EMNLP 2019 丨微软亚洲研究院精选论文解读

转载自:微软研究院AI头条(ID:MSRAsia)
编者按:EMNLP 2019于11月3日至11月7日在中国香港举办。本届 EMNLP 大会中,微软亚洲研究院共21篇论文入选,涵盖预训练、语义分析、机器翻译等研究热点。本文为大家介绍其中的7篇精选论文。
可视化和理解 BERT 的有效性
Visualizing and Understanding the Effectiveness of BERT
论文链接:https://arxiv.org/abs/1908.05620
预训练语言模型 BERT 等在很多 NLP 任务上取得了显著提升,但大家对其有效性的原因尚未充分理解。本文通过可视化模型微调过程的损失表面和优化轨迹来尝试理解 BERT 的有效性,发现预训练过程可以使模型在下游任务上达到一个较好的初始点,并且微调 BERT 所得到的模型有更强的泛化能力。
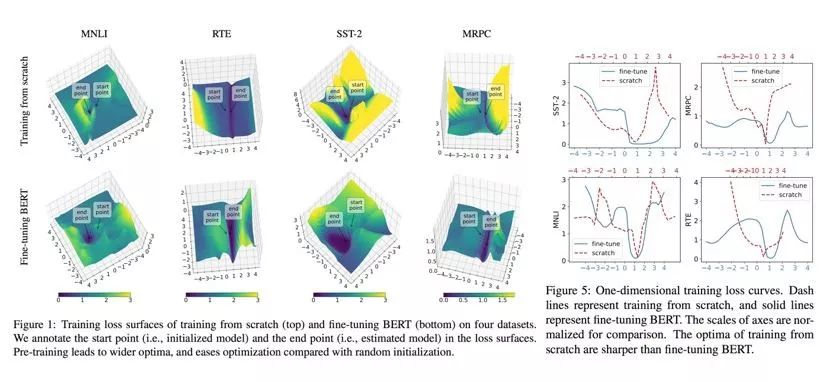
图1:微调 BERT 相对于从随机初始化有着更广阔且更平坦的优化区域
首先我们在不同任务上对比了微调 BERT 和从随机初始化这两种训练方式,通过可视化它们的一维和二维训练损失表面,可以看出微调 BERT 相对于从随机初始化有着更广阔且更平坦的优化区域。
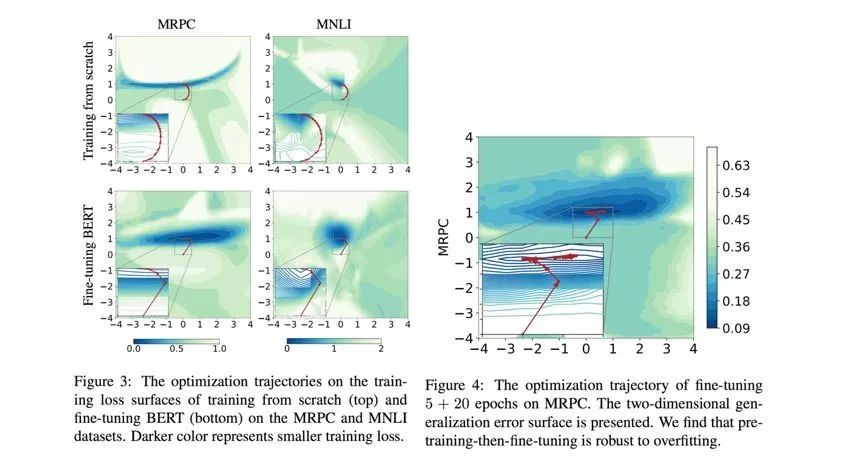
图2:微调 BERT 可以更直接地找到优化方向,并对过拟合更加鲁棒
之后通过可视化微调 BERT 和从随机初始化的优化轨迹,可以看出微调 BERT 可以更直接地找到优化方向,并且优化路径更加平缓,这使其可以更快收敛。另外,我们发现即使在小数据(如 MRPC)上对模型微调更多的轮数,优化轨迹显示其并未发生明显的过拟合现象。
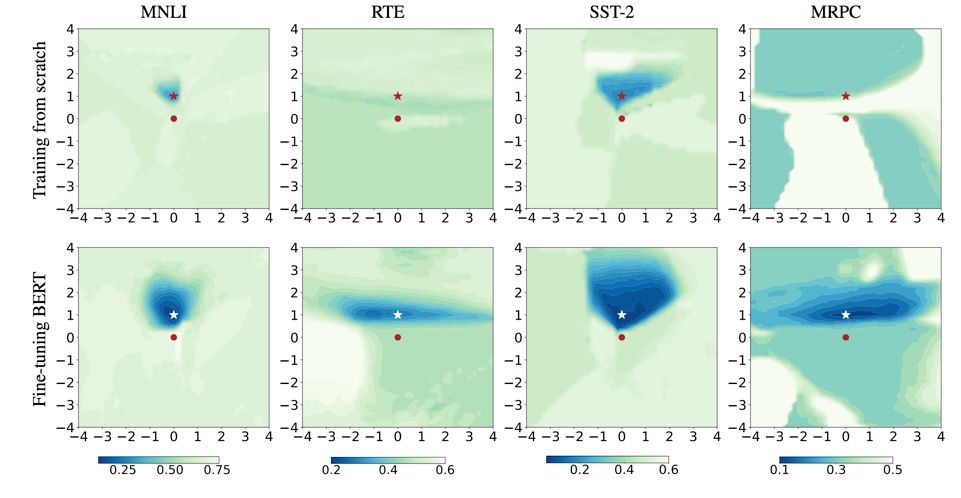
图3:微调 BERT 在泛化误差表面上有较大的局部最优区域,表明预训练带来更强的模型泛化能力
以往工作表明更广阔、平坦的局部最优区域往往有更强的泛化能力。我们比较了微调 BERT 和随机初始化,可以看出微调 BERT 在泛化误差表面上依然有较大的局部最优区域,这与训练损失表面一致,表明预训练可以带来更强的模型泛化能力。
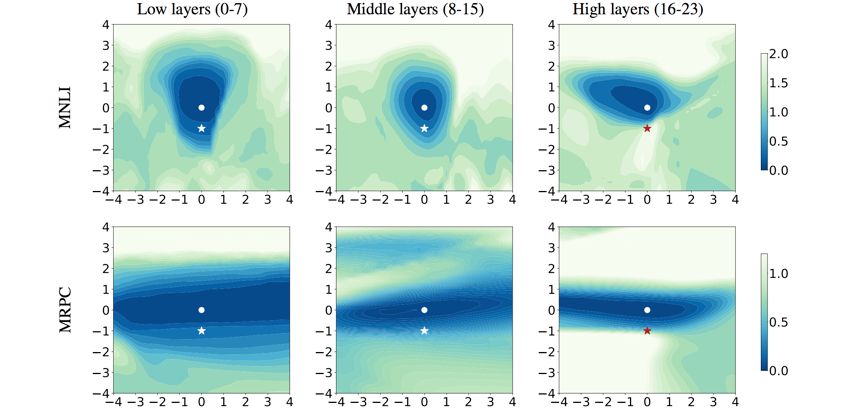
图4:BERT 网络底层可迁移性更强,而高层则更多学习了和下游任务相关的知识
此外,本文还可视化了针对不同层的训练损失表面,可以发现 BERT 较低层的损失表面有更广阔的局部最优区域。说明了 BERT 网络底层可迁移性更强,而高层则更多学习了和下游任务相关的知识。
利用规则和预训练网络进行文本正式性风格迁移
Harnessing Pre-Trained Neural Networks with Rules for Formality Style Transfer
论文链接:https://aka.ms/AA6h0mm
文本正式性(Formality)的研究对于广泛的自然语言处理应用都有着重要的作用,例如辅助非母语者的写作助手和儿童教育等。随着深度学习技术在自然语言领域的不断发展,研究人员已经可以进行初步的非正式到正式文本的改写。
本文从监督学习的角度对文本正式性改写进行研究,主要关注由非正式文本到正式文本的改写。传统的基于监督学习的方法多从机器翻译领域借鉴模型,例如直接使用 Seq2Seq 模型或 Transformer 模型基于平行语料进行训练。研究人员的进一步研究表明使用经过规则处理的非正式文本与原始正式文本进行训练可以得到更好的结果。我们发现引入规则的流水线式方法虽然有效降低了数据的复杂性,使模型能够更容易地学习到一些复杂的模式,但由于规则自身的局限性,难免引入一些噪声。如图5所示,R & B 作为一个实体,应该保持大写。
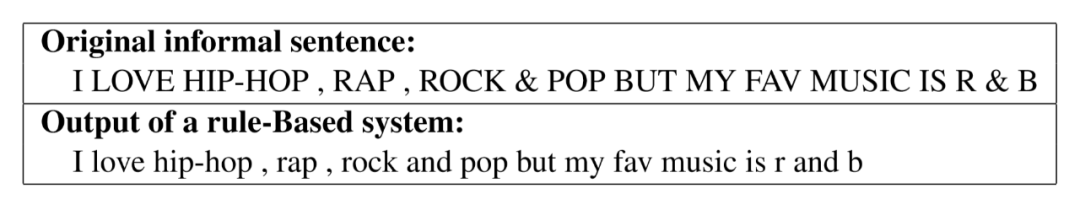
图5:原始非正式文本与基于规则的方法的结果
我们希望能够既引入规则的优点,也能剔除部分规则所带来的噪声。因此我们提出了三种利用原始非正式文本与基于规则的结果共同生成正式文本的方法,如图6所示:Concatenate Fine-tuning 使用一个编码器编码拼接后的两个输入文本,并使用一个解码器进行解码;Decoder Ensemble 使用两个编码器和解码器训练两个模型,并在推断阶段取两个模型预测的概率分布的平均值;Separate Encoding with Hierarchical Attention 使用两个编码器对两个输入文本分别编码,使用一个解码器结合 Hierarchical Attention 进行解码。
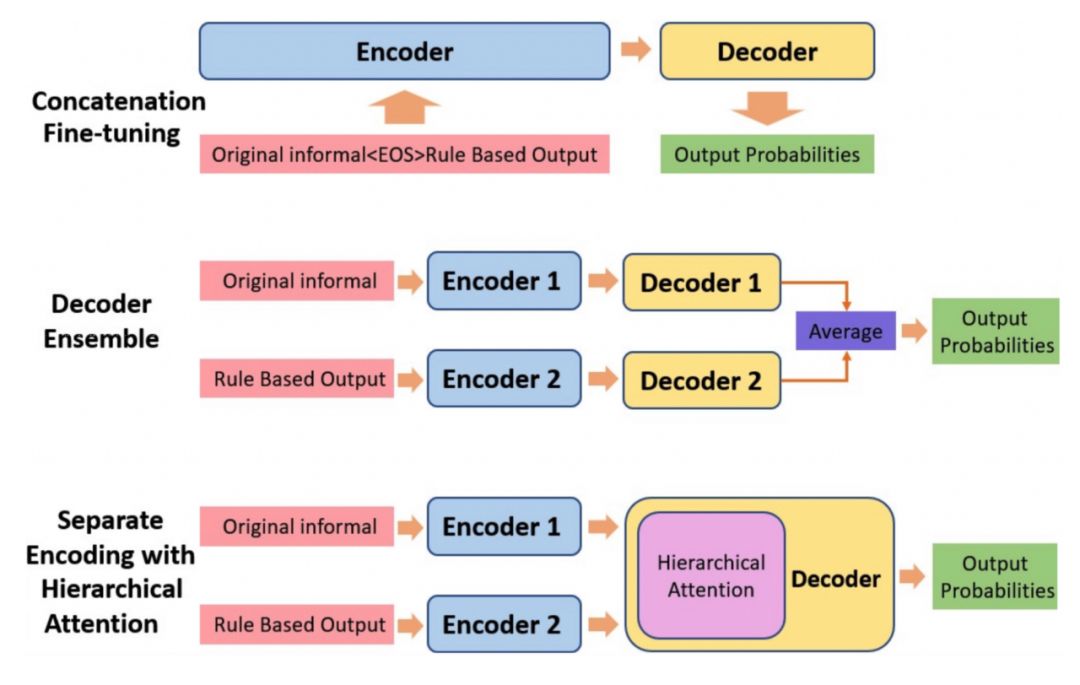
图6:将规则融入生成模型的三种方式
本文采用了先进的预训练语言模型——GPT2 来分别构建编码器和解码器。本文的编码器-解码器模型和 Transformer 的结构略有不同,如图7所示,编码器和解码器都使用 GPT2 的 block 结构且不共享参数。
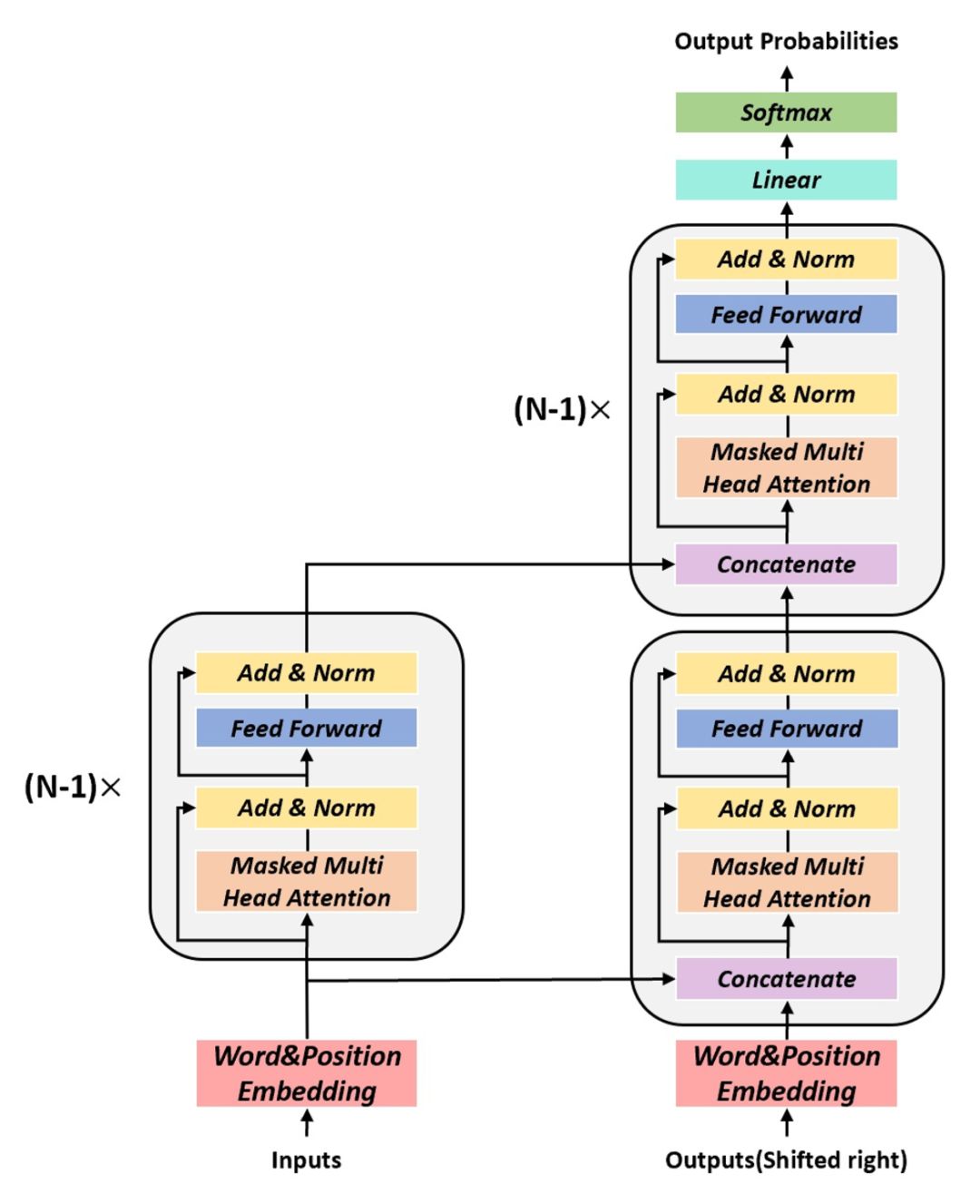
图7:基于 GPT2 构建的编码器-解码器生成模型
本文在 GYAFC 数据集上进行了实验,在 F&R 和 E&M 两个 domain 上的结果如表1和表2所示:
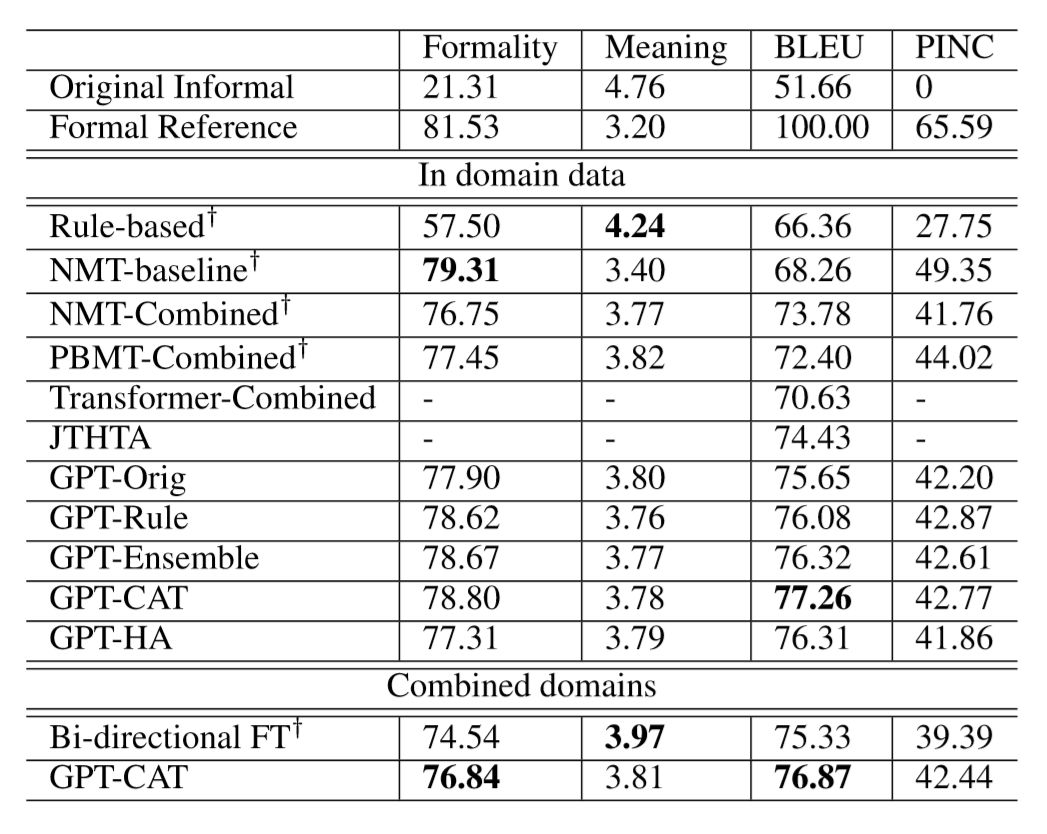
表1:在 Family & Relationship 上的实验结果
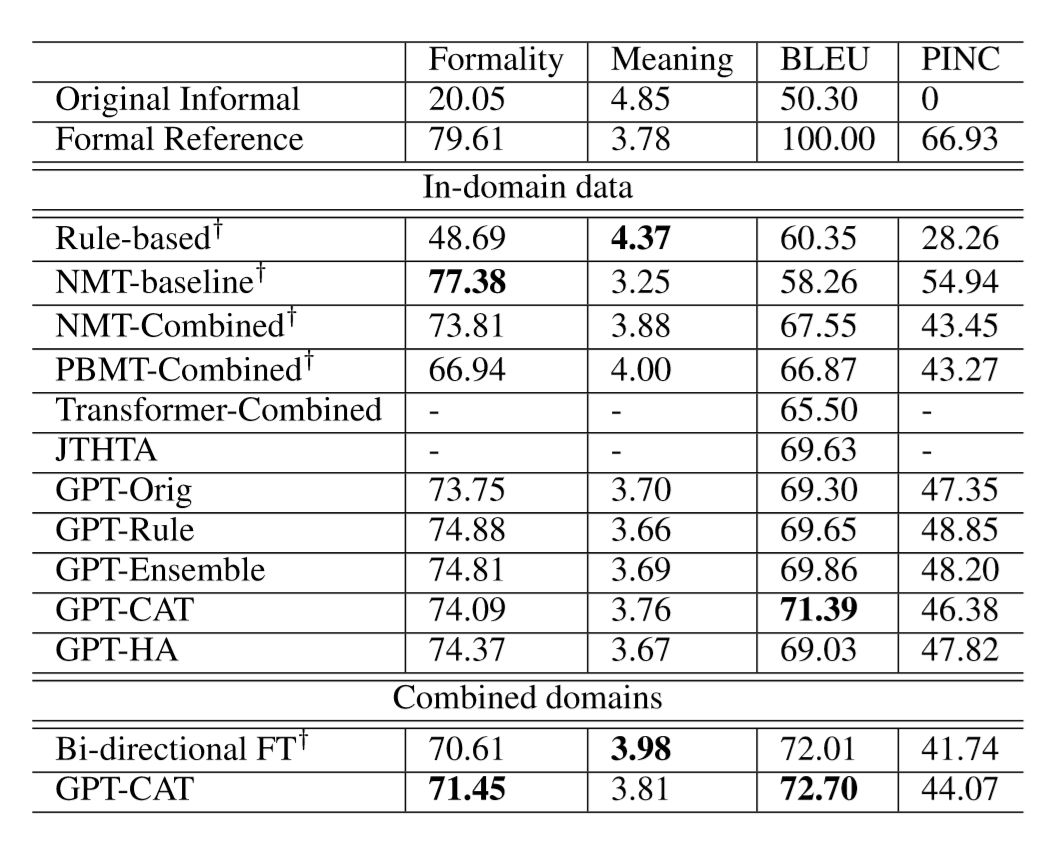
表2:在 Entertainment & Music 上的实验结果
可以看到本文提出的 GPT-CAT(Concatenate Fine-tuning)方法在不同的场景下(domain 是否合并)都表现出了一致的最优结果,我们认为很可能是因为使用同一个编码器进行编码,使得两个输入文本在编码阶段得到了更多的交互,因此得到了更好的编码表示。
开放域对话的无监督上下文改写
Unsupervised Context Rewriting for Open Domain Conversation
论文链接:https://arxiv.org/abs/1910.08282
在聊天机器人中,多轮对话理解一直是一个非常困难的问题。目前,如果输入是单轮对话,模型往往可以生成较好的回复,然而如果输入是多轮对话,机器所给出的回复往往不尽如人意。为了解决这个问题,我们提出利用改写的方法来帮助对上下文进行建模,将多轮对话输入改写为单轮对话输入,如图8所示。

图8:将多轮对话输入改写为单轮输入的示意图
在这里,我们使用多轮对话中的上下文信息来改写最后一轮的句子(query),在压缩了上下文信息的同时,也保留了对 query 最有用的信息。利用改写机制的好处在于:(1)改写后的句子具有很好的可解释性;(2)改写后的 query 不依赖于下游任务,因此可以分别提升检索式对话模型和生成式对话模型的效果;(3)改写后的 query 可以使用单轮对话的模型,该类模型的效果相对于传统的多轮对话模型较好,且计算量较小,适合线上系统。
利用改写机制需要解决以下问题:(1)如何从上下文中抽取出有用的信息;(2)如何将该部分信息注入 query 中。为解决以上问题,我们采用无监督的方法来构造被改写的语料,首先使用 Pointwise-Mutually-Information(PMI)算法根据 query 和 response(回复的句子),抽取上下文中与其共现概率最大的若干词作为关键信息。再使用语言模型将这些信息插入 query 中,计算不同插入位置的得分,进而得到被改写的 query。但是在实际的应用场景中,我们无法得到 response 的信息,所以我们采用一个基于复制网络(copy-net)的深度模型来学习这部分先验知识,并使用这些构造好的数据作为训练集,利用该训练集进行多轮对话上下文改写模型训练(Context Rewriting Network)。
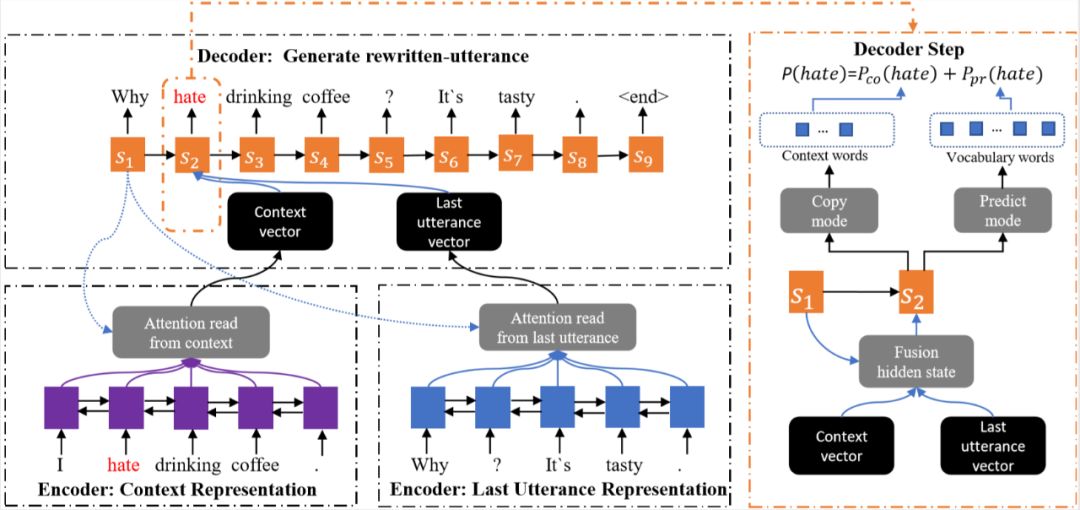
图9:多轮对话上下文改写模型
然而,基于无监督的改写方式存在一定的噪音,我们无法保证抽取出来的关键词是否有助于下游任务,尤其是存在检索式和生成式对话模型这两种不同任务。我们针对这两种不同任务,分别采用不同的奖励函数(Reward),采用强化学习方式对模型进行微调(fine-tune),最终使得我们的模型在生成式和检索式任务上均超越 baseline。而且由于使用了不同的奖励函数,我们经过强化学习后的微调模型也成功超越了原始模型。
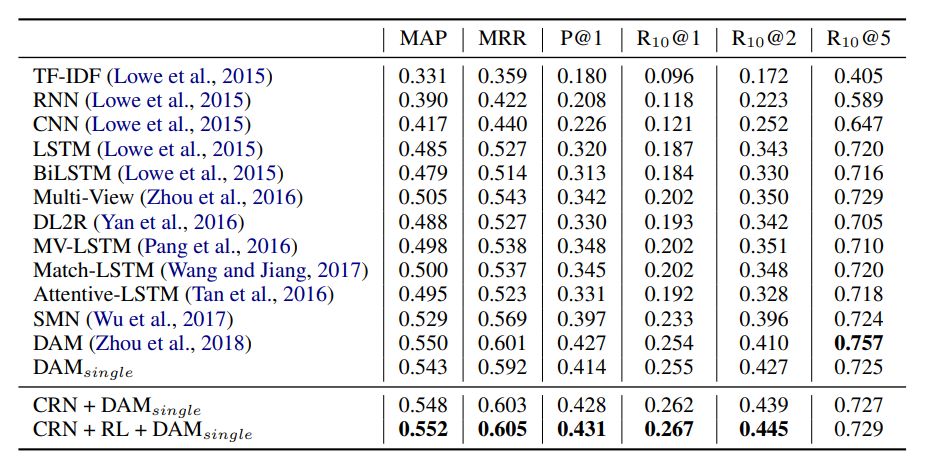
表3:得到检索候选后,将多轮对话改写并进行匹配度计算结果
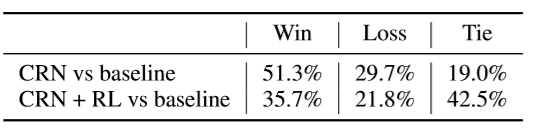
表4:端到端检索结果人工评价
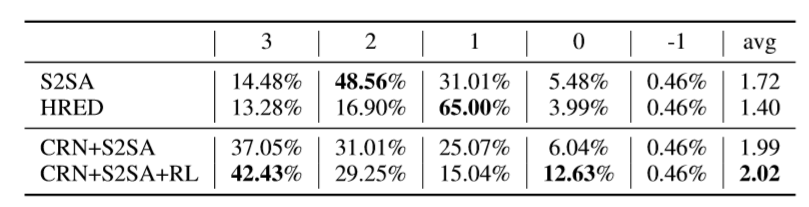
表5:端到端生成结果人工评价(其中3为最佳)
利用多任务学习解决基于大规模知识图谱的对话问答
Multi-Task Learning for Conversational Question Answering over a Large-Scale Knowledge Base
论文链接: https://arxiv.org/abs/1910.05069
基于大规模知识图谱的对话问答在智能私人助理系统(例如Cortana、Google Now、Siri、Alexa等)中起重要作用。近年来基于神经网络的语义解析(Semantic Parsing)方法在这个领域中取得了很大的进展。这种方法通过神经网络将自然语言转化为机器可执行的逻辑表达式(Logical Form),然后通过在知识图谱上执行逻辑表达式来获得最终答案。
然而,大部分已有的工作主要采用一种分步的方法来解决这个问题。一种典型的方法是,首先进行实体识别并链接到知识图谱中(Entity detection and linking),然后对谓词进行分类(Predicate classification), 最后生成机器可执行的逻辑表达式(Logical form generation)。这种方法的缺陷是受 error propagation 影响较大,并且由于各个模块独立进行训练,不能充分利用监督信息。
为了解决这些问题,本文提出一种基于多任务学习的方法。具体来说,我们将语义解析问题分解为两个子问题:(1)实体识别;(2)带实体位置的逻辑表达式生成。前者对带有上下文的自然语言问句进行序列标注,每个 word 都被分类为{O, {B, I} X NT}, 其中 O 表示非 entity,B、I分别表示 entity 的开始和中间,NT 代表 entity 类型个数,通过这种带有 entity 类型的实体识别,我们可以很好地解决实体链接(entity linking)过程中的歧义问题。后者通过 sequence to sequence with pointer network 来实现,将自然语言问句翻译为带实体位置的逻辑表达式,其中的实体由其在输入中的位置来表示。最后通过多任务学习同时对两个子问题进行学习。
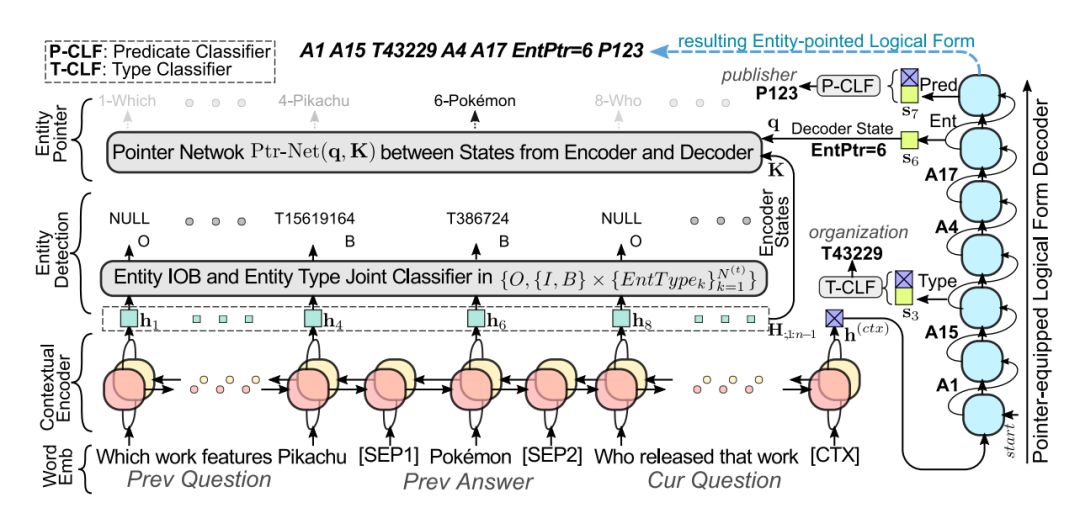
图10:多任务语义解析模型(MaSP)
这种方法具有以下优势:(1)多任务学习有效地利用了所有的监督信息;(2)由于上下文也同时输入到模型中,可以有效地解决 coreference 和 ellipsis 问题;(3)在逻辑表达式生成过程中,通过预测实体位置而不是实体本身,可以有效地处理大规模知识图谱中的大量实体;(4)实体识别中,通过预测实体的类型,可以有效地缓解实体链接过程中的歧义问题。在 CSQA 数据集上的实验验证了这个方法(MaSP)的有效性。
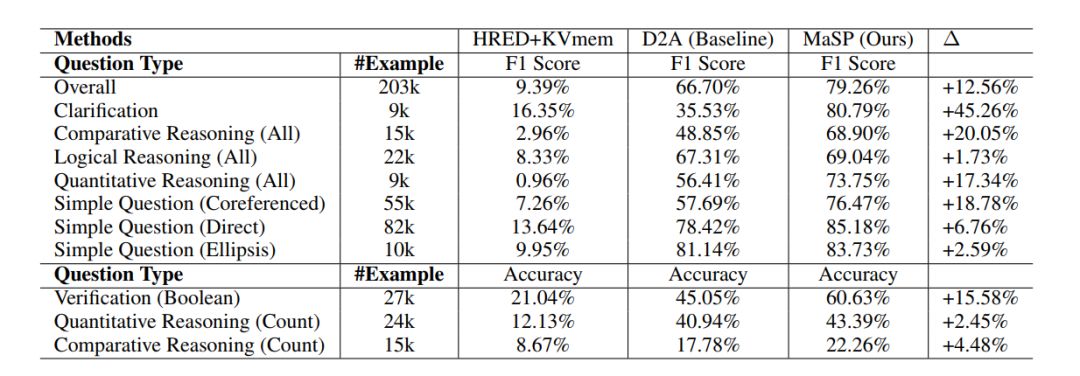
表6:基于 CSQA 数据集的实验结果
大规模利用单语数据进行神经机器翻译
Exploiting Monolingual Data at Scale for Neural Machine Translation
论文链接:https://aka.ms/AA6i2nr
在机器翻译中,目标语言端的无标数据被广泛的利用,例如反向翻译技术(back-translation)。相比之下,源语言端的无标数据并没有被广泛利用。本文系统地研究了如何同时利用源语言和目标语言端的无标数据,并提出了一种有效的数据使用流程。我们在 WMT 英德互译和 WMT 德法互译上验证了算法的有效性,并取得了非常优越的性能。
假设我们关注的是 X 和 Y 语言之间的互译。我们要在给定的有标双语数据集 B 上训练 X->Y 和 Y->X 两个翻译模型,分别记做 f 和 g。同时,我们需要准备两份无标数据 Mx 和 My,分别对应 X 和 Y 两种语言。我们提出的算法包括三步:
(1)无标注数据翻译:我们将 Mx 中的每一个句子用 f 翻译到 Y 语言,对 My 中的句子用 g 翻译到 X 语言,得到两个新的数据集合 Bs={(x, f(x))|x∈Mx}, Bt={(g(y),y)|y∈My}
(2)有噪声训练:我们给数据集 B、Bs 和 Bt 的源语言端都加上噪声,包括随机将单词替换为<UNK>,随机丢弃和随机打乱单词。在有噪声的数据集上,我们训练对应的模型 f1:X->Y 和 g1:Y->X。在此阶段,我们建议使用大规模无标数据。
(3)微调:得到 f1 和 g1 之后,我们用在不同双语数据上训练得到的新的双语模型f' 和 g' 来重新翻译 Mx 和 My 无标数据得到 Bs' 和 Bt',在这份数据上再将 f1 和 g1 微调成最终的模型。
我们的实验结果如表7所示。在第二阶段,我们选用了120M(两边分别60M)无标数据。第三阶段,使用40M(两边分别20M)无标数据。具体结果如下:
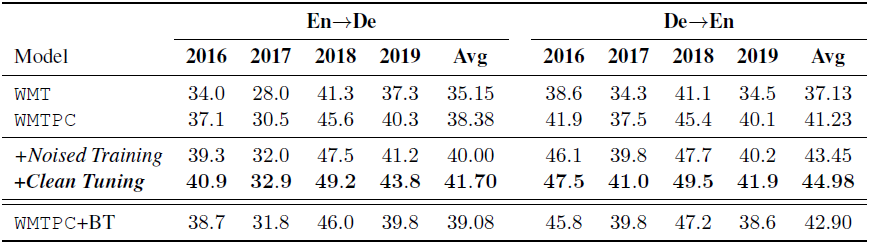
表7:实验结果
可以看出每一个阶段的结果都会有一定的提高,并且我们的方案取得了目前最好的结果。我们在德法互译任务上也取得了类似的结果。
在文章中,我们对不同的数据使用方案也进行了详细的讨论和对比。简单来说,我们验证了:(1)源端和目标端的无标数据都是有用的;(2)有噪声训练这一阶段对提升最终性能有帮助;(3)只使用源端或者目标端无标数据,效果不会随着数据的增加而增加。如果同时使用上述两种数据,在我们的实验中,实验效果会随着数据的增多而得到提升。
利用训练好的自回归模型来优化非自回归模型
Hint-Based Training for Non-Autoregressive Machine Translation
论文链接:https://arxiv.org/pdf/1909.06708.pdf
目前最先进的神经机器翻译模型都采用自回归概率分解,即在解码过程中逐个生成目标词语。这种计算模式在现有的并行硬件(如GPU)上受到限制,使得其具有较高的推理延迟。最近提出的非自回归机器翻译模型减少了模型所需要的时间,但只能达到较低的翻译精度。为了提高非自回归模型的翻译精度,我们提出一种新的方法,利用训练好的自回归模型来帮助非自回归模型的优化。
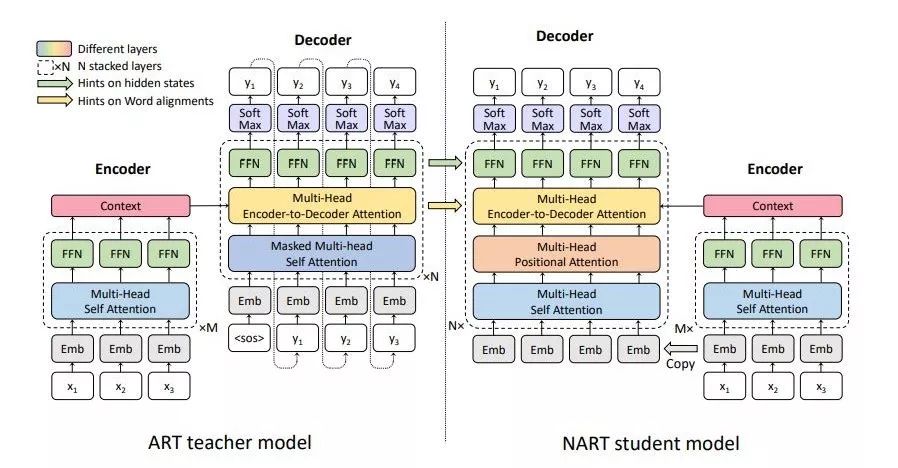
具体地,我们定义了两种来源于自回归模型的“提示”:来自隐状态的提示与来自词对齐与注意力机制的提示,并利用这些提示来正则化非自回归模型的训练。实验结果显示我们的新模型比之前的模型显著提高了翻译质量。具体地,针对 WMT14 英语-德语和德语-英语任务,我们分别得到了25.20和29.52 BLEU 值的结果,大幅超越之前的非自回归翻译基线模型。
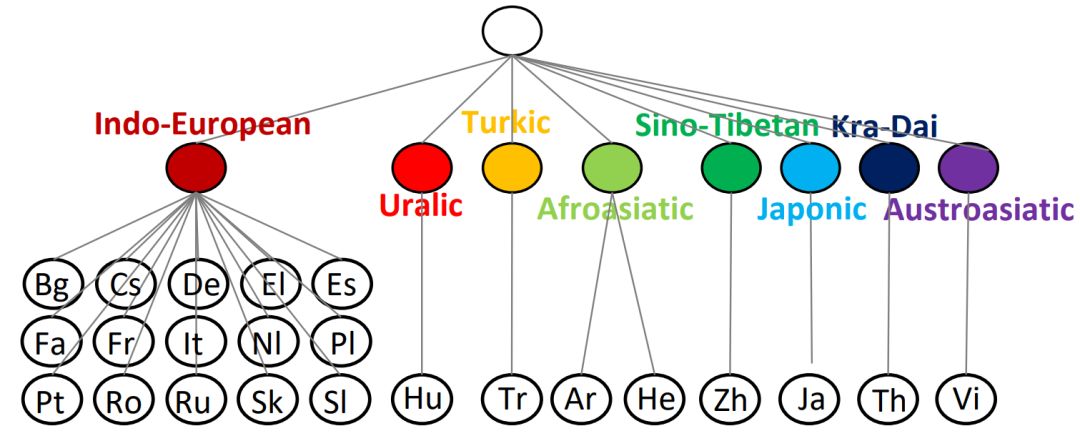
图12:语系分类
在第二种基于语言向量的聚类中,我们对所有语言训练了一个多语言翻译模型,并在模型中用语言向量来区分不同的语言,语言向量在多语言翻译模型中一起被训练,可以用来表示不同语言的特征,如图13所示。我们使用层次聚类法对得到的语言向量进行聚类。
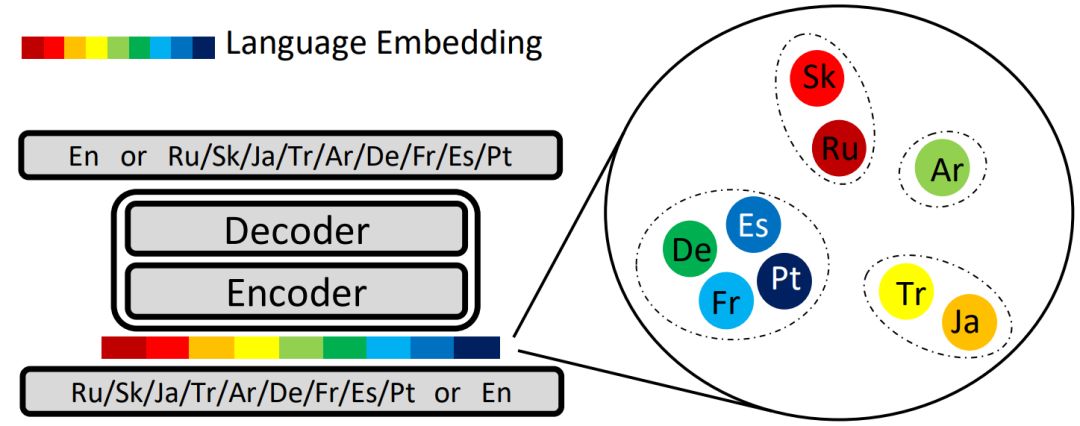
图13:在多语言机器翻译模型中学习语言向量来进行聚类
下面是实验评估,我们选用了 IWSLT 2011~2018年,英语和23种其它语言之间的翻译对进行实验。
首先看语言的聚类结果。基于先验知识的聚类结果如上图12所示。基于语言向量的聚类结果如图14所示。我们有几点发现:(1)语言向量能很好的捕获语言的语系关系;(2)语言向量也能反映语言的形态学信息;(3)语言向量还能捕获语言的一些由于区域、文化以及历史因素的影响形成的关系。具体分析可见论文。

图14:基于语言向量的聚类结果
然后看语言聚类的翻译精度,表8列出了英语到其它语言的实验结果,最后一列为23个翻译的 BLEU 平均值。可以看到基于语言向量(Embedding)的聚类方法得到的模型要好于基于语系(Family)的聚类,同时比一个模型支持所有语言(Universal)以及每个语言分别用各自的模型(Individual)要好。Universal 模型的翻译精度较差,而 Individual 模型增加了离线训练和在线维护成本,这也是本文工作要解决的问题。我们基于语言向量(Embedding)的聚类在只用5个模型的成本上,相比 Individual(成本为23个模型)在23个语言的平均 BLEU 高0.7,相比 Universal(成本为1个模型)的平均 BLEU 高2.08,显示了我们的聚类方法对于降低模型训练维护成本以及提升翻译精度的有效性。更多实验结果和分析参见论文。
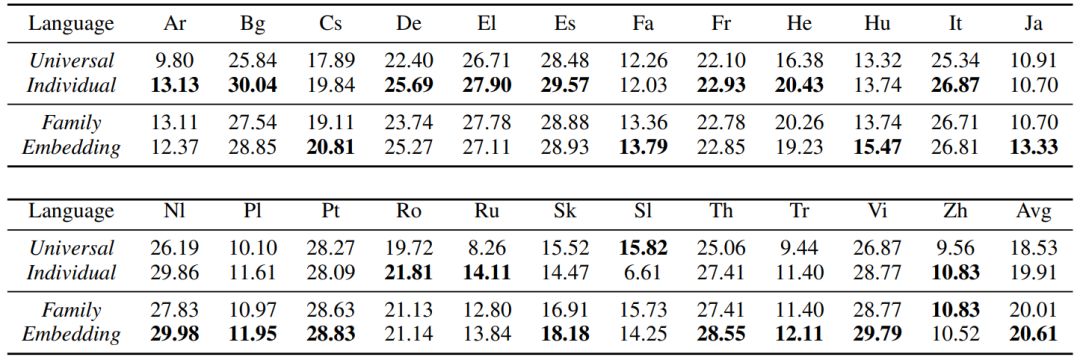
表8:实验结果
——END——






