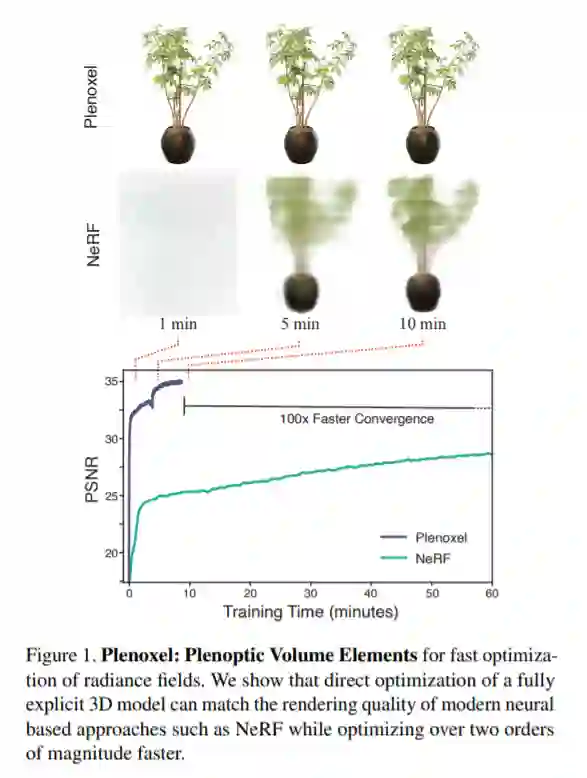
没有了神经网络,辐射场(Radiance Fields)也能达到和神经辐射场(Neural Radiance Fields,NeRFs)相同的效果,但收敛速度快了 100 多倍。
2020 年,加州大学伯克利分校、谷歌、加州大学圣地亚哥分校的研究者提出了一种名为「NeRF」的 2D 图像转 3D 模型,可以利用少数几张静态图像生成多视角的逼真 3D 图像。其改进版模型 NeRF-W (NeRF in the Wild)还可以适应充满光线变化以及遮挡的户外环境,分分钟生成 3D 旅游观光大片。
![]()
![]()
然而,这些惊艳的效果是非常消耗算力的:每帧图要渲染 30 秒,模型用单个 GPU 要训练一天。因此,后续的多篇论文都在算力成本方面进行了改进,尤其是渲染方面。但是,模型的训练成本并没有显著降低,使用单个 GPU 训练仍然需要花费数小时,这成为限制其落地的一大瓶颈。
在一篇新论文中,来自加州大学伯克利分校的研究者瞄准了这一问题,提出了一种名为 Plenoxels 的新方法。这项新研究表明,即使没有神经网络,从头训练一个辐射场(radiance field)也能达到 NeRF 的生成质量,而且优化速度提升了两个数量级。
论文链接:https://arxiv.org/pdf/2112.05131.pdf
项目主页:https://alexyu.net/plenoxels/
代码链接:https://github.com/sxyu/svox2
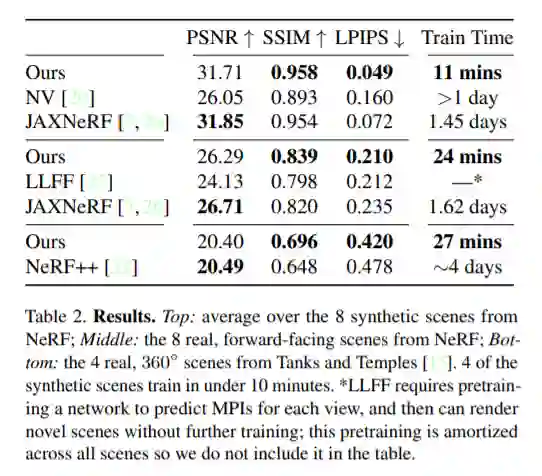
他们提供了一个定制的 CUDA 实现,利用模型的简单性来达到可观的加速。在有界场景中,Plenoxels 在单个 Titan RTX GPU 上的典型优化时间是 11 分钟,NeRF 大约是一天,前者实现了 100 多倍的加速;在无界场景中,Plenoxels 的优化时间大约为 27 分钟,NeRF++ 大约是四天,前者实现了 200 多倍的加速。虽然 Plenoxels 的实现没有针对快速渲染进行优化,但它能以 15 帧 / 秒的交互速率渲染新视点。如果想要更快的渲染速度,优化后的 Plenoxel 模型可以被转换为 PlenOctree(本文作者 Alex Yu 等在一篇 ICCV 2021 论文中提出的新方法:https://alexyu.net/plenoctrees/)。
![]()
具体来说,研究者提出了一个显式的体素表示方法,该方法基于一个不含任何神经网络的 view-dependent 稀疏体素网格。新模型可以渲染逼真的新视点,并利用训练视图上的可微渲染损失和 variation regularizer 对校准的 2D 照片进行端到端优化。
他们把该模型称为 Plenoxel(plenoptic volume elements),因为它由稀疏体素网格组成,每个体素网格存储不透明度和球谐系数信息。这些系数被 interpolated,以在空间中连续建模完整的全光函数。为了在单个 GPU 上实现高分辨率,研究者修剪了空体素,并遵循从粗到细的优化策略。虽然核心模型是一个有界体素网格,但他们可以通过两种方法来建模无界场景:1)使用标准化设备坐标(用于 forward-facing 场景);用多球体图像围绕网格来编码背景(用于 360° 场景)。
![]()
Plenoxel 在 forward-facing 场景中的效果。
![]()
该方法表明,我们可以使用标准工具从反问题中进行逼真体素重建,包括数据表示、forward 模型、正则化函数和优化器。这些组件中的每一个都可以非常简单,并且仍然可以实现 SOTA 结果。实验结果表明,神经辐射场的关键要素不是神经网络,而是可微分的体素渲染器。
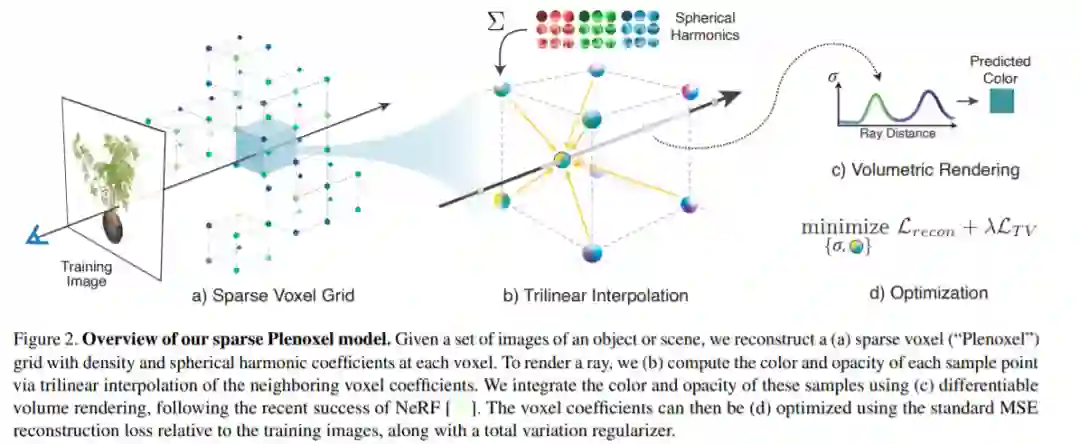
Plenoxel 是一个稀疏体素网格,其中每个被占用的体素角存储一个标量不透明度σ和每个颜色通道的球谐系数向量。作者将这种表征称为 Plenoxel。任意位置和观察方向上的不透明度和颜色是通过对存储在相邻体素上的值进行三线性插值并在适当的观察方向上评估球谐系数来确定的。给定一组校准过的图像,直接使用 training ray 上的渲染损失来优化模型。模型的架构如下图 2 所示。
![]() 上图 2 是稀疏 Plenoxel 模型框架的概念图。给定一组物体或场景的图像,研究者在每个体素处用密度和球谐系数重建一个:(a)稀疏体素(Plenoxel)网格。为了渲染光线,他们(b)通过邻近体素系数的三线性插值计算每个样本点的颜色和不透明度。他们还使用(c)可微体素渲染来整合这些样本的颜色和不透明度。然后可以(d)使用相对于训练图像的标准 MSE 重建损失以及总 variation regularizer 来优化体素系数。
研究者在合成的有界场景、真实的无界 forward-facing 场景以及真实的无界 360° 场景中展示了模型效果。他们将新模型的优化时间与之前的所有方法(包括实时渲染)进行了对比,发现新模型速度显著提升。定量比较结果见表 2,视觉比较结果如图 6、图 7、图 8 所示。
另外,新方法即使在优化的第一个 epoch 之后,也能获得高质量结果,用时不到 1.5 分钟,如图 5 所示。
上图 2 是稀疏 Plenoxel 模型框架的概念图。给定一组物体或场景的图像,研究者在每个体素处用密度和球谐系数重建一个:(a)稀疏体素(Plenoxel)网格。为了渲染光线,他们(b)通过邻近体素系数的三线性插值计算每个样本点的颜色和不透明度。他们还使用(c)可微体素渲染来整合这些样本的颜色和不透明度。然后可以(d)使用相对于训练图像的标准 MSE 重建损失以及总 variation regularizer 来优化体素系数。
研究者在合成的有界场景、真实的无界 forward-facing 场景以及真实的无界 360° 场景中展示了模型效果。他们将新模型的优化时间与之前的所有方法(包括实时渲染)进行了对比,发现新模型速度显著提升。定量比较结果见表 2,视觉比较结果如图 6、图 7、图 8 所示。
另外,新方法即使在优化的第一个 epoch 之后,也能获得高质量结果,用时不到 1.5 分钟,如图 5 所示。
使用 NVIDIA Riva 快速构建企业级 ASR 语音识别助手
NVIDIA Riva 是一个使用 GPU 加速,能用于快速部署高性能会话式 AI 服务的 SDK,可用于快速开发语音 AI 的应用程序。Riva 的设计旨在帮助开发者轻松、快速地访问会话 AI 功能,开箱即用,通过一些简单的命令和 API 操作就可以快速构建高级别的语音识别服务。该服务可以处理数百至数千音频流作为输入,并以最小延迟返回文本。
12月29日19:30-21:00,本次线上分享主要介绍:
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com