本文提出了一种高分辨率Transformer(HRT),它可以通过学习高分辨率表征来完成密集的预测任务,而原来的Vision Transformer学习的则是低分辨率表征,同时具有很高的内存和计算成本。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
![]()
原文链接:https://arxiv.org/abs/2110.09408
代码链接:https://github.com/HRNet/HRFormer
本文提出了一种高分辨率Transformer(HRT),它可以通过学习高分辨率表征来完成密集的预测任务,而原来的Vision Transformer学习的则是低分辨率表征,同时具有很高的内存和计算成本。
作者在高分辨率卷积网络(HRNet)中分别引入的多分辨率并行设计,以及local-window self-attention,在小的非重叠图像窗口上执行self-attention,以提高内存和计算效率。此外,在FFN中引入了卷积操作,以在断开的图像窗口之间交换信息。
作者实验证明了HRT在人体姿态估计和语义分割任务中的有效性,HRT在COCO姿态估计上比Swin Transformer少了50%的参数和30%的FLOPs,精度比Swin Transformer高出1.3%AP。
1 简介
Vision Transformer (ViT)在ImageNet分类任务中显示了良好的性能。后续的许多工作通过知识蒸馏、采用更深层次的体系结构、直接引入卷积运算、重新设计输入图像Tokens等来提高分类精度。此外,一些研究试图将该Transformer扩展到更广泛的视觉任务,如目标检测、语义分割、姿态估计、视频理解等。本文主要研究密集预测任务的Transformer,包括姿态估计和语义分割。
Vision Transformer将图像分割为大小为16×16的图像patches序列,然后提取每个图像patch的特征表示。因此,Vision Transformer的输出表示失去了精确密集预测所必需的细粒度空间细节。Vision Transformer仅输出单尺度特征表示,因此缺乏处理多尺度变化的能力。为了减少特征粒度的损失并对多尺度变化进行建模,作者提出了高分辨率Transformer (HRT),它包含更丰富的空间信息,并为密集预测构建多分辨率表示。
高分辨率 Transformer 采用了HRNet中的多分辨率并行设计。
-
首先,HRT在stem和第一阶段都采用了卷积(多个研究表明卷积在早期表现较好);
-
其次,HRT在整个过程中使用并行的中分辨率和低分辨率流维护高分辨率流,以帮助提高高分辨率表示(利用不同分辨率的特征图,HRT能够模拟多尺度变化);
-
最后,HRT通过多尺度融合模块交换多分辨率特征信息,实现短距离和长距离注意力的混合。
在每个分辨率下,采用局部窗口自注意力机制来降低内存和计算复杂度。作者将表示映射划分为一组不重叠的小图像窗口,并在每个图像窗口中分别执行自注意力。这就降低了内存和计算复杂度,从二次到线性的空间大小。
作者进一步在局部窗口自注意力后的前馈网络(FFN)中引入3×3深度卷积,以在局部窗口自注意力过程中断开的图像窗口之间交换信息。这有助于扩大感受野,并对密集的预测任务至关重要。
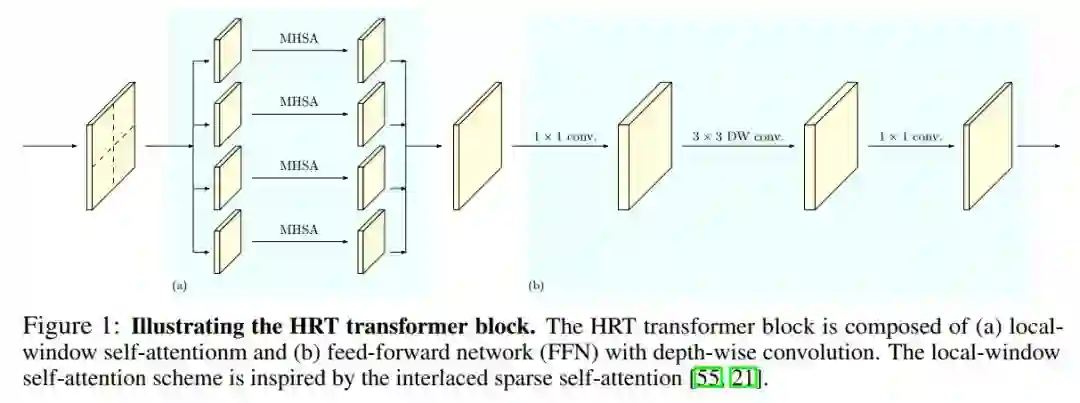
图1显示了HRT Transformer Block的详细信息。
作者进行了图像分类、姿态估计和语义分割任务的实验,并在各种 Baseline 上取得了竞争性的性能。例如,与DeiT-B相比,HRT-B在ImageNet分类上获得了+1.0%的Top-1精度,参数减少了40%,FLOPs减少了20%。在COCO val上,HRT-B比HRNet-W48增加0.9% AP,参数减少32%,FLOPs减少19%。在PASCAL-Context test和COCO-Stuff test中,HRT-B+OCR分别比HRNet-W48+OCR增加了+1.2%和+2.0% mIoU,参数减少了25%,FLOPs略多。
2 相关工作
2.1 Vision Transformer
随着Vision Transformer 和 Data-efficient image Transformer (DeiT)的成功,人们提出了各种技术来提高Vision Transformer的精度。在最近的改进中,如多尺度特性层次结构和合并卷积的有效性已经得到验证。
例如,MViT、PVT和Swin按照典型卷积架构(如ResNet-50)的空间配置将多尺度特征层次引入Transformer。与之不同的是HRT利用HRNet启发的多分辨率并行设计,融合了多尺度特征层次。
CvT、CeiT 和 LocalViT 通过在自注意力或FFN中插入深度卷积来增强 Transformer 的局部特征的鲁棒性。在HRT中插入卷积的目的是不同的,除了增强局部特征的鲁棒性,它还确保了跨非重叠窗口的信息交换。
先前也有一些研究提出了类似的局部自注意力方案用于图像分类。它们在卷积后构造重叠的局部窗口,计算量大。本文提出应用局部窗口自注意力方案将输入特征映射划分为非重叠窗口。然后在每个窗口内独立应用自注意力,从而显著提高效率。
有研究表明,提高Vision Transformer 输出的表示的空间分辨率对语义分割很重要。而HRT通过利用多分辨率并行Transformer 方案,为解决Vision Transformer的低分辨率问题提供了方法。
2.2 高分辨率CNN的密集预测
高分辨率卷积算法在姿态估计和语义分割方面都取得了很大的成功。在高分辨率卷积神经网络的开发中,开发了 3 种主要方法,包括:
-
应用 dilated convolutions 去除一些 down-sample layers ;
-
-
本文的HRT属于第3中方法,同时保留了vision transformer和HRNet的优点。
3 High-Resolution Transformer
3.1 多分辨率并联Transformer
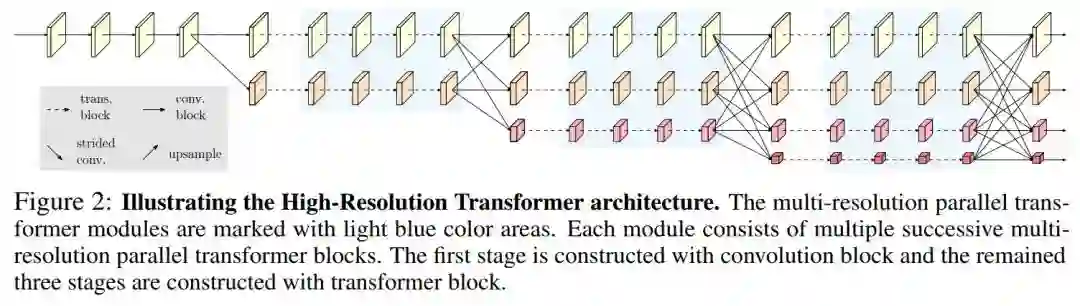
遵循HRNet的设计,从高分辨率卷积作为第一阶段,逐步添加高分辨率到低分辨率的流作为新的阶段。多分辨率流是并行连接的。主体由一系列的阶段组成。在每个阶段,每个分辨率流的特征表示分别用多个Transformer Block 进行更新,并通过卷积多尺度融合模块进行跨分辨率信息的重复交换。
图2说明了整个HRT体系结构。卷积多尺度融合模块的设计完全遵循HRNet。
3.2 Local-window Self-Attention
将Feature map
划分为一组不重叠的小窗口:
,其中每个窗口的大小为
然后在每个窗口内独立执行多头自注意力(MHSA)。第p个窗口的多头自注意力公式为:
H表示 Head数,D表示通道数,
表示输入分辨率,
表示MHSA的输出表示。作者还在模型中引入的相对位置嵌入方案,将相对位置信息融合到局部窗口的自注意力中。MHSA在每个窗口中聚合信息,将它们合并以计算输出
:
图1的左边部分说明了局部窗口自注意力如何更新2D输入表示,其中多头自注意在每个窗口中独立操作。
3.3 FFN with depth-wise convolution
局部窗口自注意力对非重叠窗口分别执行自注意力。窗户之间没有信息交换。为了解决这个问题,作者在Vision Transformer 中形成FFN的2个点MLP之间添加了一个3×3深度卷积:
。图1的右半部分展示了具有3×3深度卷积的FFN如何更新2D输入表示的示例。
3.4 Representation head 设计
如图2所示,HRT的输出由4个不同分辨率的Feature map组成。
-
ImageNet分类:将4倍下采样的特征图送到bottleneck 中,输出通道分别更改为128、256、512和1024。然后,应用 strided convolutions 来融合它们,输出具有2048通道的最低分辨率的特征图。最后,应用一个全局平均池化操作,然后是最终分类器;
-
姿态估计:只在最高分辨率的特征图上应用回归Head;
-
语义分割:将语义分割头应用于级联表示上,首先将所有低分辨率表示上采样到最高分辨率,然后将它们级联在一起。
3.5 Instantiation
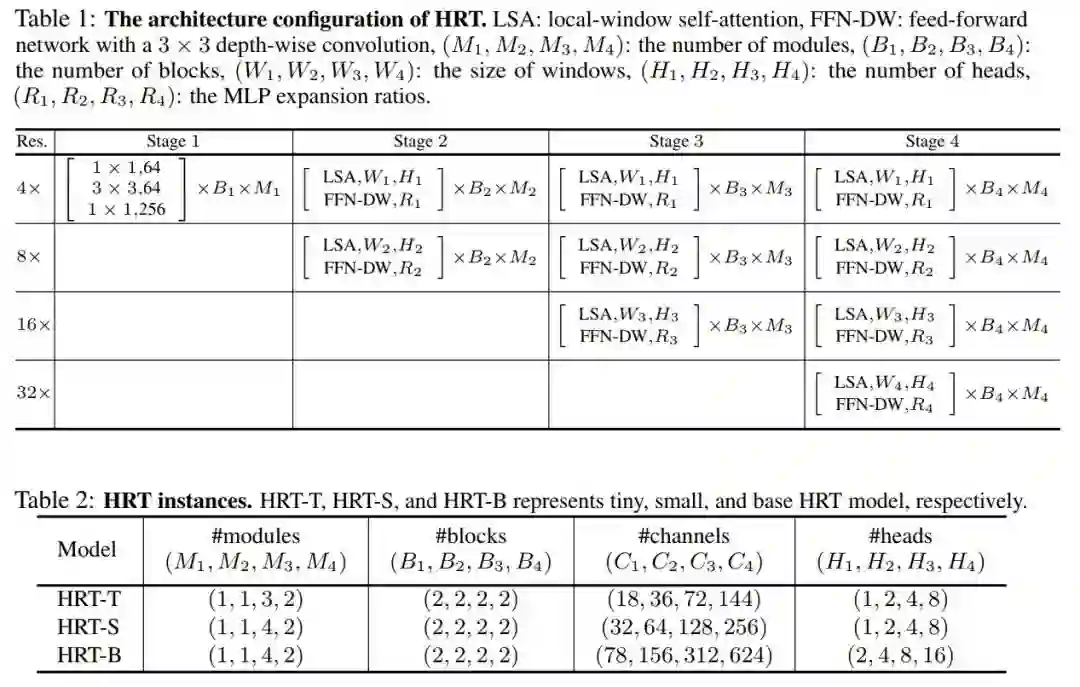
作者用(M1, M2, M3, M4)和(B1, B2, B3, B4)分别表示{state1, stage2, stage3, stage4}的模块数和块数;用(C1, C2, C3, C4), (H1, H2, H3, H4)和(R1, R2, R3, R4)来表示不同分辨率下Transformer Block的通道数,Head数和MLP膨胀比。
按照原始的HRNet保持第一阶段不变,并使用Bottleneck作为基本的构建块。将Transformer Block应用于其他阶段,每个Transformer Block由一个局部窗口自注意力和一个具有3x3深度卷积的FFN组成。
为了简单起见,在表1中没有包含卷积多尺度融合模块。在实现中默认将4个分辨率流上的窗口大小设置为(7,7,7,7)。表2展示了3个不同的HRT实例的配置细节,其中所有模型的MLP膨胀比(R1,R2,R3,R4)都被设置为(4,4,4,4)。
3.6 Analysis
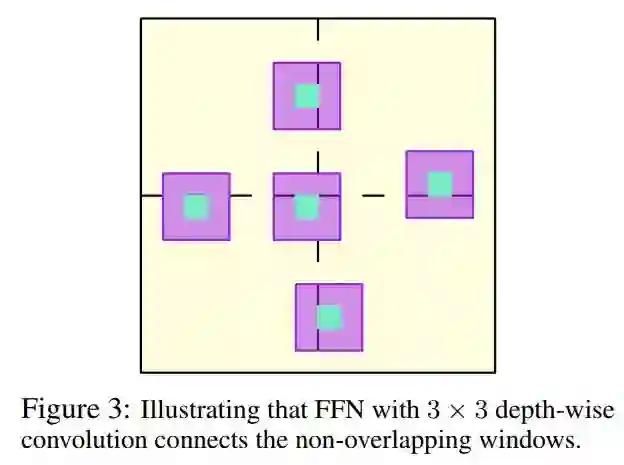
在图3中说明了具有深度卷积的FFN如何能够将交互扩展到非重叠的局部窗口之外,并对它们之间的关系建模。因此,结合局部窗口自注意力和3×3深度卷积的FFN,可以构建出显著提高内存和计算效率的HRT Transformer Block。
4 实验
4.1 姿态估计
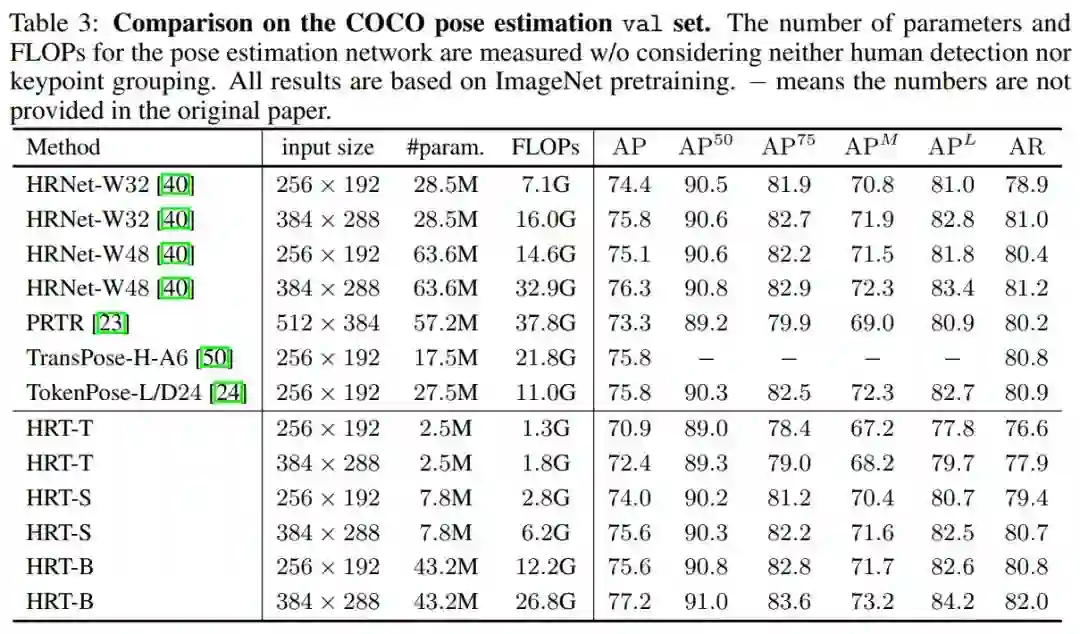
表3在COCO val上将HRT与具有代表性的卷积方法进行了比较,如HRNet和最近的几种变换方法,包括PRTR、TransPose-H-A6和TokenPose-L/D24。与384x288的HRNet-W48相比,HRT-B的增益为0.9%,参数减少了32%,FLOPs数减少了19%。因此,HRT-B已经达到77.2%的w/o使用任何先进的技术,如利用UDP或DARK方案HRT-B可以实现更好的结果。
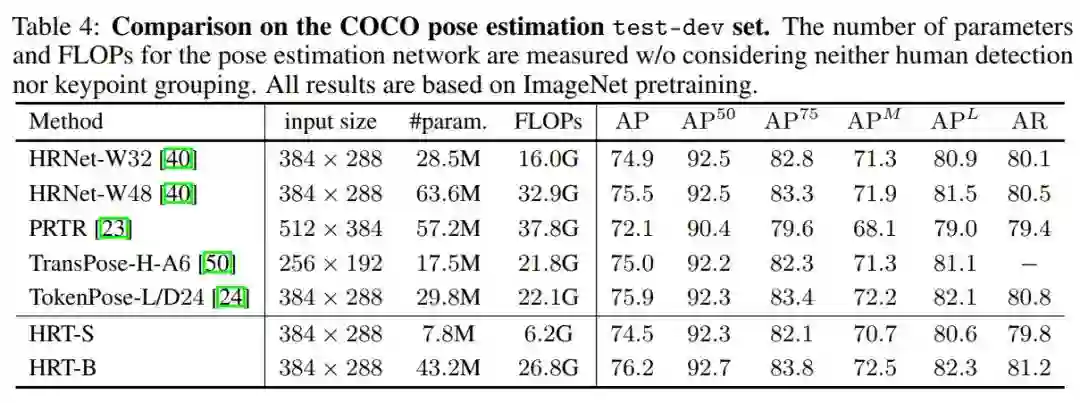
作者还在表4中根据COCO测试集上的比较。HRT-B的性能比HRNet-W48高0.7%左右,参数和FLOPs更少。图4显示了在COCO val集合上进行人体姿态估计的一些示例结果。
4.2 语义分割
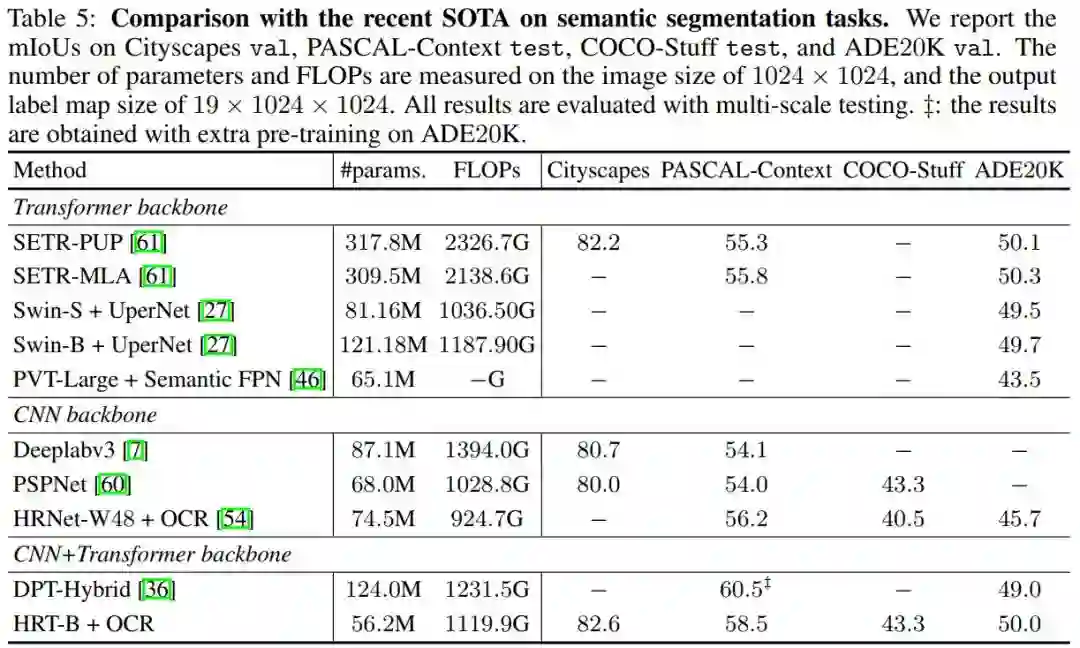
表5显示了Cityscapes val的结果。作者选择使用HRT+OCR作为语义分割架构。作者将本文方法与几种知名的基于Vision Transformer的方法和基于CNN的方法进行了比较。
具体来说,SETR-PUP和SETRMLA使用ViT-Large作为Backbone。DPT-Hybrid使用 ViT-Hybrid由一个ResNet-50和12个Transformer层组成。ViT-Large和ViT-Hybrid都是用ImageNet-21k上预训练的权值进行初始化的,在ImageNet上它们的Top1精度都达到了85:1%。
DeepLabv3和PSPNet是基于扩展的ResNet-101,输出stride为8。从表5的第4列可以看出,HRT+OCR整体上具有竞争力。例如,HRT-B+OCR与SETR-PUP在节省70%的参数和50%的FLOPs数的同时实现了相当的性能。
4.3 图像分类
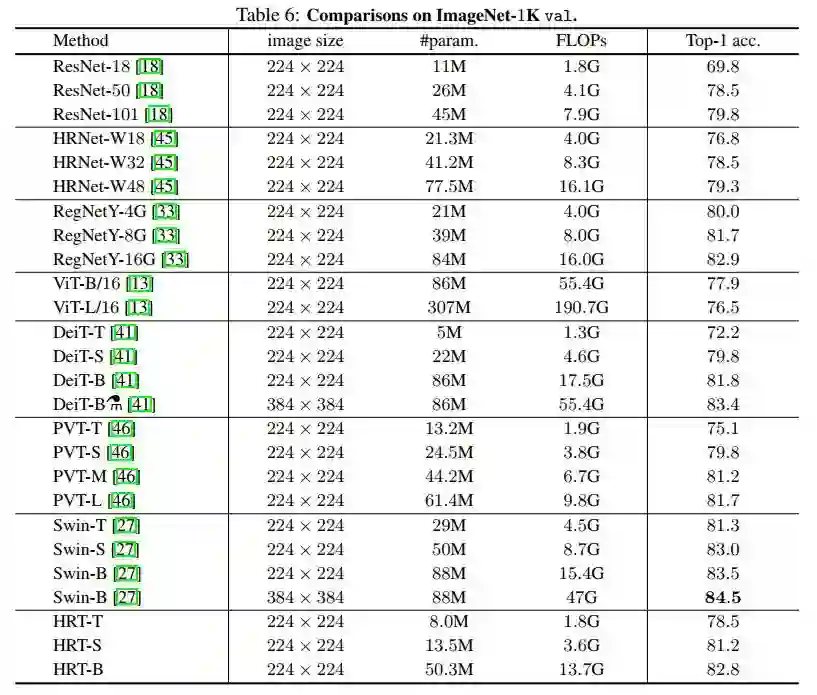
作者将HRT与表6中一些代表性的CNN方法和ViT Transformer方法进行了比较,其中所有方法仅在 ImageNet-1K 上训练。为了公平性, ViT-Large大数据集(如ImageNet-21K)的结果不包括在内。从表6可以看出,HRT取得了具有竞争力的效果。例如,HRT-B比DeiT-B增加了1.0%,同时节省了近40%的参数和20%的FLOPs。
4.4 消融实验
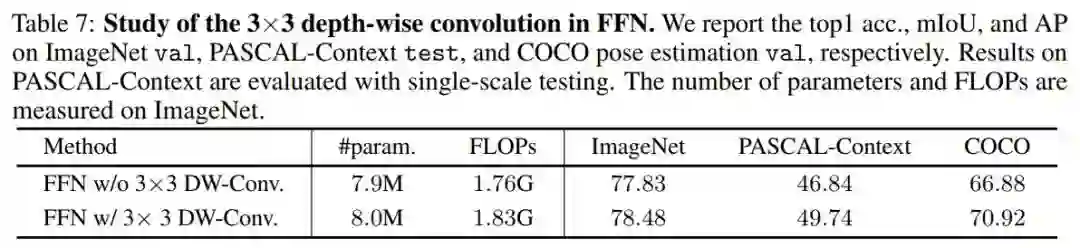
1. FFN中3×3深度卷积的影响
在表7中研究了基于HRT-T的FFN内的3×3深度卷积的影响。作者观察到,在FFN中应用3×3深度卷积显著提高了在多个任务上的性能,包括ImageNet分类、pascal上下文分割和COCO姿态估计。
例如,在ImageNet、PASCAL-Context和COCO上,HRT-T+FFN w/ 3×3深度卷积比HRT-T+FFN w/ 3× 3深度卷积分别高出0.65%、2.9%和4.04%。
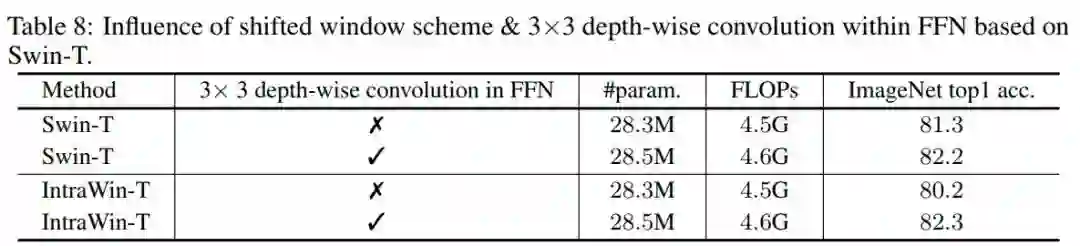
2. FFN中移动窗口方案与3×3深度卷积的影响
作者将本文方法与表8中Swin Transformer的移位窗口方案进行了比较。为了进行公平的比较,按照与Swin Transformer相同的架构配置构造了一个Intra-Window transformer架构,只是不应用移位的窗口模式。
可以看到,在FFN中应用3×3深度卷积可以改善Swin-T和IntrawinT。令人惊讶的是,当在FFN内配备3× 3深度卷积时,Intrawin-T的性能甚至超过了Swin Transformer。
3. 移位窗口方案vs . 3×3基于HRT-T的FFN深度卷积
在表9中,比较了FFN方案中的3×3深度卷积与基于HRT-T的移位窗口方案。结果表明,在FFN中应用3×3深度卷积在所有不同任务中的性能显著优于移位窗口方案。
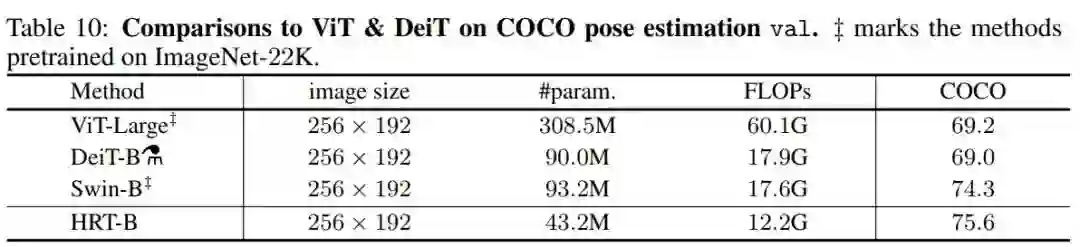
4. 与ViT、DeiT和Swin在姿态估计上的比较
在表10中比较了著名的Transformer模型,包括ViT-Large, DeiT-B和Swin-B的COCO位姿估计结果。值得注意的是,ViT-Large和Swin-B都是事先在ImageNet21K上进行预训练,然后在ImageNet1K上进行微调,分别达到85.1%和86.4%的top-1准确率。DeiT-B在ImageNet1K上训练1000个Epoch,达到85.2%的top-1精度。对于三种方法,使用反卷积模块按照SimpleBaseline对编码器的输出表示进行上采样。表10的第4列和第5列列出了参数和flop的数量。根据表10的结果,可以看到HRT-B在参数和FLOPs更少的情况下比这3种方法获得了更好的性能。
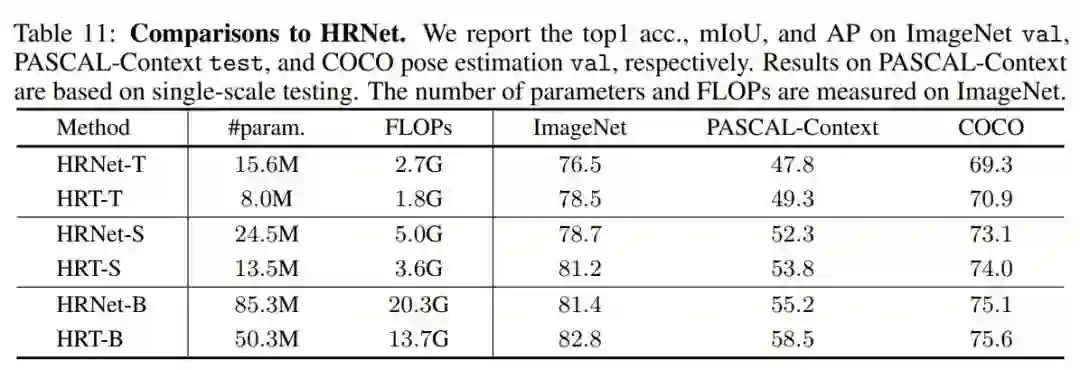
5. 相比HRNet
作者将HRT与具有几乎相同架构配置的卷积HRNet进行比较,方法是将所有的Transformer块替换为由2个3x3卷积组成的传统基本块。表11显示了ImageNet、PASCAL-Context和COCO的对比结果。
可以观察到,HRT在模型和计算复杂度更低的情况下,在各种配置下都显著优于HRNet。例如,HRT-T在3个任务中分别比HRNet-T高出2.0%、1.5%和1.6%,而只需要大约50%的参数和FLOPs。总之,HRT通过利用Transformer的好处获得了更好的性能。
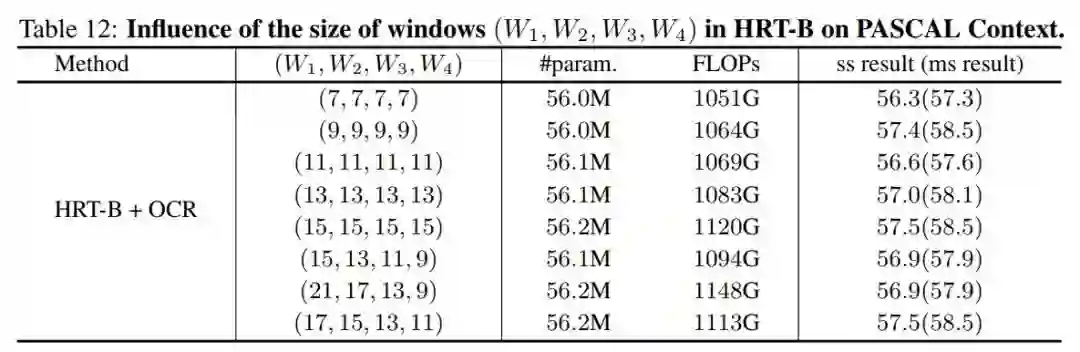
6. 窗口尺寸
作者还比较了在不同分辨率下不同窗口大小的语义分割任务的结果。使用
,用stride表示不同分辨率的feature map关联的窗口大小4,8,16,32。作者为更高分辨率的分支选择更大的窗口大小,因此,有
。根据这些结果,可以看到,应用较大的 窗口可以提高性能,而在不同分辨率下应用不同的窗口大小没有太大的区别。
[1].HRFormer: High-Resolution Transformer for Dense Prediction
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~
![]()
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
![]()