ECCV 2018 | ALFNet:向高效行人检测迈进(附代码)
极市平台是专业的视觉算法开发和分发平台,加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~

论文地址:
http://openaccess.thecvf.com/content_ECCV_2018/html/Wei_Liu_Learning_Efficient_Single-stage_ECCV_2018_paper.html
代码地址:
https://github.com/VideoObjectSearch/ALFNet
背景介绍
相比于通用物体检测,行人检测重点面向实时应用(诸如自动驾驶和视频监控场景),因此对速度和准确率较通用物体检测都具有更高的要求。当前基于CNN的通用物体检测算法主要分为两类:以Faster R-CNN为代表的两阶段方法和SSD为代表的单阶段方法,其中Faster R-CNN准确率更高,而SSD则速度占优。为了获取更高的准确率,目前主流的行人检测算法多基于Faster R-CNN的检测框架,尽管在准确率上取得了长足进步,但对速度需求的关注却略显不足,一种直接的方式是采用单阶段方法的检测框架,然而当前单阶段方法在主流行人检测库上还没有表现出准确率的优势。进一步作者思考,Faster R-CNN高精度的核心是什么?作者认为Faster R-CNN高精度的关键在于其完成了对目标候选框的两次预测,而非耗时的ROIpooling操作,如果能将这一核心迁移到SSD中,就可以保证在获得速度优势的同时保证高准确率。
从这一角度出发,作者提出了渐近定位拟合模块,极大提升了单阶段行人检测器的准确率,在面向现实场景的高效行人检测上迈出了重要一步。
主要内容
动机
面向行人检测的实时应用,以SSD为代表的单阶段检测器是一个不错的选择,但是准确率却远不如两阶段的Faster R-CNN,那么Faster R-CNN准确率高的原因是什么?作者认为:因为SSD和Faster R-CNN均为anchor-based方法,但Faster R-CNN对anchors完成了两次预测,第一阶段的RPN一次加上第二阶段的分类器一次,而SSD只对anchors完成一次预测。最新发表于CVPR2018的Cascade R-CNN[1]也已经证明:通过在Faster R-CNN的第二阶段级联多步预测会进一步提升Faster R-CNN的准确率,为此能否也在SSD框架下完成多步预测?这样就可以在获得速度优势的同时也提升准确率了。
此外作者认为:基于SSD的单阶段检测器在行人检测上表现不佳的另外一个原因是训练时只能选取单一的IoU阈值定义正负样本。一个较低的IoU阈值(比如0.5)有利于获得足够的正样本,特别是在当前行人检测数据集中行人样本本身就很有限的情况下,如下图1(a)所示,在Caltech训练集中没有行人样本的图片占了78.7%,只有一个行人样本的图片占了11.7%,可是训练时采用较低的IoU阈值会导致测试时产生大量”close but not correct”虚检,这一点在Cascade R-CNN[1]中也有提到,但如果训练时采用一个较高的IoU阈值(比如0.7)则会导致匹配上的正样本会非常少,如下图1(b)所示,随着IoU阈值的提高,匹配上的正样本数据急剧下降,这种定义正负样本的两难问题使得训练一个高精度的SSD非常困难。
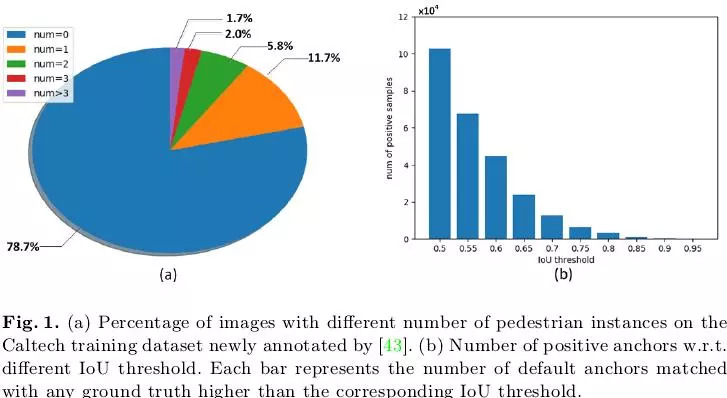
从以上分析出发,作者提出渐近定位模块(Asymptotic Localization Fitting, ALF),基于SSD的检测框架,利用不断提升的IoU阈值训练多个定位模块,来达到提升定位精度的目的。
方法
首先简单论述下SSD单阶段检测器的理论框架,在基准网络如ResNet-50上提取多尺度特征图:
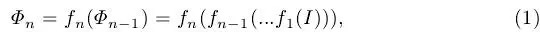
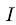
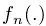
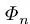
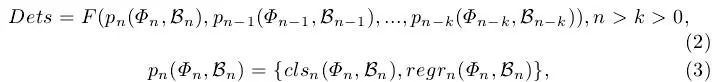
其中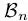
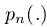
本文算法的核心--渐近定位模块,本质就是堆叠多步
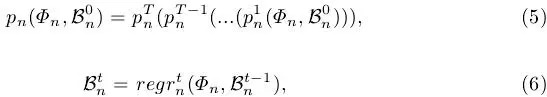
式(6)完成了对前面输出的anchors进行进一步回归,这样在训练时后面的预测器就可以得到更多质量更高的正样本,如下图2所示:两个例子中,第一步时初始目标候选框只有7和16个被匹配为正样本,到第二步时正样本数量提升到23和67,同时平均IoU也得到了一定提升,以此类推第三步时就拥有了更多的正样本。

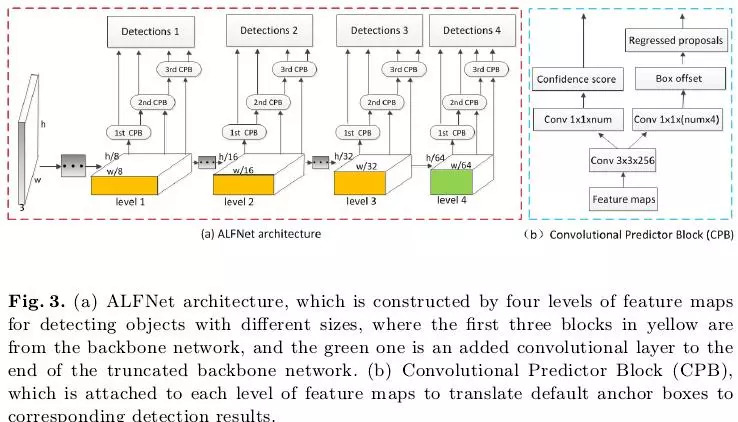
基于以上渐近定位模块(ALF),作者以ResNet-50为基础网络为例,给出了ALFNet检测器的网络架构,如下图3所示,选用ResNet-50的第3、4、5个stage的最后一层(黄色部分)以及新接的一层(绿色部分)作为多尺度特征图(分别较原始图像降采样了8、16、32和64倍),在这些特征图上添加ALF模块,也即堆叠多个CPB(图3(b))。训练和测试和通用目标检测器类似,详情可见论文。
实验分析
实验细节:
验证实验在CityPersons验证集上做的。对比实验分别在CityPersons验证集和Caltech测试集上和最新方法进行了全方位对比,Caltech训练和测试采用的是新标注[2],重点验证本文算法在对定位精度要求更高情况下的优越性(在测试时选用更高的IoU阈值进行评估,如Caltech官方评估设定中的IoU=0.75)。评估指标采用行人检测通用的Miss rate(越低越好)。
实验结果:
首先我们看下本文的核心模块ALF对检测性能带来的提升,如下表1所示,在IoU=0.5评估设定下ALF使得miss rate下降了1.45提升为10.8%,而在IoU=0.75评估设定下miss rate则下降了11.93,充分验证了ALF可以带来更高的定位精度。

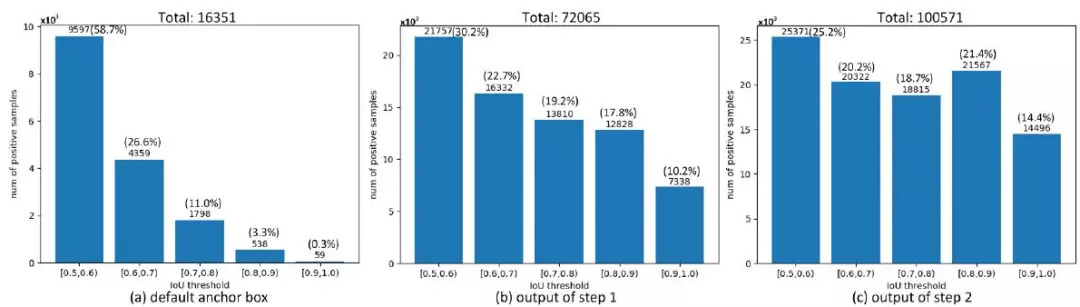
对于训练而言,ALF的优势体现在能够使得后面的预测器获得更多质量更高的正样本,文中通过下图进行了展示,可以发现对于初始目标候选框(a)而言,随着IoU阈值的提升,能够匹配上的正样本数量逐渐减少,经过ALF第一步后,不同阈值下的正样本数量均显著上升,经过ALF第二步后,这一趋势更为明显,而且在不同阈值下的正样本数量更为均衡,这就增加了训练时正样本的多样性,另外,正样本总数量也从原始的16351上升到了100571,约增加了5倍。
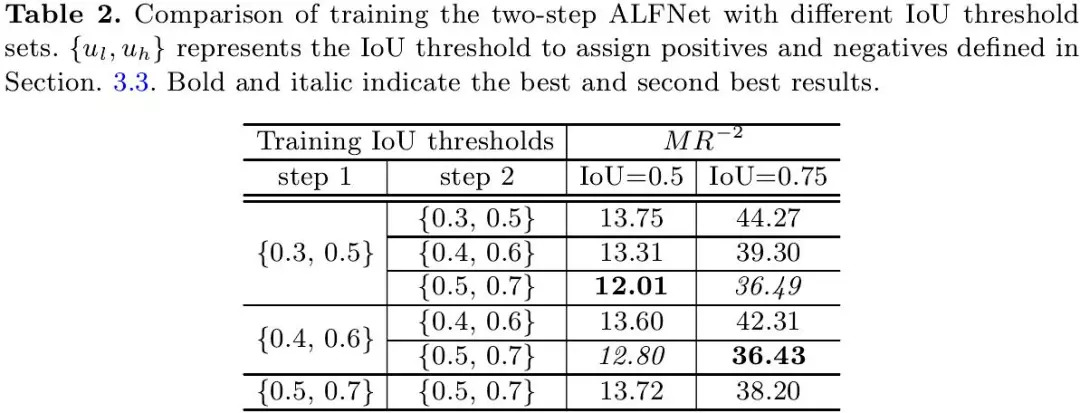
拥有数量急剧上升的正样本,使得利用更高IoU阈值训练检测器成为可能,为此作者做了不同IoU阈值训练的验证实验,如表2所示,以两步的ALFNet为例,实验表明利用提升的IoU阈值训练(从{0.3, 0.5}到{0.5, 0.7})得到了最佳检测性能,这一点和Cascade R-CNN[1]中得到的结论是一致的。
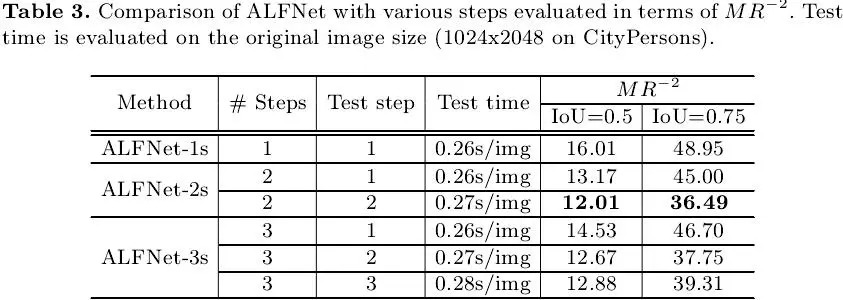
既然ALF能够提升检测性能,是不是意味着堆叠越多的步数就会得到更好的结果?作者对此做了验证实验,如下表3所示,从miss rate的评估结果来看,堆叠3步时性能就达到饱和了,2步的ALFNet取得了最佳性能,这一点和Cascade R-CNN[1]中的结论也是类似的。然而通过对TP和FP做进一步分析时作者发现3步的ALFNet获得了比2步的ALFNet更好的性能(详见论文表4)。另外值得注意的是,每增加一步,ALFNet在1024x2048的图像上的算法耗时仅增加0.01s,相对而言是一种比较经济的解决方案。
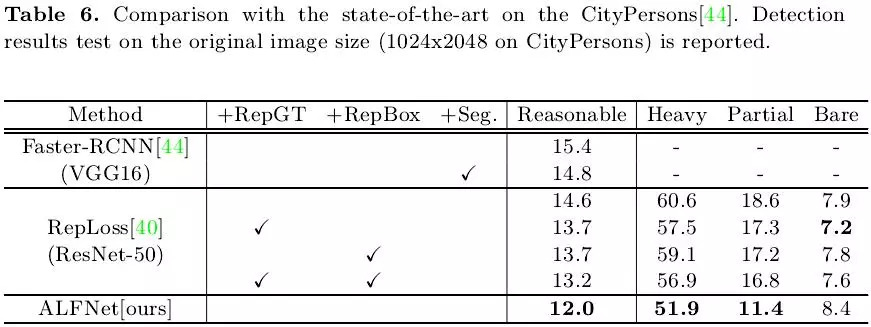
下表6展示了在CityPersons上的性能对比,其中heavy partial bare代表不同的遮挡程度,可以发现ALFNet在Reasonable设定下获得了较其他两种方法更优的性能。值得注意的时,在严重遮挡情况下的miss rate也远优于专注于遮挡问题的RepLoss,充分说明ALFNet具备更高的定位精度,因而能够更好地完成自遮挡严重情况下的行人检测。
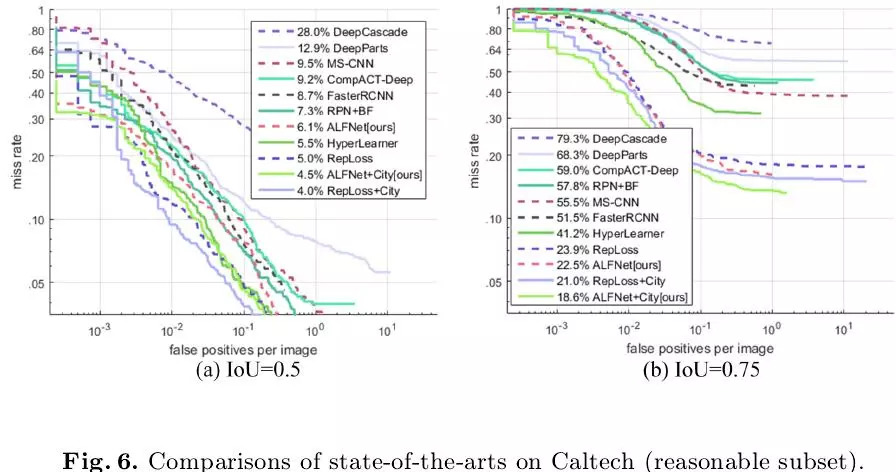
下图6展示了在Caltech上的性能对比,可以发现在IoU=0.5评估设定下ALFNet的表现劣于RepLoss,但在IoU=0.75评估设定下ALFNet取得了最佳性能,miss rate比之前最好结果低了2.4个百分点,再次证明ALFNet在定位精度方面的优势。
总结展望
本文贡献:
(1)面向行人检测实时应用,提出了一种快且准的行人检测器。
(3)实验分析并验证了:多步预测是提升检测器定位精度的关键所在;选择合适的正负样本在检测器训练中发挥着至关重要的作用。
个人见解:
(1)本文重点关注行人检测的速度和定位精度问题,为行人检测领域贡献了一套新的解决方案。
(2)本文所获得的两个结论和发表于CVPR2018的Cascade R-CNN[1]有共通之处,一是训练采用提升的IoU阈值能够或者更好的检测性能,二是并非堆叠越多步数检测器性能越好,级联一定步数时检测器性能会趋向饱和。区别在于:前者基于SSD单阶段的检测框架,目的在于提升定位精度的同时保证算法的速度优势,后者基于Faster R-CNN两阶段的检测框架,目的在于提升检测器的accuracy。尽管采用的检测框架不同,但均证明了多步预测是提升检测器性能的一个非常行之有效的方式。有关Cascade R-CNN[1]的技术解读已发表于极市平台,详情可见[3]。
参考文献
[1] Cascade R-CNN: Delving into High Quality Object Detection CVPR (2018)
[2] How Far are We from Solving Pedestrian Detection? CVPR (2016)
[3] CVPR 2018|Cascade R-CNN:向高精度目标检测器迈进
*推荐文章*
ECCV 2018 | 行人检测全新视角:从人体中轴线标注出发
CVPR 2018 | Repulsion loss:专注于遮挡情况下的行人检测
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~



