprint Embeddings via Vision Transformers. (from Anil K. Jain)
2. End-to-end Tracking with a Multi-query Transformer. (from Andrew Zisserman)
3. Composing Ensembles of Pre-trained Models via Iterative Consensus. (from Joshua B. Tenenbaum, Antonio Torralba)
4. The 1st-place Solution for ECCV 2022 Multiple People Tracking in Group Dance Challenge. (from Xiangyu Zhang)
5. ScoreMix: A Scalable Augmentation Strategy for Training GANs with Limited Data. (from Ming-Hsuan Yang)
6. Weakly-Supervised Temporal Article Grounding. (from Shih-Fu Chang)
7. Context-Enhanced Stereo Transformer. (from Zheng Wang, Russell H. Taylor, Alan Yuille)
8. Boosting Point Clouds Rendering via Radiance Mapping. (from Kai Chen)
9. FIND: An Unsupervised Implicit 3D Model of Articulated Human Feet. (from Roberto Cipolla)
10. Pointly-Supervised Panoptic Segmentation. (from Tieniu Tan)
1. On-Demand Sampling: Learning Optimally from Multiple Distributions. (from Michael I. Jordan)
2. Adaptive Test-Time Defense with the Manifold Hypothesis. (from Richard Hartley)
3. Efficient Automatic Machine Learning via Design Graphs. (from Jure Leskovec)
4. Adversarial Pretraining of Self-Supervised Deep Networks: Past, Present and Future. (from Mubarak Shah)
5. Learning to forecast vegetation greenness at fine resolution over Africa with ConvLSTMs. (from Markus Reichstein)
6. Efficient Dataset Distillation Using Random Feature Approximation. (from Daniela Rus)
7. Evolution of Neural Tangent Kernels under Benign and Adversarial Training. (from Daniela Rus)
8. The Curious Case of Benign Memorization. (from Thomas Hofmann)
9. PaCo: Parameter-Compositional Multi-Task Reinforcement Learning. (from Wei Xu, Masayoshi Tomizuka)
10. A Graph Is More Than Its Nodes: Towards Structured Uncertainty-Aware Learning on Graphs. (from Daniel Cremers)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com