涨点神器!ELSA:增强视觉Transformer的局部自注意力
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达、
导读
当把Transformer中的LSA替换为DwConv/动态滤波器时仍可取得相近,甚至更优的性能 。但是背后的根因一直未得到探索与挖掘,到底是什么导致LSA性能平庸呢 ?本文对此进行了深入挖掘并得到了影响LSA性能的两个关键因素。

ELSA: Enhanced Local Self-Attention for Vision Transformer
论文链接:https://arxiv.org/pdf/2112.12786.pdf
代码链接:https://github.com/damo-cv/ELSA
近期多篇研究表明:当把Transformer中的LSA替换为DwConv/动态滤波器时仍可取得相近,甚至更优的性能 。但是背后的根因一直未得到探索与挖掘,到底是什么导致LSA性能平庸呢 ?本文对此进行了深入挖掘并得到了影响LSA性能的两个关键因素。基于所得发现提出了增强版ELSA,当其与SwinT、VOLO搭配时,在ImageNet分类、COCO检测以及ADE20K分割任务上均表现出了显著的性能提升。
Abstract
自注意力机制具有长距离建模能力,但局部细粒度特征学习是其弱势。局部自注意力(Local Self-Attention, LSA)的性能仅与卷积相当,弱于动态滤波器卷积。这为研究员带来了困惑:要不要使用LSA呢?哪一种更好呢?什么原因使其LSA平庸呢?
为澄清上述疑惑,我们从两个角度(channel setting与spatial processing)对LSA进行系统性挖掘。我们发现:空域注意力的生成与应用是其根因,即相对位置嵌入与近邻滤波器应用是关键因素 。基于上述发现,我们采用Hadamard注意力与Ghost头提出了增强版局部自注意力ELSA 。Hadamard注意力通过引入Hadamrd乘积以更高效的生成注意力,同时保持高阶映射关系;而Ghost头则对注意力与静态矩阵进行组合以提升通道容量。
实验结果表明:采用ELSA直接替换SwinTransformer中的LSA即可取得1.4%的性能提升。ELSA同样有助于VOLO性能提升,其中ELSA-VOLO-D5取得了87.2%的top1精度且无需额外训练数据 。此外,在下游任务方面,ELSA可以提升基线模型在COCO数据集的性能1.9boxAP/1.3maskAP,在ADE20K数据集的性能1.9mIoU。
StartPoint
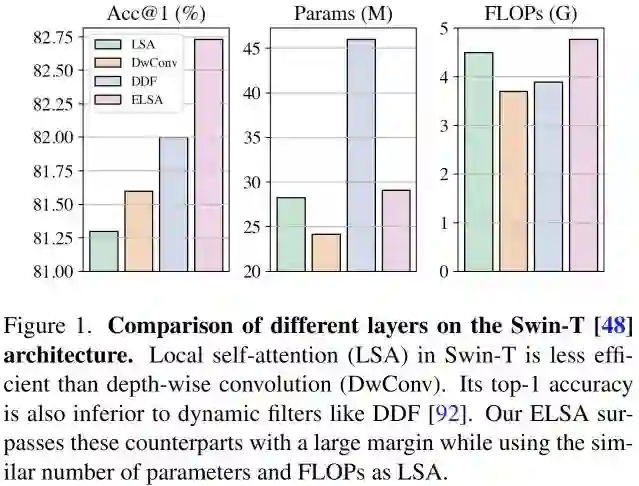
已有研究表明:当将SwinTransformer中的LSA替换为DwConv(Depth-wise Convolution)或动态卷积DDF后,LSA与DwConv的性能相当并弱于DDF (见上图)。该现在已有在近期多篇文章中得到发现,但并无关于其背后原因的深入分析。那么,是什么使得LSA变得如此平庸呢 ?
为更好的回答上述问题,我们从以下两个角度对LSA、DwConv以及动态滤波器进行了系统反思:
-
Channel Setting 。DwConv与LSA的最直接差异就在于通道配置:DwConv对不同通道采用不同的滤波器,而LSA则采用了多头策略且滤波器共享。DwConv可以视作一种特殊的多头策略,即头数等于通道数。我们猜测:DwConv的多头是其性能与LSA相当的原因所在。但实验发现:把DwConv的头数设置于LSA相当时,两者仍具有相似进度;反之亦然。也就是说: 我们需要一种新的通道策略以进一步提升LSA的性能 。 -
Spatial Processing 。如何得到滤波器并对空域信息聚合是DwConv、LSA以及动态滤波器的另一个差异。DwConv采用静态滤波器,而其他两者则采用动态滤波器。我们将上述三种方式进行统一并从参数量、规范化以及滤波器应用方面进行公平比对。我们发现: 相对位置嵌入与近邻滤波器应用是影响性能的关键因素 。此外,query与key的点乘是一种计算不友好操作。因此, 我们需要一种更高效的滤波器生成机制以替代点乘,同时保持性能 。
Channel Setting
为更好刻画让LSA平庸的原因,我们首先聚焦于DwConv与LSA的第一个差异:通道配置。DwConv对不同通道采用不同的滤波器,而LSA通过多头策略将通道拆分为多组并在组内共享滤波器。我们认为DwConv是多头策略的一种特例,即头数等于通道数。
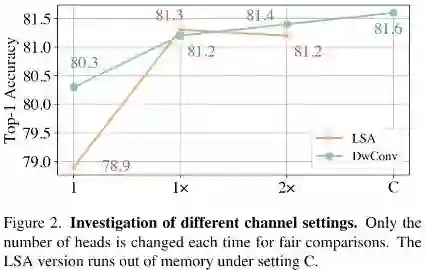
上图给出了以SwinT为基线,采用不同的头数时的性能。可以看到:
-
在相同通道配置下(如1x、2x),DwConv版本仍与LSA版本具有相似性能; -
在1x配置下,DwConv甚至具有比LSA版本更优的性能。这就说明: 通道配置并非导致前述奇异现象的主要原因 。 -
当头数配置大于1x时,LSA性能反而下降。这意味着: 直接提升头数并不能改善通道容量与性能 。 -
上述结果表明: 我们需要一种新的策略以进一步提升通道容量和性能 。
Spatial Processing
既然通道配置并非关键原因,那么我们将从空域处理角度寻求答案。DwConv、动态滤波器以及LSA采用不同的策略聚合空域信息,我们将其进行统一并从三个角度进行公平比对。
DwConv采用的是静态滤波器,其计算过程如下:
动态滤波器通过一个单独的分支网络生成空域相关滤波器,可描述如下(注:w表示滤波器生成分支网络参数):
LSA采用局部窗口的注意力图,计算过程可描述如下:
我们将上述三种策略统一成如下统一架构:
DwConv、动态滤波器以及LSA均为上式的特例。比如,当仅使用 参数时,上式退化为DwConv;当仅使用 时,上式退化为动态滤波器;类似的,我们可以将其退化为LSA。因此,影响LSA的因素主要包含:参数形式、规范化以及滤波器应用方式 。接下来,我们将对各个因素进行对比分析。

上表比较了不同参数形式的性能对比,从中可以看到:
-
动态滤波器的参数策略要比标准LSA策略具有更优的性能(Net2 vs Net1); -
动态滤波器变种策略(Net6)具有与SwinT相当的性能; -
LSA参数策略与动态滤波器参数策略的组合(Net7)可以进一步提升模型性能。

上表比较了不同规范化方式对于性能的影响,从中可以看到:
-
当采用Net7的参数形式组合Identity时,模型训练崩溃; -
相比FilterNorm,Softmax规范化具有更优的性能; -
这里结果表明: 规范化方式并非LSA并平庸的原因 。
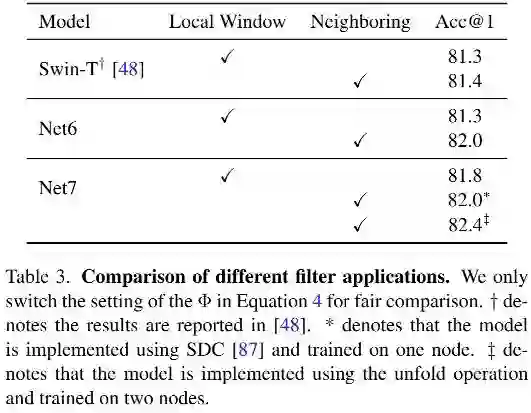
上表对比了不同滤波器使用方式(非重叠窗口 vs 滑动窗口)的性能影响,从中可以看到:当将滤波器用于近邻区域(即滑动窗口形式)时,Net6与Net7均得到了显著性能提升 。这意味着:近邻处理方式是空域处理的关键 。
Discussion
基于上述实验,使LSA变平庸的因素可以分为两个因素:
-
相对位置嵌入是影响性能的一个关键因素; -
另外一个关键因素是滤波器使用方式,即滑动窗口 vs 非重叠窗口。
DwConv能够与LSA性能相媲美的原因在于:它采用了滑动窗口处理机制。当其采用非重叠窗口机制时,性能明显弱于LSA(见Table1中的Net4)。
动态滤波器性能优于LSA的原因在于相对位置嵌入与近邻滤波器使用方式。两者的集成(Net7)取得了最佳的性能。
对比非重叠局部窗口与滑动窗口,局部重叠的峰值性能要弱于滑动窗口。局部窗口的一个缺点在于:窗口间缺乏信息交互,限制了其性能;而滑动窗口的缺陷在于低吞吐量。那么,如何避免点乘同时保持高性能就成了新的挑战 。
Enhanced Local Self-attention
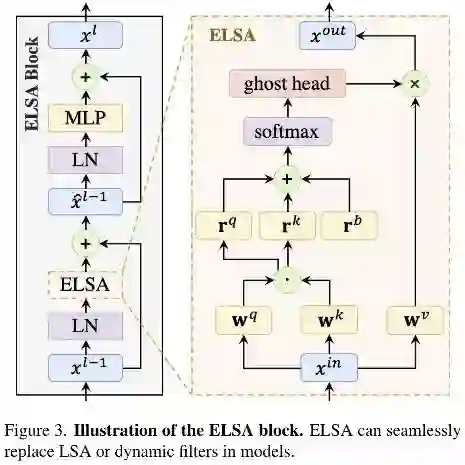
我们提出了一种的新的局部自注意力模块ELSA(见上图),超越了SwinT中的LSA与动态滤波器。ELSA的关键技术为Hadamard注意力与Ghost头模块。ELSA的处理过程可描述如下:
其中, 分别表示Hadamard注意力与Ghost头映射模块。
Hadamard注意力可以描述如下:
该公式的实现极为高效,伪代码如下:

Ghost头则受启发于GhostNet得到,可以描述如下:
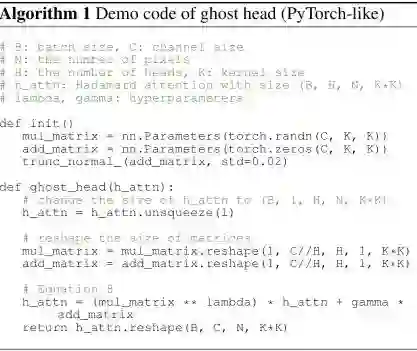
上图为Ghost头的实现参考code,为避免过大的GPU显存占用,作者进行了CUDA实现。
Experiments
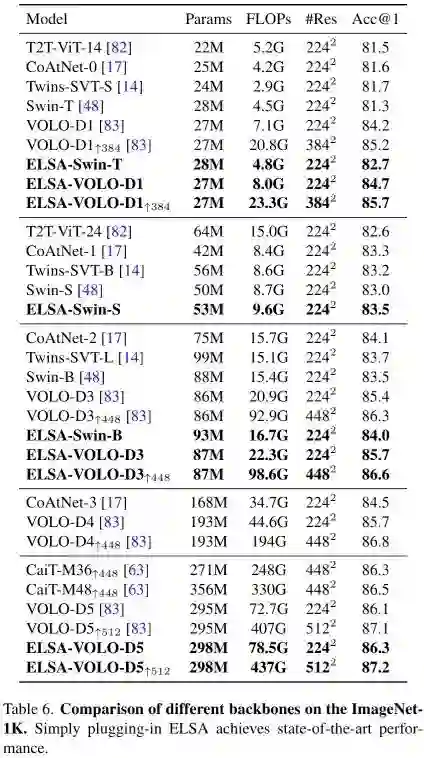
上表给出了所提方案与其他SOTA方案的性能对比,从中可以看到:
-
在不同模型大小下,所提ELSA均优于SwinT与VOLO; -
ELSA分别优于Swin-T、Swin-S、Swin-B达1.4%、0.5%、0.5%;其中ELSA-Swin-S与原始Swin-B相当,且参数量与FLOPs更少。 -
ELSA-VOLO-D1与ELSA-VOLO-D3分别去了84.7%与85.7%的top1精度,ELSA-VOLO-D3甚至取得了媲美VOLO-D4的性能且参数量减半。 -
ELSA-VOLO-D5甚至取得了87.2%的top1精度,超过了此前最佳87.1%。
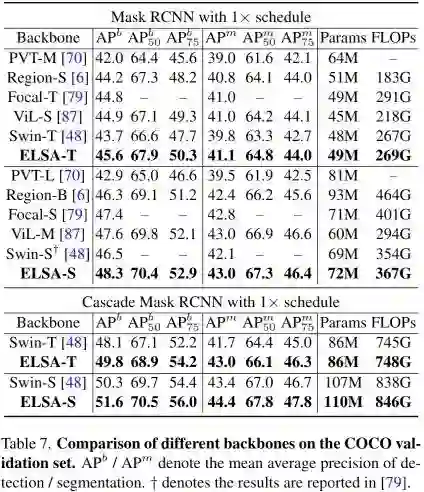
上图给出了COCO数据上不同方案性能对比,从中可以看到:
-
ELSA-Swin-T 与ELSA-Swin-S分别超出基线模型1.9AP与1.8AP; -
采用Cascade Mask RCNN时,ELSA-Swin-T与ELSA-Swin-S分别取得了49.8与51.6的AP指标,以1.7和1.3AP指标优于基线模型。
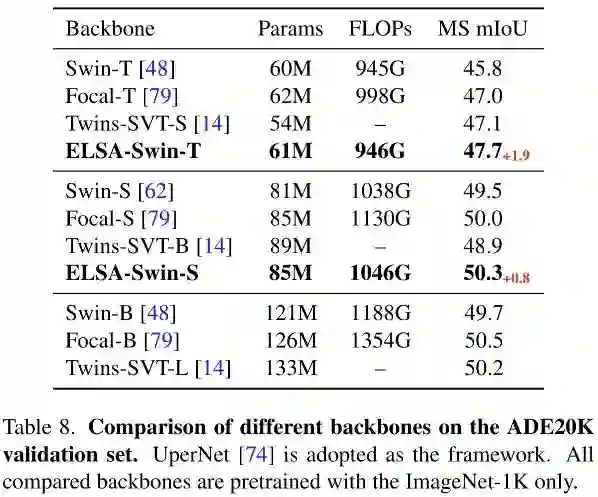
上表给出了ADE20K数据及上的性能对比,从中可以看到:
-
ELSA-Swin-T以1.9mIoU指标优于基线Swin-T; -
ELSA-Swin-S作为骨干时取得了50.3mIoU指标,以0.8优于Swin-S,甚至优于Swin-B。
上面论文代码下载
后台回复:ELSA,即可下载上述论文
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
重磅!目标检测交流群成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看


