一文读懂机器学习中奇异值分解SVD
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
目录:
矩阵分解
1.1 矩阵分解作用
1.2 矩阵分解的方法一文读懂机器学习中奇异值分解SVD
1.3 推荐学习的经典矩阵分解算法
SVD具体介绍
2.1 特征值、特征向量、特征值分解
2.2 SVD分解
2.3 SVD分解的应用
1. 矩阵分解
1.1 矩阵分解作用
矩阵填充(通过矩阵分解来填充原有矩阵,例如协同过滤的ALS算法就是填充原有矩阵)
清理异常值与离群点
降维、压缩
个性化推荐
间接的特征组合(计算特征间相似度)
1.2 矩阵分解的方法
特征值分解。
PCA(Principal Component Analysis)分解,作用:降维、压缩。
SVD(Singular Value Decomposition)分解,也叫奇异值分解。
LSI(Latent Semantic Indexing)或者叫LSA(Latent Semantic Analysis),隐语义分析分解。
PLSA(Probabilistic Latent Semantic Analysis),概率潜在语义分析。PLSA和LDA都是主题模型,PLSA是判别式模型。
NMF(Non-negative Matrix Factorization),非负矩阵分解。非负矩阵分解能够广泛应用于图像分析、文本挖掘和语言处理等领域。
LDA(Latent Dirichlet Allocation)模型,潜在狄利克雷分配模型。LDA是一种主题模型,将文档集中每篇文档的主题以概率的形式给出,可以用于主题聚类或者文本分类,是生成式模型。LDA作为主题模型可以应用到很多领域,比如:文本情感分析、文本分类、个性化推荐、社交网络、广告预测等方面。
MF(Matrix Factorization)模型,矩阵分解模型。矩阵分解其实可以分为很多种:
基本矩阵分解(Basic Matrix Factorization),basic MF分解。
正则化矩阵分解(Regularized Matrix Factorization)。
概率矩阵分解(Probabilistic Matrix Factorization),PMF。
非负矩阵分解(Non-negative Matrix Factorization),NMF。
正交非负矩阵分解(Orthogonal Non-negative Matrix Factorization)。
PMF(Probabilistic Matrix Factorization),概率矩阵分解。
SVD++
关于矩阵分解的方法大概就是上面这些。矩阵分解的主要应用是:降维、聚类分析、数据预处理、低维度特征学习、特征学习、推荐系统、大数据分析等。上面把主要的矩阵分解方法给列出来了,比较混乱,再给大家摆上一张矩阵分解发展的历史:

图1:矩阵分解发展历史
1.3 推荐学习的经典矩阵分解算法
矩阵分解的算法这么多,给大家推荐几个经典的算法来学习:
1) 经典的PCA、SVD是机器学习入门必学算法。
2)2003年提出的主题模型LDA,在当年提出的时候,也是大红大紫,现在也在广泛的应用,可以学习一下。
3)概率矩阵分解(PMF),主要应用到推荐系统中,在大规模的稀疏不平衡Netflix数据集上取得了较好的结果。
4)非负矩阵分解,也很重要。非负矩阵分解及其改进版本应用到很多领域中。
2.SVD具体介绍
2.1 特征值、特征向量、特征值分解
特征值分解和奇异值分解在机器学习中都是很常见的矩阵分解算法。两者有着很紧密的关系,特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征。
1)特征值、特征向量
如果一个向量v是矩阵A的特征向量,将一定可以表示成下面的形式:
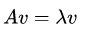
其中,λ是特征向量v对应的特征值,一个矩阵的一组特征向量是一组正交向量。
思考:为什么一个向量和一个数相乘的效果与一个矩阵和一个向量相乘的效果是一样的呢?
答案:矩阵A与向量v相乘,本质上是对向量v进行了一次线性变换(旋转或拉伸),而该变换的效果为常数λ乘以向量v。当我们求特征值与特征向量的时候,就是为了求矩阵A能使哪些向量(特征向量)只发生伸缩变换,而变换的程度可以用特征值λ表示。
2)特征值与特征向量的几何意义
一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。比如说下面的这个矩阵:
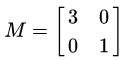
它其实对应的线性变换是图2的形式:
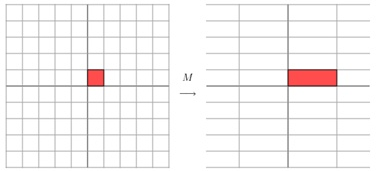
图2:矩阵M的线性变换
因为这个矩阵M乘以一个向量(x,y)的结果是:
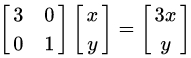
上面的矩阵是对称的,所以这个变换是一个对x、y轴的方向一个拉伸变换(每一个对角线上的元素将会对一个维度进行拉伸变换,当值大于1时是拉伸,当值小于1时是缩短),如图2所示。当矩阵不是对称的时候,假如说矩阵是下面的样子:
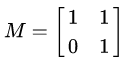
它所描述的变换是下面的样子:
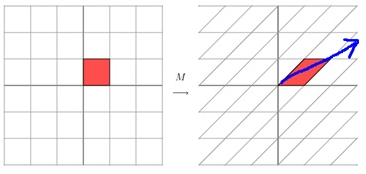
图3:M是非对称矩阵变换
这其实是在平面上对一个轴进行的拉伸变换,如图3蓝色的箭头所示,蓝色的箭头是一个最主要的变换方向(变换的方向可能不止一个)。如果想要描述好一个变换,那我们就需要描述好这个变换主要的变化方向。
2)特征值分解
对于矩阵A,有一组特征向量v,将这组向量进行正交化单位化,就能得到一组正交单位向量。特征值分解,就是将矩阵A分解为如下式:
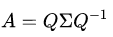
其中,Q是矩阵A的特征向量组成的矩阵,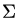
我们来分析一下特征值分解的式子,分解得到的Σ矩阵是一个对角矩阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变换方向(从主要的变化到次要的变化排列)。
当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,这个线性变换可能没法通过图片来表示,但是可以想象,这个变换也同样有很多的变化方向,我们通过特征值分解得到的前N个特征向量,就对应了这个矩阵最主要的N个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵变换。也就是之前说的:提取这个矩阵最重要的特征。
总结:特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多么重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
以上图文的方式介绍特征值特征向量内容来自:
http://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html
3)特征值分解的例子
这里我们用一个简单的方阵来说明特征值分解的步骤。我们的方阵A定义为:
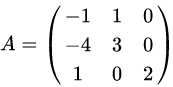
首先,由方阵A的特征方程,求出特征值。
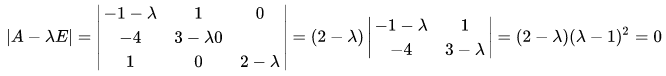
特征值为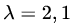
然后,把每个特征值λ带入线性方程组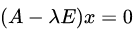
当λ=2时,解线性方程组 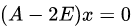
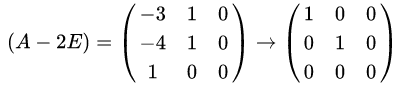
解得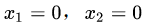
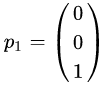
当λ=1时,解线性方程组
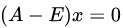
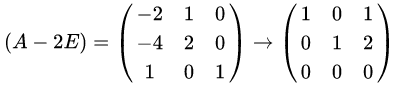
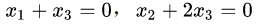
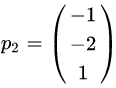
最后,方阵A的特征值分解为:
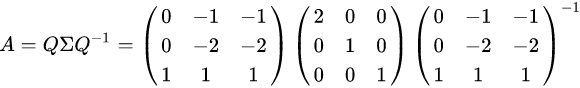
2.2 SVD分解
1)特征值分解矩阵的缺点
我们前面讲了很多特征值、特征向量和特征值分解,而且基于我们以前学习的线性代数知识,利用特征值分解提取特征矩阵是一个容易理解且便于实现的方法。但是为什么还存在奇异值分解呢?特征值分解最大的问题是只能针对方阵,即n*n的矩阵。而在实际的应用中,我们分解的大部分都不是方阵。
举个例子:
关系型数据库中的某一张表的数据存储结构就类似于一个二维矩阵,假设这个表有m行,有n个字段,那么这个表数据矩阵规模就是m*n。很明显,在绝大部分情况下,m与n是不相等的。如果这个时候要对这个矩阵进行特征提取,特征值分解的方法明显就不行了。此时,就可以用SVD对非方阵矩阵进行分解。
2)奇异值分解
奇异值分解是一个能适用于任意矩阵的一种分解的方法,对于任意矩阵A总是存在一个奇异值分解:
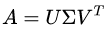
假设A是一个m*n的矩阵,那么得到的U是一个m*m的方阵,U里面的正交向量被称为左奇异向量。Σ是一个m*n的矩阵,Σ除了对角线其它元素都为0,对角线上的元素称为奇异值。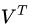

图4:奇异值分解中各个矩阵维度变化
思考:虽说上面奇异值分解等式成立,但是如何求得左奇异向量、右奇异向量和奇异值呢?
答案:由上面的奇异值分解等式,我们是不知道如何拆分矩阵A的。我们可以把奇异值和特征值联系起来。
首先,我们用矩阵A的转置乘以A,得到一个方阵,用这样的方阵进行特征分解,得到的特征值和特征向量满足下面的等式:
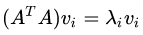
这里的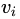
其次,我们将A和A的转置做矩阵的乘法,得到一个方阵,用这样的方阵进行特征分解,得到的特征和特征向量满足下面的等式:
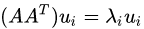
这里的 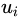
思考:上面我们说 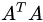
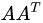
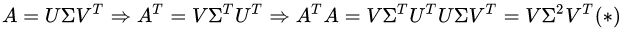
上式证明中使用了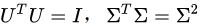
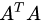
组成的矩阵就是我们SVD中的V矩阵,而
补充定义:
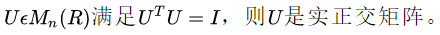
此外,我们还可以得到奇异值,奇异值求法有两种:
a) 第一种:
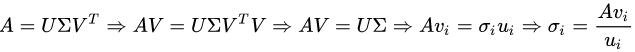
b)第二种:
通过上面*式的证明,我们还可以看出,特征值矩阵等于奇异值矩阵的平方,也就是说特征值和奇异值满足如下关系:
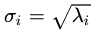
这里的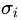
思考:我们已经知道如何用奇异值分解任何矩阵了,那么问题又来了,一个m*n的矩阵A,你把它分解成m*m的矩阵U、m*n的矩阵Σ和n*n的矩阵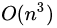
补充:两个矩阵A:m*n,B:n*p相乘,时间复杂度(O(nmp))。分析伪代码如下:
input:int A[m,n],B[n,p]
Let C be a new matrix of the appropriate size
for i in 1 to n
for j in 1 to p
Let sum = 0
for k in 1 to m
sum += A[i,k]*B[k,j]
Set Cij = sum
所以两个矩阵相乘的时间复杂度是
答案:在奇异值分解矩阵中Σ里面的奇异值按从大到小的顺序排列,奇异值
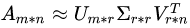
其中r是一个远远小于m和n的数,右边的三个矩阵相乘的结果将会使一个接近A的矩阵。如果r越接近于n,则相乘的结果越接近于A。如果r的取值远远小于n,从计算机内存的角度来说,右边三个矩阵的存储内存要远远小于矩阵A的。所以在奇异值分解中r的取值很重要,就是在计算精度和时间空间之间做选择。
3)SVD计算举例
这里我们用一个简单的矩阵来说明奇异值分解的步骤。我们的矩阵A定义为:
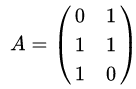




2.3 SVD分解的应用
异值分解的应用有很多,比如:用SVD解PCA、潜在语言索引也依赖于SVD算法。可以说,SVD是矩阵分解、降维、压缩、特征学习的一个基础的工具,所以SVD在机器学习领域相当的重要。
1)降维。
通过奇异值分解的公式,我们可以很容易看出来,原来矩阵A的特征有n维。经过SVD分解后,可以用前r个非零奇异值对应的奇异向量表示矩阵A的主要特征,这样就把矩阵A进行了降维。
2)压缩。
通过奇异值分解的公式,我们可以看出来,矩阵A经过SVD分解后,要表示原来的大矩阵A,我们只需要存储U、Σ、V三个较小的矩阵即可。而这三个较小规模的矩阵占用内存上也是远远小于原有矩阵A的,这样SVD分解就起到了压缩的作用。
Reference:
1.https://blog.csdn.net/u011081315/article/details/76252524
2.https://blog.csdn.net/weixin_37589896/article/details/78423493
3.http://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html
4.https://blog.csdn.net/bitcarmanlee/article/details/52068118
5.http://www.cnblogs.com/pinard/p/6251584.html
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life
给优秀的自己点个赞





