Spark机器学习:矩阵及推荐算法
在社会生产中经常要对生产过程中产生的很多数据进行统计、处理、分析,以此来对生产过程进行了解和监控,保证正常平稳的生产以达到最好的经济收益。但是得到的原始数据往往纷繁复杂,需要用一些方法对数据进行处理,生成直接明了的结果。
在计算中引入矩阵可以对数据进行大量的处理,这种方法比较简单快捷。随着学习的深入,慢慢发现矩阵的应用在数据处理、特征提取、图片处理等方面都有着非常广泛的应用,特别在机器学习领域,比如因子分析、主成分分析、同现矩阵等算法,矩阵的应用也很广泛。
LibRec框架已经实现了矩阵和向量等基础模块,在大数据方面结合Spark框架的全新LibRec分布式矩阵向量基础模块也在研发中,后续迭代版本会陆续提供给大家学习使用。
下一期推文拟介绍近期LibRec项目的工作进展,静请期待~~
学习Spark机器学习框架,我们首先也要熟悉Spark的矩阵向量基础。
Spark矩阵向量
1.Breeze 计算库
import breeze.linalg._
import breeze.numerics._
Breeze函数包括:创建函数、数值计算函数、元素访问及操作函数、数值计算函数、求和函数、布尔函数、线性代数函数、取整函数 、常量函数、复数函数、三角函数、对数和指数函数等。
在Spark中源码引用时经常用缩写如下:DenseMatrix => BDM, CSCMatrix => BSM,DenseVector => BDV, SparseVector => BSV
2.BLAS 线性代数运算库
引用了netlib-java对应的java版本com.github.fommil.netlib:core包。Spark MLlib中采用了BLAS线性代数运算库,其中BLAS按照功能分为三个级别:
向量-向量运算:y <-- ax + y
矩阵-向量运算:y <-- aAx + by
矩阵-矩阵运算:C <-- aAB + bC
3.MLlib向量、矩阵
(1)MLlib向量
MLlib自己实现了Vector类,封装了Breeze向量方法。MLlib Vector包含了toBreeze方法,可以把MLlib Vector转化为Breeze向量。接口org.apache.spark.mllib.linalg.Vector,实现了DensorVector、SparseVector。org.apache.spark.mllib.linalg.Vectors伴生对象实现了具体的向量操作。
(2)MLlib矩阵
MLlib自己实现了Matrix类,封装了Breeze矩阵方法。MLlib Matrix包含了toBreeze方法,可以把MLlib Matrix转化为Breeze矩阵。接口org.apache.spark.mllib.linalg.Matrix,实现了DensorMatrix、SparseMatrix。org.apache.spark.mllib.linalg.Matrixs伴生对象实现了具体的矩阵操作。
4. ML BLAS模块
MLlib自己实现了BLAS类,封装了部分BLAS线性代数方法,在MLlib模块中使用自己的BLAS。
5. MLlib分布式矩阵
MLlib在Vector和Matrix基础上实现了分布式矩阵类,分布式矩阵的数据分块或者分行存储,并且实现了分布式矩阵的基本运算。接口org.apache.spark.mllib.linalg.distributed.DistributedMatrix,分布式矩阵:
RowMatrix(行矩阵)
IndexedRowMatrix(行索引矩阵)
CoordinateMatrix(坐标矩阵)
BlockMatrix(块矩阵)
Spark推荐算法
1. 相似度算法
对用户的行为进行分析得到用户的偏好后,可以根据用户的偏好计算相似用户和物品,然后基于相似用户或物品进行推荐。这就是协同过滤中的两个分支,即基于用户的协同过滤和基于物品的协同过滤。
调用函数在org.apache.spark.mllib.stat.correlation.Correlations类中
corr方法:输入两个RDD[Double]及相似度类型,返回相关系数值
corrMatrix方法:输入RDD[Vector]及相似度类型,返回相关系数矩阵
corr和corrMatrix通过反射的方式调用对应的相似度算法,method默认调用皮尔逊相关系数,其它相似度算法为Spearman相关系数。
2. ALS推荐算法
(1)算法模型
ALS的算法流程:初始化数据集和Spark环境,切分训练集和测试集,训练ALS模型,结果检查,推荐商品。
ALS是alternating least squares的缩写 , 意为交替最小二乘法。该方法常用于基于矩阵分解的推荐系统中。例如:将用户(user)对商品(item)的评分矩阵分解为两个矩阵:一个是用户对商品隐含特征的偏好矩阵,另一个是商品所包含的隐含特征的矩阵。在这个矩阵分解的过程中,评分缺失项得到了填充,也就是说我们可以基于这个填充的评分来给用户最商品推荐了。
ALS 的核心假设是:打分矩阵A是近似低秩的,即一个m∗n的打分矩阵 A 可以用两个小矩阵U(m∗k)和V(n∗k)的乘积来近似:
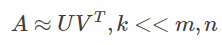
我们把打分理解成相似度,那么“打分矩阵A(m∗n)”就可以由“用户喜好特征矩阵U(m∗k)”和“产品特征矩阵V(n∗k)”的乘积。
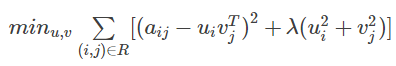
R表示用户和物品集,aij表示用户i对物品j的真实评分,lambda表示正则化系数,lambda后面的表示防止过拟合的正则化项。
(2)源码解析
Spark ALS推荐算法的模型参数:
rank:隐藏因子的个数
iterations:迭代的次数,推荐值 10-20
lambda:惩罚函数的因数,是ALS的正则化参数,推荐值 0.01
implicitPrefs:决定了是用显性反馈ALS的版本还是用适用隐性反馈数据集的版本
alpha:是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准
numBlocks:用于并行化计算的分块个数 (-1为自动分配)
seed:随机种子
ALS推荐算法的模型训练函数:
def train[ID: ClassTag](
ratings: RDD[Rating[ID]],
rank: Int = 10,
numUserBlocks: Int = 10,
numItemBlocks: Int = 10,
maxIter: Int = 10,
regParam: Double = 1.0,
implicitPrefs: Boolean = false,
alpha: Double = 1.0,
nonnegative: Boolean = false,
intermediateRDDStorageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK,
finalRDDStorageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK,
checkpointInterval: Int = 10,
seed: Long = 0L)(
implicit ord: Ordering[ID]): (RDD[(ID, Array[Float])], RDD[(ID, Array[Float])])
(3)算法实例
// 建立模型
val rank = 10
val numIterations = 10
val model = ALS.train(ratings, rank, numIterations, 0.01)
// 对用户1推荐10件商品
model.recommendProducts(1,10).foreach(println(_))
3. 关联规则
关联规则是反映一个事物与其他事物之间的相互依存性和关联性,常用于实体商店或在线电商的推荐系统。通过对顾客的购买记录数据库进行关联规则挖掘,最终目的是发现顾客群体的购买习惯的内在共性,例如购买产品A的同时也连带购买产品B的概率,根据挖掘结果,调整货架的布局陈列、设计促销组合方案,实现销量的提升,最经典的应用案例莫过于<啤酒和尿布>。
(1)源码解析
FPGroup算法类:org.apache.spark.mllib.fpm.FPGrowth,通过new FPGrowth建立FPGrowth频繁项集挖掘类。通过设置模型参数,执行run方法,开始挖掘频繁项集,训练完成后返回FPGrowth模型(FPGrowthModel)。
频繁项集挖掘:
挖掘频繁项函数:private def genFreqItems
挖掘频繁项集函数:private def genFreqItemsets
FPTree类:org.apache.spark.mllib.fpm.FPTree
实现了以下相关算法:
add函数:树增加事物
merge函数:树合并
project函数:取后缀树
getTransactions函数:取节点下的所有事务
extract函数:提取频繁项集
FPGrowthModel类:org.apache.spark.mllib.fpm.FPGrowthModel
频繁项集:freqItemsets
(2)算法实例
// 建立模型
val minSupport = 0.3;//最小支持度
val numPartition = 12; //数据分区
val model = new FPGrowth().
setMinSupport(minSupport).
setNumPartitions(numPartition).
run(data)
// 打印结果
model.freqItemsets.collect().foreach { itemset =>
println(itemset.items + "->" + itemset.freq)
}
猜你喜欢
LibRec 每周算法:FTRL原理与工程实践 (by Google)