![]()
本文约3442字,建议阅读7分钟
本文介绍了谷歌
在论文中公开的裸眼3D全息视频聊天 Project Starline 演示背后的技术。
这个神奇的「聊天室」,让你和远在天边的他们近距离碰面,互相问候、眼神交流,就像真的互相见到一样。
今年 5 月举行的谷歌 I/O 大会上,在谷歌园区户外进行的开场 Keynote 上,这家公司发布了一系列引人瞩目的全新产品。
在会上,谷歌公布了一个秘密开发多年的黑科技:全息视频聊天技术 Project Starline。Project Starline 本质上是一个 3D 视频聊天室,旨在取代一对一的 2D 视频电话会议,让用户感觉就像坐在真人面前一样。
通过 Starline,相互视频的人,不需要佩戴任何眼镜或者头盔,真实的就像坐在对面聊天一样,人物细节饱满。我们先来感受一下它的效果:
实际上,这是由高分辨率传感器、数十个景深扫描传感器以及 65 英寸「光场显示器」重新生成的实时 3D 模型。谷歌表示这一项目已开发了数年之久,其背后是大量
计算机视觉
、
机器学习
、
空间音频和数据压缩技术
。谷歌还为此开发出了一套突破性的
光场系统
,让人无需佩戴眼镜或耳机即可感受到逼真的体积和深度感。
我们可以想象实现这一技术有多难,首先你需要让大脑认为有一个真人坐在离你不远的地方;其次图像需要高分辨率并且没有伪影;此外是音频问题,因为系统需要让声音听起来是从对面人的嘴里发出来的,还有诸如眼神交流等的小问题。
这项前沿黑科技背后的技术是怎么实现的呢?想必很多人都想了解,近日,谷歌在一篇论文中公布了 Project Starline 演示背后的技术。
论文地址:https://storage.googleapis.com/pub-tools-public-publication-data/pdf/424ee26722e5863f1ce17890d9499ba9a964d84f.pdf
硬件部分,Project Starline 系统围绕一个以 60Hz 运行的大型 65 英寸 8K 面板构建。围绕它,谷歌的工程师布置了三个用于捕获彩色图像和深度数据的「捕获 pod」。该系统还包括四个额外的追踪摄像头、四个麦克风、两个扬声器和一个红外投影仪。整体来看,系统需要捕获来自四个视角的彩色图像以及三个深度图,共计七个视频流。系统还需要捕获 44.1 kHz 的音频,并以 256 Kbps 编码。
显然,所有这些硬件都会产生大量需要传输的数据,谷歌表示,传输带宽从 30Mbps 到 100Mbps 不等,具体取决于用户衣服的纹理细节和手势的大小。因此,这远远超过标准的 Zoom 通话。Project Starline 配备了四块高端 Nvidia 显卡(两块 Quadro RTX 6000 卡和两块 Titan RTX)来对所有这些数据进行编码和解码。端到端延迟平均为 105.8 毫秒。
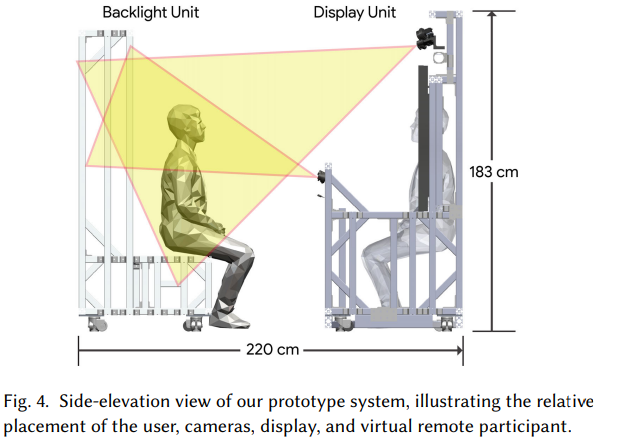
如下图 4 所示,谷歌的系统主要有两个组件:一个包含显示器、摄像头、扬声器、麦克风、照明器和计算机的
显示单元
,另一个是包含红外背光并用作 bench seat 的
背光单元
。两个单元都包含向墙壁和天花板倾斜的白色 LED 灯条,用于产生柔和的反射照明。
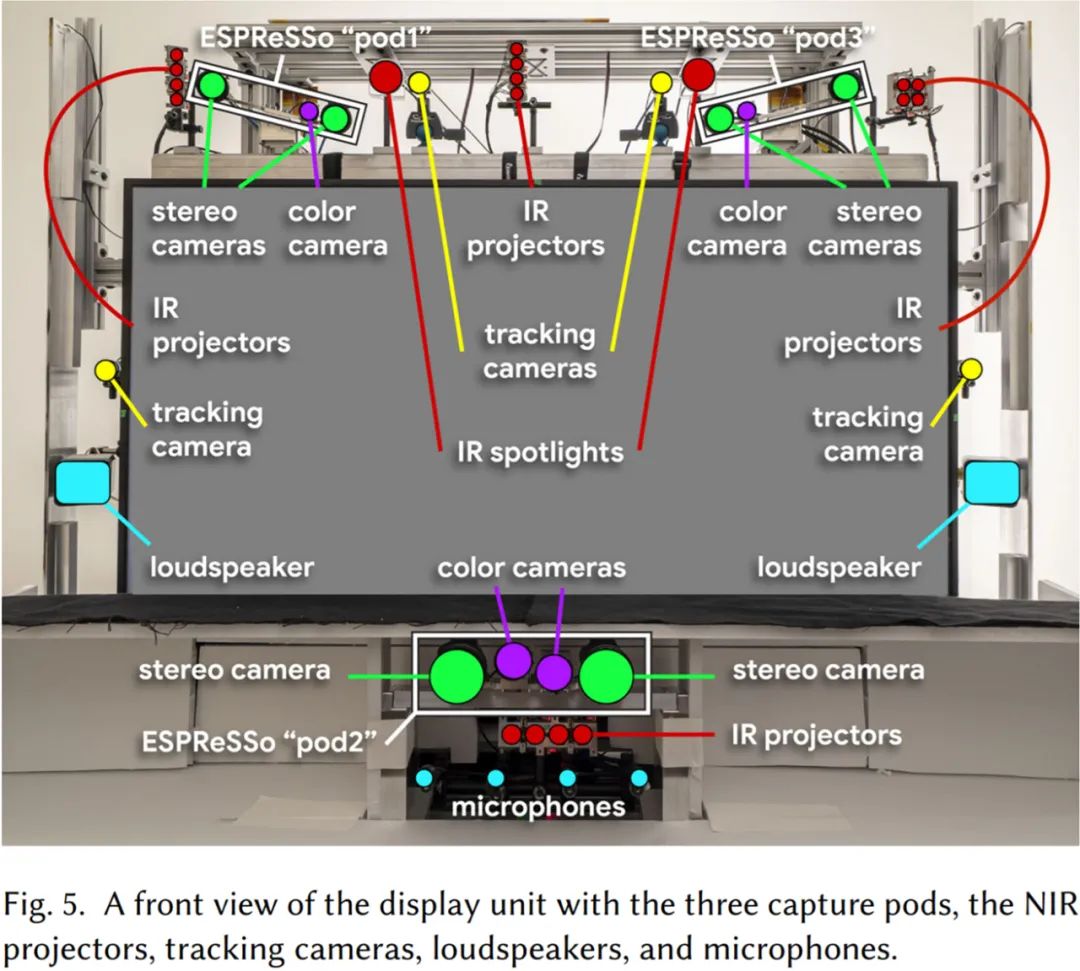
捕获子系统
由三个同步立体的 RGBD 捕获 pod 组成:两个在显示器上方,一个在显示器下方的「中墙」(middle wall)中。更下方的 pod 包括一个额外的彩色相机,用于放大拍摄对象的脸部。另外,四个单色追踪摄像头中的两个在显示器上方,其余两个一侧一个,用于捕捉眼睛、耳朵和嘴巴的高速广角图像。
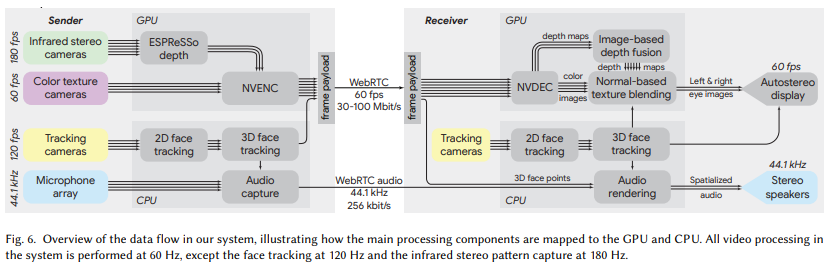
下图 6 为系统中的数据流,展示了 Starline 主要的处理组件如何映射到 GPU 和 CPU。系统中的所有视频处理都在 60 Hz 下进行,除了 120 Hz 的面部跟踪和 180 Hz 的红外立体模式捕获。
谷歌使用间接「反弹」(bounce)光源创造了一个柔和的照明环境。在显示和背光单元的侧面和背面,白色 LED 灯带照亮了周围的墙壁,产生舒适的漫射源,最大限度地减少锐利高光。与明亮的 LED 直接照明相比,这种散射的光对用户来说也更舒适。
同时,光亮保持一定的不均匀分布也很重要。谷歌发现,完全均匀的入射光使人脸和其他 3D 形状看起来扁平且不真实,阻碍了系统中其他 3D 效果的发挥。摄影师尤其是电影摄影师将拍摄对象完全照亮和阴影两侧之间的对比度称为「照明比」。为了保持对象的立体感,谷歌在邻近墙壁的显示单元一侧使用更强的强度,产生大约 2:1 的照明比。
谷歌通过调整每个相机的增益、色彩校正 (3×3) 矩阵和 gamma 对系统的 RGB 相机进行色彩校准,以使标准色彩目标 [McCamy et al. 1976] 匹配 D65 光源下的参考色彩值,抵消了室内照明的影响。经过色彩校准的显示器在 D65 光源下拍摄的图像看起来像是在当地房间的照明条件(强度和色彩)下拍摄的。这种色彩校准方案可确保系统自动校正两个用户位置之间的细微照明差异。
谷歌的目标是渲染每个用户的新图像,这是因为它们应该出现在其他用户的左眼和右眼。显然,如果可以将相机精确地放置在这些眼睛位置,那么捕捉就变得微不足道了。
遗憾的是,这是
不可行
的。一方面,这些位置位于显示器的中心附近,因而会被遮挡;另一方面,用户将会在所有 3 个维度上自由运动。新兴的透视显示技术或许能够部分解决这个问题,但透明的自动立体显示器还不存在,并且无论如何都无法解决观看者的运动问题。
因此,谷歌将捕获传感器放置在显示器的外围。由于显示器对着本地用户的角度很大,因此捕获视角与需要渲染的眼睛位置相距甚远。为了解决这种大视差,谷歌使用可见光和近红外(NIR)全局快门图像传感器的组合来重建用户的几何近似值。
如上图 5 所示,传感器分布在三个捕获 pod 中,两个在显示器上方,一个位于其下方的中墙。上方的 pod 可以很好地观察手势以及头部和躯干的侧面,同时下方的 pod 又能很好地观察颈部、面部和下巴。pod 的体积足够大,宽 1.4 m、高 1.0 m 和深 0.9 m,用于捕捉坐着自然谈话和打手势的用户的头部、躯干、手臂和手。
谷歌采用了四个同步的 1280×1024 单色相机,它们以 120Hz 运行并配有过滤器来阻挡 NIR 光。对于每个捕获的图像,谷歌检测面部并定位 34 个面部标志 [FaceDetector 2019]。此外,他们还将眼睛、嘴巴和耳朵的 2D 位置确定为邻近标志的加权组合。为了让四个追踪相机中至少有两个找出这些对象,谷歌使用三角测距法(triangulation)来获取它们的 3D 位置。
来自 RGBD 捕获 pod 的四种颜色和三种深度流在 GPU 上进行压缩,并使用 WebRTC 与追踪的 3D 面部点一起传输。
通过使用视频压缩技术,该研究能够利用现代 GPU 中高度优化的视频编码器和解码器。具体来说,他们使用四个 NVIDIA GPU 的 NVENC/NVDEC 单元。这样一来会有足够的吞吐量处理四种颜色和三种深度流在全分辨率和 60Hz 的帧率。颜色和深度流都使用带有 YUV420 chroma 子采样的 H.265 编解码器进行编码。颜色流每通道使用 8 位, 深度流每通道使用 10 位,深度数据存储在 Y 亮度(luminance)通道中,而 UV chroma 通道设置为 512(灰色)。该研究通过省略双向编码 (B) 帧来减少编码和解码延迟。
在接收客户端上解压好 3 个深度图和 4 个彩色图像后,该研究从本地用户的眼睛位置渲染虚拟远程用户左右透视图。它由三个步骤组成:
对于每个 4 色相机,通过为每条射线找到与输入深度图融合的表面的第一个交点,使用光线投射计算阴影图;
对于 2 用户视图 (左和眼) 中的每一个,使用相同的光线投射算法计算输出深度图;
对于每个输出深度映射点(output depth map point),计算由第 1 步得出的阴影映射图加权颜色混合。
对于左视图和右视图,该研究通过将彩色图像投射到融合几何体上来获得每个像素的颜色(图 10):
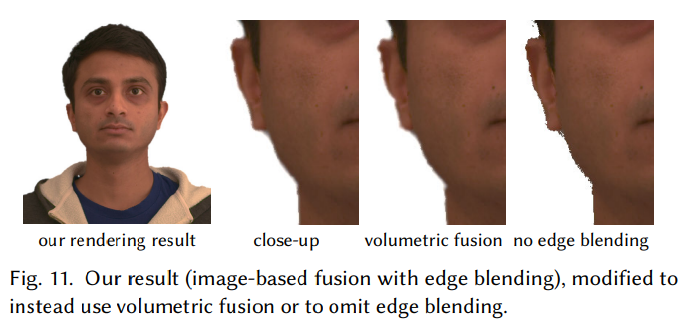
图 11 显示了没有边缘融合的不规则像素化轮廓。该图还显示,基于图像的融合提供了比轮廓附近体积融合(volumetric fusion)更完整的重建:
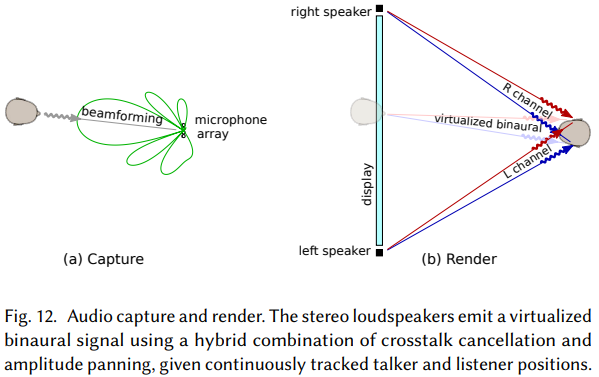
该研究使用的音频传输技术是将一系列先进技术进行组合:talker-tracked 波束成形、混响消减、WebRTC 传输、talker/listener-tracked 虚拟音频合成、双耳串扰消除分频组合以及振幅平移。与传统的视频会议系统相比,对谈话者和倾听者精确的追踪是共享空间达到真实性的关键因素(图 12)。据了解,这是首次在视频会议中无需耳机、头部追踪的音频技术。