Richard Sutton 直言卷积反向传播已经落后,AI 突破要有新思路:持续反向传播
![]()
来源:AI科技评论
本文为约6179字,建议阅读12分钟
本文介
绍了强化学习之父 Richard Sutton 的演讲,并详细解释了持续反向传播算法。

![]()
“可塑性损失”(Loss of Plasticity)是深度神经网络最常被诟病的一个缺点,这也是基于深度学习的 AI 系统被认为无法持续学习的原因之一。
对于人脑而言,“可塑性”是指产生新神经元和神经元之间新连接的能力,是人进行持续学习的重要基础。随着年龄的增长,作为巩固已学到知识的代价,大脑的可塑性会逐渐下降。神经网络也是类似。
一个形象的例子是,2020 年热启动式(warm-starting)训练被证明:只有抛除最初学到的内容,以一次性学习的方式在整个数据集上训练,才会取得比较好的学习效果。
在深度强化学习(DRL)中,AI 系统往往也要“遗忘”神经网络之前所学习的所有内容,只将部分内容保存到回放缓冲区,再从零开始实现不断学习。这种重置网络的方式也被认为证明了深度学习无法持续学习。
那么,如何才能使学习系统保持可塑性?
近日,强化学习之父 Richard Sutton 在 CoLLAs 2022 会议中作了一个题为“Maintaining Plasticity in Deep Continual Learning” 的演讲,提出了他认为能够解决这个问题的答案:持续反向传播算法(Continual Backprop)。
![]()
Richard Sutton 首先从数据集的角度证明了可塑性损失的存在,然后从神经网络内部分析了可塑性损失的原因,最后提出持续反向传播算法作为解决可塑性损失的途径:重新初始化一小部分效用度较低的神经元,这种多样性的持续注入可以无限期地保持深度网络的可塑性。
以下是演讲全文,我们做了不改原意的整理。
01. 可塑性损失的真实存在
深度学习是否能真正解决持续学习的问题?
答案是否定的,主要原因有以下三点:
“无法解决”是指如同非深度的线性网络,学习速度最终会非常缓慢;
深度学习中采用的专业标准化方法只在一次性学习中有效,与持续学习相违背;
回放缓存本身就是承认深度学习不可行的极端方法。
因此,我们必须寻找适用于这种新型学习模式的更优算法,摆脱一次性学习的局限性。
首先,我们利用 ImageNet 和 MNIST 数据集做分类任务,实现回归预测,对持续学习效果进行直接测试,证明了监督学习中可塑性损失的存在。
ImageNet 数据集测试
ImageNet 是一个包含数百万张用名词标记的图像的数据集。它有 1000 个类别,每个类别有700张或更多图像,被广泛用于类别学习和类别预测。
下面是一张鲨鱼照片,通过下采样降到 32*32 大小。这个实验的目的是从深度学习实践中寻找最小的变化。我们将每个类别的 700 张图像划分成 600 个训练样例和 100 个测试样例,然后将 1000 个类别分成两组,生成长度为 500 的二元分类任务序列,所有的数据集会被随机地打乱顺序。每个任务训练结束后,我们在测试样例上评估模型的准确率,独立运行 30 次后取平均,再进入下一个二元分类任务。
![]()
500 个分类任务会共享相同的网络,为了消除复杂性影响,任务切换后会重置头网络。我们采用标准网络,即 3 层卷积 + 3 层全连接,不过对于 ImageNet 数据集来说输出层可能相对小一些,这是由于一个任务只用了两种类别。对于每个任务,每 100 个示例作为一个 batch,共有 12 个 batch,训练 250 个 epoch。在开始第一个任务前只进行一次初始化,利用 Kaiming 分布初始化权重。针对交叉熵损失采用基于动量的随机梯度下降法,同时采用 ReLU 激活函数。
这里引出两个问题:
1、在任务序列中,性能会如何演化?
2、在哪一个任务上的性能会更好?是初始的第一个任务会更好?还是后续任务会从前面任务的经验中获益?
下图给出了答案,持续学习的性能是由训练步长和反向传播综合决定的。
由于是二分类问题,偶然性概率是 50%,阴影区域表示标准差,这种差异并不显著。线性基准采用线性层直接处理像素值,没有深度学习方法效果好,这种差异很显著。
![]()
图注:使用更小的学习率(α=0.001)准确率会更高,在前 5 个任务中性能逐步提升,但从长远来看却呈下降趋势。
我们接着将任务数目增加到了 2000,进一步分析了学习率对于持续学习效果的影响,平均每 50 个任务计算一次准确率。结果如下图。
![]()
图注:α=0.01 的红色曲线在第一个任务上的准确率大约是 89%,一旦任务数超过 50,准确率便下降,随着任务数进一步增加,可塑性逐渐缺失,最终准确率低于线性基准。α=0.001 时,学习速度减慢,可塑性也会急剧降低,准确率只是比线性网络高一点点。
因此,对于良好的超参数,任务间的可塑性会衰减,准确率会比只使用一层神经网络还要低,红色曲线所显示的几乎就是“灾难性的可塑性缺失”。
训练结果同样取决于迭代次数、步长数和网络尺寸等参数,图中每条曲线在多个处理器上的训练时间是 24 小时,在做系统性实验时可能并不实用,我们接下来选择 MNIST 数据集进行测试。
MNIST 数据集测试
MNIST 数据集共包含 60000 张手写数字图像,有 0-9 这 10 个类别,为 28*28 的灰度图像。
Goodfellow 等人曾通过打乱顺序或者随机排列像素创建一种新的测试任务,如右下角的图像就是生成的排列图像的示例,我们采用这种方法来生成整个任务序列,在每个任务中 6000 张图像以随机的形式呈现。这里没有增加任务内容,网络权重只在进行第一个任务之前初始化一次。我们可以用在线的交叉熵损失进行训练,同样继续使用准确率指标衡量持续学习的效果。
![]()
神经网络结构为 4 层全连接层,前 3 层神经元数为 2000,最后一层神经元数为 10。由于 MNIST 数据集的图像居中并进行过缩放,所以可以不执行卷积操作。所有的分类任务共享相同的网络,采用了不含动量的随机梯度下降法,其他的设置与 ImageNet 数据集测试的设置相同。
![]()
图注:中间的图是在任务序列上独立运行 30 次取平均值后的结果,每个任务有 6000 个样本,由于是分类任务,开始时随机猜的准确率是 10%,模型学习到排列图像的规律后,预测准确率会逐渐提升,但切换任务后,准确率又降到 10%,所以总体呈现不断波动趋势。右边的图是模型在每个任务上的学习效果,初始准确率为 0,随着时间推移,效果逐渐变好。在第 10 个任务上的准确率比第 1 个任务好,但在进行第 100 个任务时准确率有所下降,在第 800 个任务上的准确率比第一个还要低。
为了弄清楚整个过程,后续还需要重点分析凸起部分的准确率,对其取均值后得到中间图像的蓝色曲线。可以清晰地看到,准确率刚开始会逐步提升,后面直到第 100 个任务时趋于平稳。那在第 800 个任务时准确率为什么会急剧下降呢?
接下来,我们在更多的任务序列上尝试了不同的步长值,进一步观察它们的学习效果。结果如下图:
![]()
图注:红色曲线采用和前面实验相同的步长值,准确率的确在稳步下降,可塑性损失相对较大。
同时,学习率越大,可塑性减小的速度就越快。所有的步长值都会存在巨大的可塑性损失。此外,隐藏层神经元数目也会影响准确率,棕色曲线的神经元数目为 10000,由于神经网络的拟合能力增强,此时准确率会下降得非常缓慢,仍有可塑性损失,但网络尺寸越小,可塑性减小的速度也越快。
那么从神经网络内部来看,为什么会产生可塑性损失?
下图解释了其中的原因。可以发现,“死亡”神经元数目占比过高、神经元的权重过大以及神经元多样性丧失,都是产生可塑性损失的原因。
![]()
图注:横轴仍然都表示任务编号,第一张图的纵轴表示“死亡”神经元的百分比,“死亡”神经元是指输出和梯度总为 0 的神经元,不再预测网络的可塑性。第二张图的纵轴表示权重大小。第三张图的纵轴表示剩余隐藏神经元数目的有效等级。
02. 现有方法的局限性
我们分析了现有的、反向传播以外的深度学习方法是否会有助于保持可塑性。
![]()
结果表明,L2 正则化方法会使可塑性损失减小,在此过程中令权重缩小到 0,从而可以动态调整并保持可塑性。
收缩和扰动方法与 L2 正则化类似,同时还会向所有权重中加入随机噪声增加多样性,基本不会有可塑性损失。
我们还尝试了其他在线标准化方法,开始时效果还比较好,但随着持续学习可塑性损失严重。Dropout 方法的表现更糟糕,我们随机将一部分神经元设置为0再训练,发现可塑性损失急剧加大。
各种方法对神经网络内部结构也会产生影响。使用正则化方法会使“死亡”神经元数量百分比上升,因为在将权重缩小到 0 的过程中,如果其一直为 0 ,就会导致输出为 0,神经元就会“死亡”。而收缩和扰动向权重中添加了随机噪声,所以不会有太多的“死亡”神经元。标准化方法也有很多的“死亡”神经元,它似乎在朝着错误的方向走,Dropout 也类似。
权值随任务数量变化的结果更为合理,使用正则化会获得很小的权值,收缩和扰动在正则化的基础上添加了噪声,权值下降幅度相对减弱,而标准化则会使权重变大。但是对于 L2 正则化以及收缩和扰动方,其隐藏神经元数有效等级相对较低,说明其在保持多样性方面表现较差,这也是一个问题。
缓慢变化的回归问题(SCR)
我们所有的 idea 和算法都源自缓慢变化的回归问题实验,这是一个聚焦于持续学习的新的理想化问题。
在这个实验中,我们的目的是要实现一个具有随机权重的单层神经网络形成的目标函数,隐藏层神经元为 100 个线性阈值神经元。
我们没有做分类,只是生成了一个数字,因此这是一个回归问题。每训练 10000 步,我们才会从输入的后 15 位中选择 1 位进行翻转,因此这是一个缓慢变化的目标函数。
我们的解决方案是用相同的网络结构,只包含一个神经元的隐藏层,同时保证激活函数可微,但是我们将会有 5 个隐藏神经元。这就类似于在 RL 中,智能体探索的范围比交互的环境小很多,所以只能做近似处理,随着目标函数的变化尝试改变近似值,这样就会容易做一些系统性实验。
![]()
图注:输入为 21 位随机的二进制数,第 1 位是值为 1 的输入常数偏差,中间 5 位是独立同分布的随机数,其他 15 位是缓慢变化的常数,输出为实数。权值随机化为 0,可以随机地选择 +1 或者 -1。
我们进一步研究了变化的步长值和激活函数对学习效果的影响,比如这里用了 tanh、sigmoid 和 relu 激活函数等:
![]()
以及激活函数形式对所有算法学习效果的影响:
![]()
在步长和激活函数同时变化的情况下,我们也对 Adam 反向传播的影响做了系统性分析:
![]()
最后是使用不同激活函数后,基于 Adam 机制的不同算法之间的误差变化情况:
以上实验结果都表明深度学习方法已经不再适用于持续学习,遇到新的问题时,学习过程会变得非常缓慢,没有体现出深度的优势。深度学习中的标准化方法也只适合一次性学习,我们需要改进深度学习方法才有可能将其用于持续学习中。
03. 持续反向传播
卷积反向传播算法本身会是一个好的持续学习算法吗?
我们认为不是。
卷积反向传播算法主要包含两个方面:用小的随机权重进行初始化和在每个时间步进行梯度下降。尽管它在开始生成小的随机数来初始化权重,但并不会再次重复。理想情况下,我们可能需要一些在任何时候都可以进行类似计算的学习算法。
那我们如何使卷积反向传播算法持续地学习?
最简单的方法就是选择性地进行重新初始化,比如在执行几项任务后进行初始化。但同时,重新初始化整个网络在持续学习中可能并不合理,因为这意味着神经网络正在忘记全部所学内容。所以我们最好选择性地初始化神经网络的一部分,比如重新初始化一些“死亡”神经元,或者根据效用度对神经网络进行排序,重新初始化效用度较低的神经元。
随机选择初始化的思想与 2012 年 Mahmood 和 Sutton 提出的生成和测试方法有关,只需要生成一些神经元并测试它们的实用性,持续反向传播算法搭建了这两个概念之间的桥梁。生成和测试方法存在一些局限性,只用一个隐藏层并只有一个输出神经元,我们将其扩展到多层网络,可以用一些深度学习方法进行优化。
我们首先考虑将网络设置成多层,不再是单个输出。之前的工作提到过效用度的概念,由于只有一个权重,这个效用度只是权重层面的概念,但是我们有多个权重,最简单的泛化是考虑权重求和层面的效用度。
另一个想法是考虑特征的活动,而不仅仅是考虑输出权重,因此我们可以将权重的总和乘以平均特征激活函数,从而分配不同的比例。我们希望设计能够持续学习并保持快速运行的算法,我们在计算效用度的时候还考虑了特征的可塑性。最后,将特征的平均贡献转移到输出的偏置中,降低特征删除的影响。
![]()
未来的改进方向主要有两点:(1)我们需要对效用度进行全局度量,衡量神经元对所表征的整个函数的影响,而不仅仅局限于输入权重、输出权重和激活函数这样的局部度量;(2)我们需要进一步改进生成器,目前只是从初始分布中采样进行进行初始化,还要探索可以改善性能的初始化方法。
那么,持续反向传播在保持可塑性方面表现如何呢?
实验结果表明,持续反向传播利用在线排列的 MNIST 数据集训练,完全保持了可塑性。下图中的蓝色曲线显示了这一结果。
![]()
图注:右图显示了不同替换率对于持续学习的影响,例如替换率为 1e-6 表示在每个时间步长替换 1/1000000 个表征。即假设有 2000 个特征,每走 500 步,就会在每一层更换一个神经元。这个更新速度非常缓慢,所以替换率对超参数不是很敏感,不会显著影响学习效果。
接下来,我们需要研究持续反向传播对于神经网络内部结构的影响。持续反向传播几乎没有“死亡”神经元,因为效用度考虑了平均特征激活,如果某个神经元“死亡”,会立即被更换。而且由于我们不断更换神经元,我们得到了权重幅度较小的新神经元。因为随机初始化了神经元,它们也相应地保留了更丰富的表征和多样性。
![]()
因此,持续反向传播解决了 MNIST 数据集上可塑性缺失引发的全部问题。
那么,持续反向传播是否可以扩展到更深的卷积神经网络中?
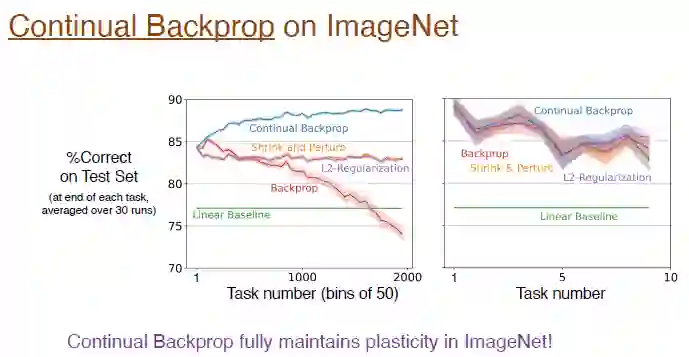
答案是肯定的!在 ImageNet 数据集上,持续反向传播完全保持了可塑性,模型最终的准确率在 89% 左右。其实在初始的训练阶段,这几种算法的表现相当,前面提到过替换率的变化非常缓慢,任务数目足够大的时候才近似的比较好。
![]()
这里以“Slippery Ant”问题为例展示一个强化学习的实验结果。
“Slippery Ant”问题是非平稳强化问题的一个扩展,与 PyBullet 环境基本类似,唯一不同的是地面和智能体之间的摩擦力每 1000 万步后会发生变化。我们基于持续反向传播实现了持续学习版本的 PPO 算法,可以选择性初始化。PPO 算法和持续 PPO 算法的对比结果如下图。
![]()
图注:PPO 算法在刚开始表现还不错,但随着训练进行性能不断下降,引入 L2 算法以及收缩和扰动算法后会有所缓解。而持续 PPO 算法的表现相对较好,保留了大部分可塑性。
有趣的是,PPO 算法训练的智能体只能挣扎着走路,但是持续 PPO 算法训练的智能体可以跑到很远的地方。
04. 结论
深度学习网络主要为一次性学习进行优化,从某种意义上说用于持续学习可能会完全失败。像标准化和 DropOut 等深度学习方法对于持续学习可能没有帮助,但是在此基础上做一些小的改进可能会非常有效,比如持续反向传播。
持续反向传播根据神经元的效用对网络特征进行排序,特别是对于递归神经网络,排序方式可能有更多改进方法。
强化学习算法利用了策略迭代思想,持续学习问题固然存在,保持深度学习网络的可塑性为 RL 和基于模型的 RL 开辟了巨大的新可能性。
原视频链接:
https://www.youtube.com/watch?v=p_zknyfV9fY&t=11s

“可塑性损失”(Loss of Plasticity)是深度神经网络最常被诟病的一个缺点,这也是基于深度学习的 AI 系统被认为无法持续学习的原因之一。
对于人脑而言,“可塑性”是指产生新神经元和神经元之间新连接的能力,是人进行持续学习的重要基础。随着年龄的增长,作为巩固已学到知识的代价,大脑的可塑性会逐渐下降。神经网络也是类似。
一个形象的例子是,2020 年热启动式(warm-starting)训练被证明:只有抛除最初学到的内容,以一次性学习的方式在整个数据集上训练,才会取得比较好的学习效果。
在深度强化学习(DRL)中,AI 系统往往也要“遗忘”神经网络之前所学习的所有内容,只将部分内容保存到回放缓冲区,再从零开始实现不断学习。这种重置网络的方式也被认为证明了深度学习无法持续学习。
那么,如何才能使学习系统保持可塑性?
近日,强化学习之父 Richard Sutton 在 CoLLAs 2022 会议中作了一个题为“Maintaining Plasticity in Deep Continual Learning” 的演讲,提出了他认为能够解决这个问题的答案:持续反向传播算法(Continual Backprop)。

Richard Sutton 首先从数据集的角度证明了可塑性损失的存在,然后从神经网络内部分析了可塑性损失的原因,最后提出持续反向传播算法作为解决可塑性损失的途径:重新初始化一小部分效用度较低的神经元,这种多样性的持续注入可以无限期地保持深度网络的可塑性。
以下是演讲全文,我们做了不改原意的整理。
01. 可塑性损失的真实存在
深度学习是否能真正解决持续学习的问题?
答案是否定的,主要原因有以下三点:
“无法解决”是指如同非深度的线性网络,学习速度最终会非常缓慢;
深度学习中采用的专业标准化方法只在一次性学习中有效,与持续学习相违背;
回放缓存本身就是承认深度学习不可行的极端方法。
因此,我们必须寻找适用于这种新型学习模式的更优算法,摆脱一次性学习的局限性。
首先,我们利用 ImageNet 和 MNIST 数据集做分类任务,实现回归预测,对持续学习效果进行直接测试,证明了监督学习中可塑性损失的存在。
ImageNet 数据集测试
ImageNet 是一个包含数百万张用名词标记的图像的数据集。它有 1000 个类别,每个类别有700张或更多图像,被广泛用于类别学习和类别预测。
下面是一张鲨鱼照片,通过下采样降到 32*32 大小。这个实验的目的是从深度学习实践中寻找最小的变化。我们将每个类别的 700 张图像划分成 600 个训练样例和 100 个测试样例,然后将 1000 个类别分成两组,生成长度为 500 的二元分类任务序列,所有的数据集会被随机地打乱顺序。每个任务训练结束后,我们在测试样例上评估模型的准确率,独立运行 30 次后取平均,再进入下一个二元分类任务。

500 个分类任务会共享相同的网络,为了消除复杂性影响,任务切换后会重置头网络。我们采用标准网络,即 3 层卷积 + 3 层全连接,不过对于 ImageNet 数据集来说输出层可能相对小一些,这是由于一个任务只用了两种类别。对于每个任务,每 100 个示例作为一个 batch,共有 12 个 batch,训练 250 个 epoch。在开始第一个任务前只进行一次初始化,利用 Kaiming 分布初始化权重。针对交叉熵损失采用基于动量的随机梯度下降法,同时采用 ReLU 激活函数。
这里引出两个问题:
1、在任务序列中,性能会如何演化?
2、在哪一个任务上的性能会更好?是初始的第一个任务会更好?还是后续任务会从前面任务的经验中获益?
下图给出了答案,持续学习的性能是由训练步长和反向传播综合决定的。
由于是二分类问题,偶然性概率是 50%,阴影区域表示标准差,这种差异并不显著。线性基准采用线性层直接处理像素值,没有深度学习方法效果好,这种差异很显著。
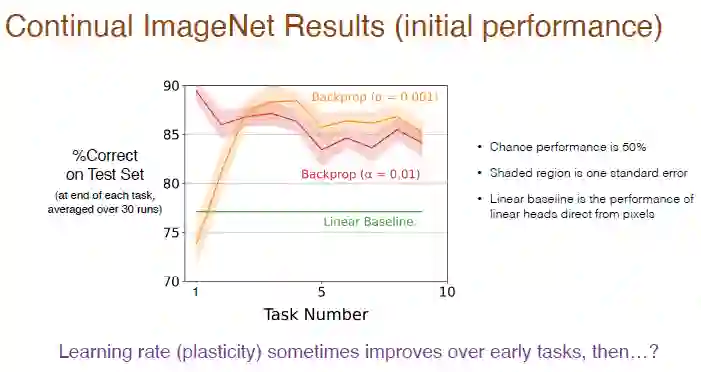
我们接着将任务数目增加到了 2000,进一步分析了学习率对于持续学习效果的影响,平均每 50 个任务计算一次准确率。结果如下图。
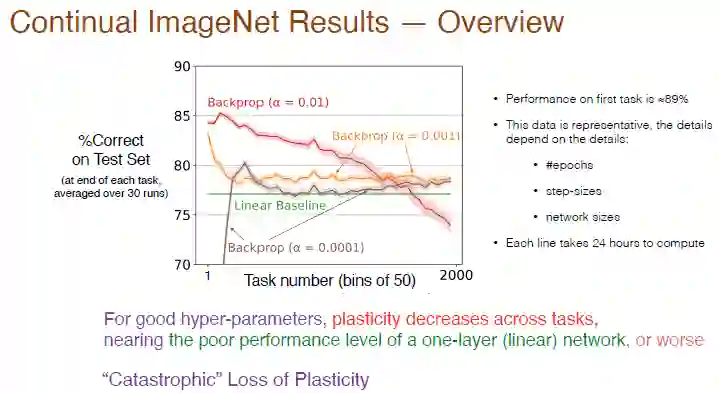
图注:α=0.01 的红色曲线在第一个任务上的准确率大约是 89%,一旦任务数超过 50,准确率便下降,随着任务数进一步增加,可塑性逐渐缺失,最终准确率低于线性基准。α=0.001 时,学习速度减慢,可塑性也会急剧降低,准确率只是比线性网络高一点点。
因此,对于良好的超参数,任务间的可塑性会衰减,准确率会比只使用一层神经网络还要低,红色曲线所显示的几乎就是“灾难性的可塑性缺失”。
训练结果同样取决于迭代次数、步长数和网络尺寸等参数,图中每条曲线在多个处理器上的训练时间是 24 小时,在做系统性实验时可能并不实用,我们接下来选择 MNIST 数据集进行测试。
MNIST 数据集测试
MNIST 数据集共包含 60000 张手写数字图像,有 0-9 这 10 个类别,为 28*28 的灰度图像。
Goodfellow 等人曾通过打乱顺序或者随机排列像素创建一种新的测试任务,如右下角的图像就是生成的排列图像的示例,我们采用这种方法来生成整个任务序列,在每个任务中 6000 张图像以随机的形式呈现。这里没有增加任务内容,网络权重只在进行第一个任务之前初始化一次。我们可以用在线的交叉熵损失进行训练,同样继续使用准确率指标衡量持续学习的效果。

神经网络结构为 4 层全连接层,前 3 层神经元数为 2000,最后一层神经元数为 10。由于 MNIST 数据集的图像居中并进行过缩放,所以可以不执行卷积操作。所有的分类任务共享相同的网络,采用了不含动量的随机梯度下降法,其他的设置与 ImageNet 数据集测试的设置相同。
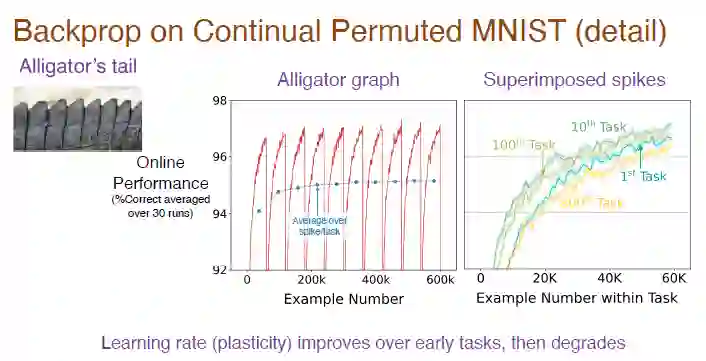
图注:中间的图是在任务序列上独立运行 30 次取平均值后的结果,每个任务有 6000 个样本,由于是分类任务,开始时随机猜的准确率是 10%,模型学习到排列图像的规律后,预测准确率会逐渐提升,但切换任务后,准确率又降到 10%,所以总体呈现不断波动趋势。右边的图是模型在每个任务上的学习效果,初始准确率为 0,随着时间推移,效果逐渐变好。在第 10 个任务上的准确率比第 1 个任务好,但在进行第 100 个任务时准确率有所下降,在第 800 个任务上的准确率比第一个还要低。
为了弄清楚整个过程,后续还需要重点分析凸起部分的准确率,对其取均值后得到中间图像的蓝色曲线。可以清晰地看到,准确率刚开始会逐步提升,后面直到第 100 个任务时趋于平稳。那在第 800 个任务时准确率为什么会急剧下降呢?
接下来,我们在更多的任务序列上尝试了不同的步长值,进一步观察它们的学习效果。结果如下图:
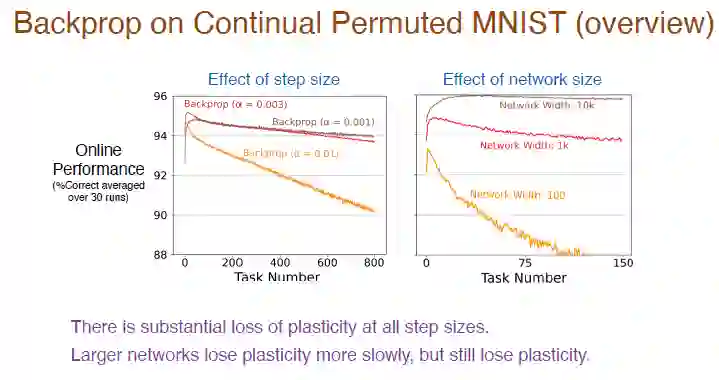
图注:红色曲线采用和前面实验相同的步长值,准确率的确在稳步下降,可塑性损失相对较大。
同时,学习率越大,可塑性减小的速度就越快。所有的步长值都会存在巨大的可塑性损失。此外,隐藏层神经元数目也会影响准确率,棕色曲线的神经元数目为 10000,由于神经网络的拟合能力增强,此时准确率会下降得非常缓慢,仍有可塑性损失,但网络尺寸越小,可塑性减小的速度也越快。
那么从神经网络内部来看,为什么会产生可塑性损失?
下图解释了其中的原因。可以发现,“死亡”神经元数目占比过高、神经元的权重过大以及神经元多样性丧失,都是产生可塑性损失的原因。
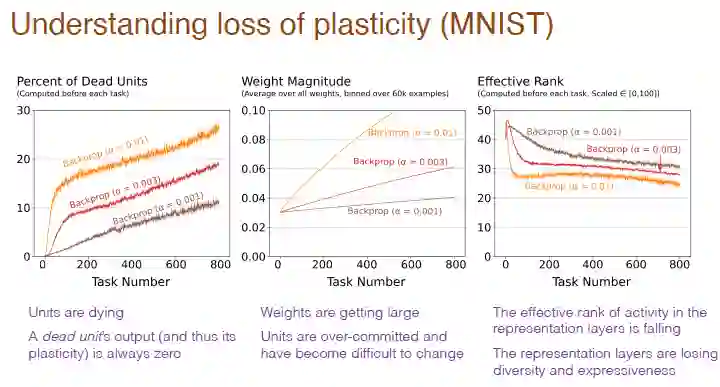
图注:横轴仍然都表示任务编号,第一张图的纵轴表示“死亡”神经元的百分比,“死亡”神经元是指输出和梯度总为 0 的神经元,不再预测网络的可塑性。第二张图的纵轴表示权重大小。第三张图的纵轴表示剩余隐藏神经元数目的有效等级。
02. 现有方法的局限性
我们分析了现有的、反向传播以外的深度学习方法是否会有助于保持可塑性。
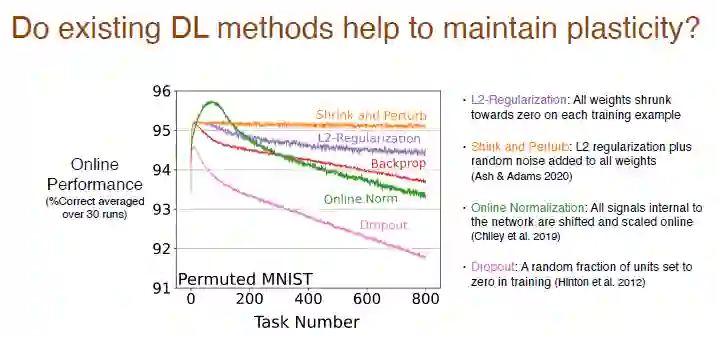
结果表明,L2 正则化方法会使可塑性损失减小,在此过程中令权重缩小到 0,从而可以动态调整并保持可塑性。
收缩和扰动方法与 L2 正则化类似,同时还会向所有权重中加入随机噪声增加多样性,基本不会有可塑性损失。
我们还尝试了其他在线标准化方法,开始时效果还比较好,但随着持续学习可塑性损失严重。Dropout 方法的表现更糟糕,我们随机将一部分神经元设置为0再训练,发现可塑性损失急剧加大。
各种方法对神经网络内部结构也会产生影响。使用正则化方法会使“死亡”神经元数量百分比上升,因为在将权重缩小到 0 的过程中,如果其一直为 0 ,就会导致输出为 0,神经元就会“死亡”。而收缩和扰动向权重中添加了随机噪声,所以不会有太多的“死亡”神经元。标准化方法也有很多的“死亡”神经元,它似乎在朝着错误的方向走,Dropout 也类似。
权值随任务数量变化的结果更为合理,使用正则化会获得很小的权值,收缩和扰动在正则化的基础上添加了噪声,权值下降幅度相对减弱,而标准化则会使权重变大。但是对于 L2 正则化以及收缩和扰动方,其隐藏神经元数有效等级相对较低,说明其在保持多样性方面表现较差,这也是一个问题。
缓慢变化的回归问题(SCR)
我们所有的 idea 和算法都源自缓慢变化的回归问题实验,这是一个聚焦于持续学习的新的理想化问题。
在这个实验中,我们的目的是要实现一个具有随机权重的单层神经网络形成的目标函数,隐藏层神经元为 100 个线性阈值神经元。
我们没有做分类,只是生成了一个数字,因此这是一个回归问题。每训练 10000 步,我们才会从输入的后 15 位中选择 1 位进行翻转,因此这是一个缓慢变化的目标函数。
我们的解决方案是用相同的网络结构,只包含一个神经元的隐藏层,同时保证激活函数可微,但是我们将会有 5 个隐藏神经元。这就类似于在 RL 中,智能体探索的范围比交互的环境小很多,所以只能做近似处理,随着目标函数的变化尝试改变近似值,这样就会容易做一些系统性实验。
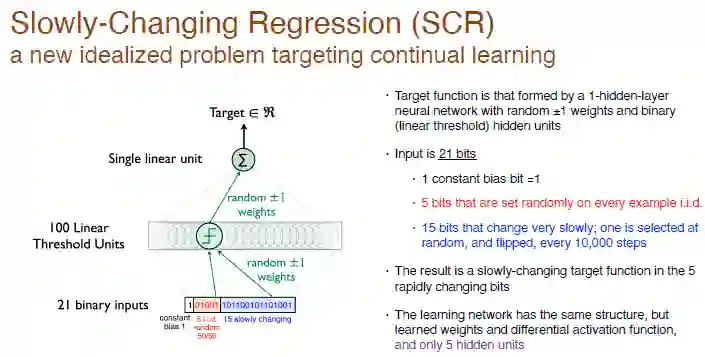
图注:输入为 21 位随机的二进制数,第 1 位是值为 1 的输入常数偏差,中间 5 位是独立同分布的随机数,其他 15 位是缓慢变化的常数,输出为实数。权值随机化为 0,可以随机地选择 +1 或者 -1。
我们进一步研究了变化的步长值和激活函数对学习效果的影响,比如这里用了 tanh、sigmoid 和 relu 激活函数等:
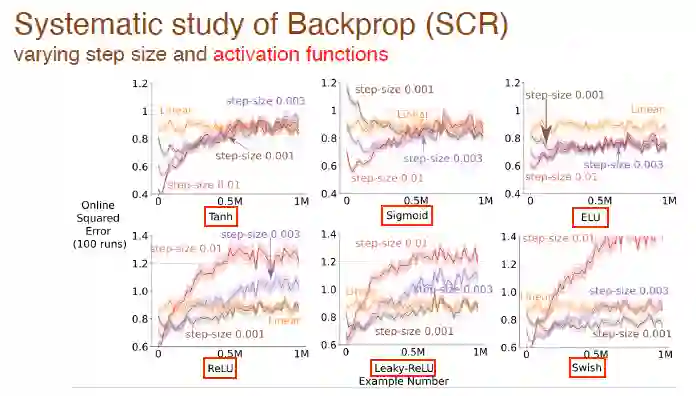
以及激活函数形式对所有算法学习效果的影响:
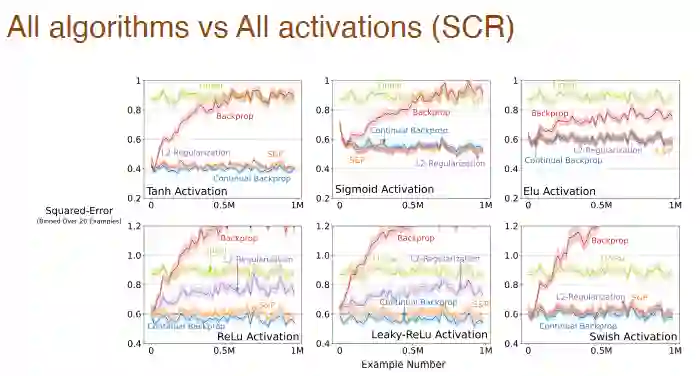
在步长和激活函数同时变化的情况下,我们也对 Adam 反向传播的影响做了系统性分析:
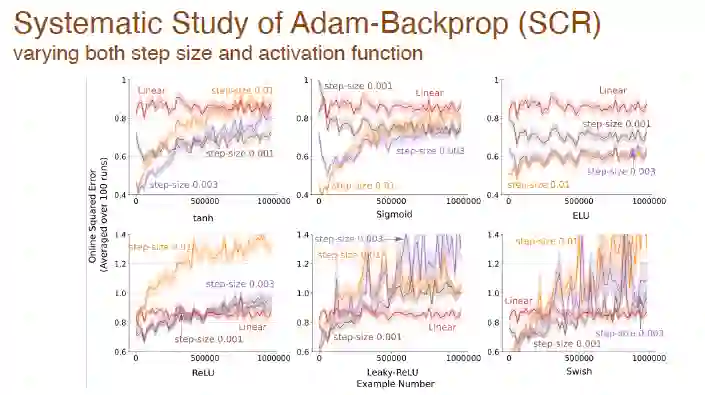
最后是使用不同激活函数后,基于 Adam 机制的不同算法之间的误差变化情况:
以上实验结果都表明深度学习方法已经不再适用于持续学习,遇到新的问题时,学习过程会变得非常缓慢,没有体现出深度的优势。深度学习中的标准化方法也只适合一次性学习,我们需要改进深度学习方法才有可能将其用于持续学习中。
03. 持续反向传播
卷积反向传播算法本身会是一个好的持续学习算法吗?
我们认为不是。
卷积反向传播算法主要包含两个方面:用小的随机权重进行初始化和在每个时间步进行梯度下降。尽管它在开始生成小的随机数来初始化权重,但并不会再次重复。理想情况下,我们可能需要一些在任何时候都可以进行类似计算的学习算法。
那我们如何使卷积反向传播算法持续地学习?
最简单的方法就是选择性地进行重新初始化,比如在执行几项任务后进行初始化。但同时,重新初始化整个网络在持续学习中可能并不合理,因为这意味着神经网络正在忘记全部所学内容。所以我们最好选择性地初始化神经网络的一部分,比如重新初始化一些“死亡”神经元,或者根据效用度对神经网络进行排序,重新初始化效用度较低的神经元。
随机选择初始化的思想与 2012 年 Mahmood 和 Sutton 提出的生成和测试方法有关,只需要生成一些神经元并测试它们的实用性,持续反向传播算法搭建了这两个概念之间的桥梁。生成和测试方法存在一些局限性,只用一个隐藏层并只有一个输出神经元,我们将其扩展到多层网络,可以用一些深度学习方法进行优化。
我们首先考虑将网络设置成多层,不再是单个输出。之前的工作提到过效用度的概念,由于只有一个权重,这个效用度只是权重层面的概念,但是我们有多个权重,最简单的泛化是考虑权重求和层面的效用度。
另一个想法是考虑特征的活动,而不仅仅是考虑输出权重,因此我们可以将权重的总和乘以平均特征激活函数,从而分配不同的比例。我们希望设计能够持续学习并保持快速运行的算法,我们在计算效用度的时候还考虑了特征的可塑性。最后,将特征的平均贡献转移到输出的偏置中,降低特征删除的影响。
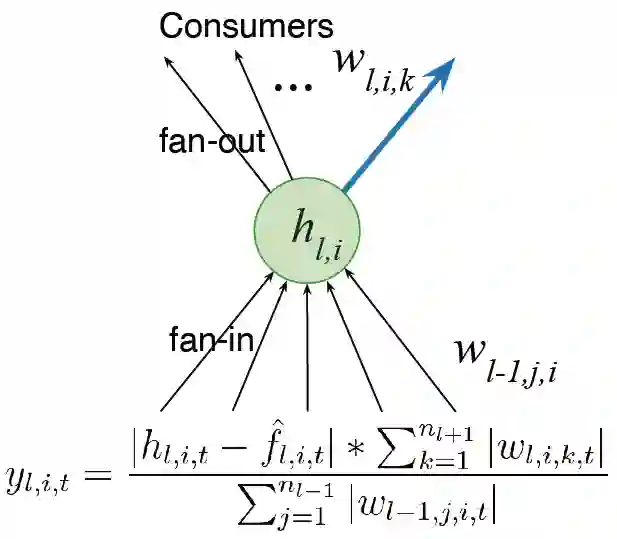
未来的改进方向主要有两点:(1)我们需要对效用度进行全局度量,衡量神经元对所表征的整个函数的影响,而不仅仅局限于输入权重、输出权重和激活函数这样的局部度量;(2)我们需要进一步改进生成器,目前只是从初始分布中采样进行进行初始化,还要探索可以改善性能的初始化方法。
那么,持续反向传播在保持可塑性方面表现如何呢?
实验结果表明,持续反向传播利用在线排列的 MNIST 数据集训练,完全保持了可塑性。下图中的蓝色曲线显示了这一结果。
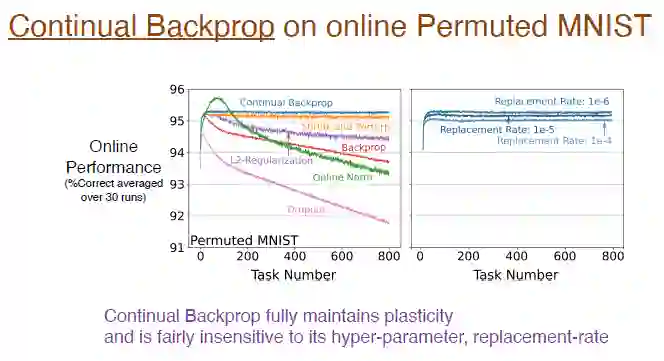
图注:右图显示了不同替换率对于持续学习的影响,例如替换率为 1e-6 表示在每个时间步长替换 1/1000000 个表征。即假设有 2000 个特征,每走 500 步,就会在每一层更换一个神经元。这个更新速度非常缓慢,所以替换率对超参数不是很敏感,不会显著影响学习效果。
接下来,我们需要研究持续反向传播对于神经网络内部结构的影响。持续反向传播几乎没有“死亡”神经元,因为效用度考虑了平均特征激活,如果某个神经元“死亡”,会立即被更换。而且由于我们不断更换神经元,我们得到了权重幅度较小的新神经元。因为随机初始化了神经元,它们也相应地保留了更丰富的表征和多样性。
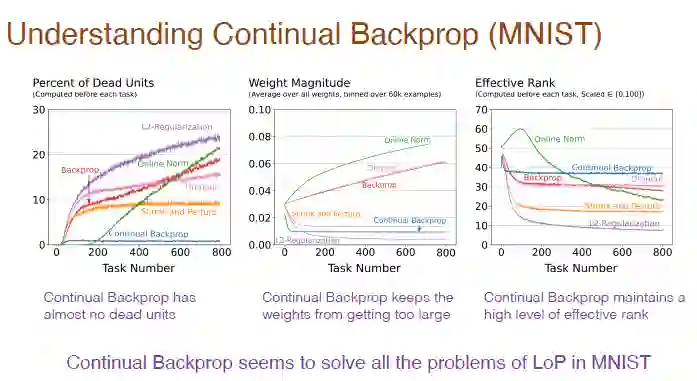
因此,持续反向传播解决了 MNIST 数据集上可塑性缺失引发的全部问题。
那么,持续反向传播是否可以扩展到更深的卷积神经网络中?
答案是肯定的!在 ImageNet 数据集上,持续反向传播完全保持了可塑性,模型最终的准确率在 89% 左右。其实在初始的训练阶段,这几种算法的表现相当,前面提到过替换率的变化非常缓慢,任务数目足够大的时候才近似的比较好。
这里以“Slippery Ant”问题为例展示一个强化学习的实验结果。
“Slippery Ant”问题是非平稳强化问题的一个扩展,与 PyBullet 环境基本类似,唯一不同的是地面和智能体之间的摩擦力每 1000 万步后会发生变化。我们基于持续反向传播实现了持续学习版本的 PPO 算法,可以选择性初始化。PPO 算法和持续 PPO 算法的对比结果如下图。
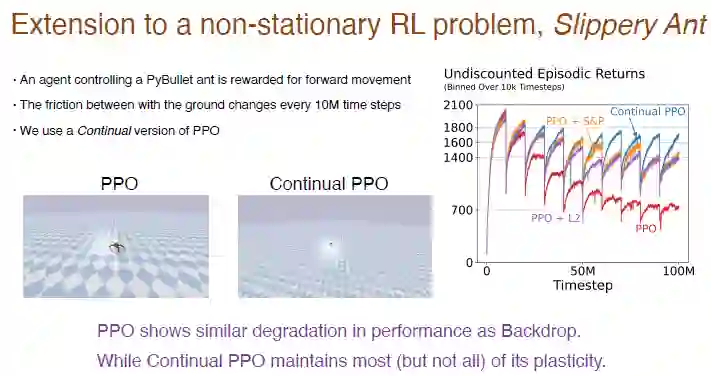
图注:PPO 算法在刚开始表现还不错,但随着训练进行性能不断下降,引入 L2 算法以及收缩和扰动算法后会有所缓解。而持续 PPO 算法的表现相对较好,保留了大部分可塑性。
有趣的是,PPO 算法训练的智能体只能挣扎着走路,但是持续 PPO 算法训练的智能体可以跑到很远的地方。
04. 结论
深度学习网络主要为一次性学习进行优化,从某种意义上说用于持续学习可能会完全失败。像标准化和 DropOut 等深度学习方法对于持续学习可能没有帮助,但是在此基础上做一些小的改进可能会非常有效,比如持续反向传播。
持续反向传播根据神经元的效用对网络特征进行排序,特别是对于递归神经网络,排序方式可能有更多改进方法。
强化学习算法利用了策略迭代思想,持续学习问题固然存在,保持深度学习网络的可塑性为 RL 和基于模型的 RL 开辟了巨大的新可能性。
原视频链接:
https://www.youtube.com/watch?v=p_zknyfV9fY&t=11s



