资源 | Facebook开源DrQA的PyTorch实现:基于维基百科的问答系统
选自GitHub
机器之心编译
参与:Panda
今年 4 月,斯坦福大学和 Facebook 人工智能研究所在 arXiv 发布了一个基于维基百科的开放域问题问答系统 DrQA。近日,Facebook 在 GitHub 上开源了这个系统的代码,FAIR 主管 Yann LeCun 在社交网络也为这次开源做了宣传。据悉,该研究也将出现在 7 月 30 日举行的 ACL 2017 大会上。
论文地址:https://arxiv.org/abs/1704.00051
开源地址:https://github.com/facebookresearch/DrQA
Yann LeCun 的推荐语:
DrQA 是一个开放域的问答系统。向 DrQA 系统输入一段文本,然后提一个答案能在该文本中找到的问题,那么 DrQA 就能给出这个问题的答案。代码相关的论文将在 ACL 发表。向该团队致敬:FAIR 研究工程师 Adam Fisch、斯坦福博士实习生 Danqi Chen 和 FAIR 科学家 Jason Weston 和 Antoine Bordes。
大规模机器阅读
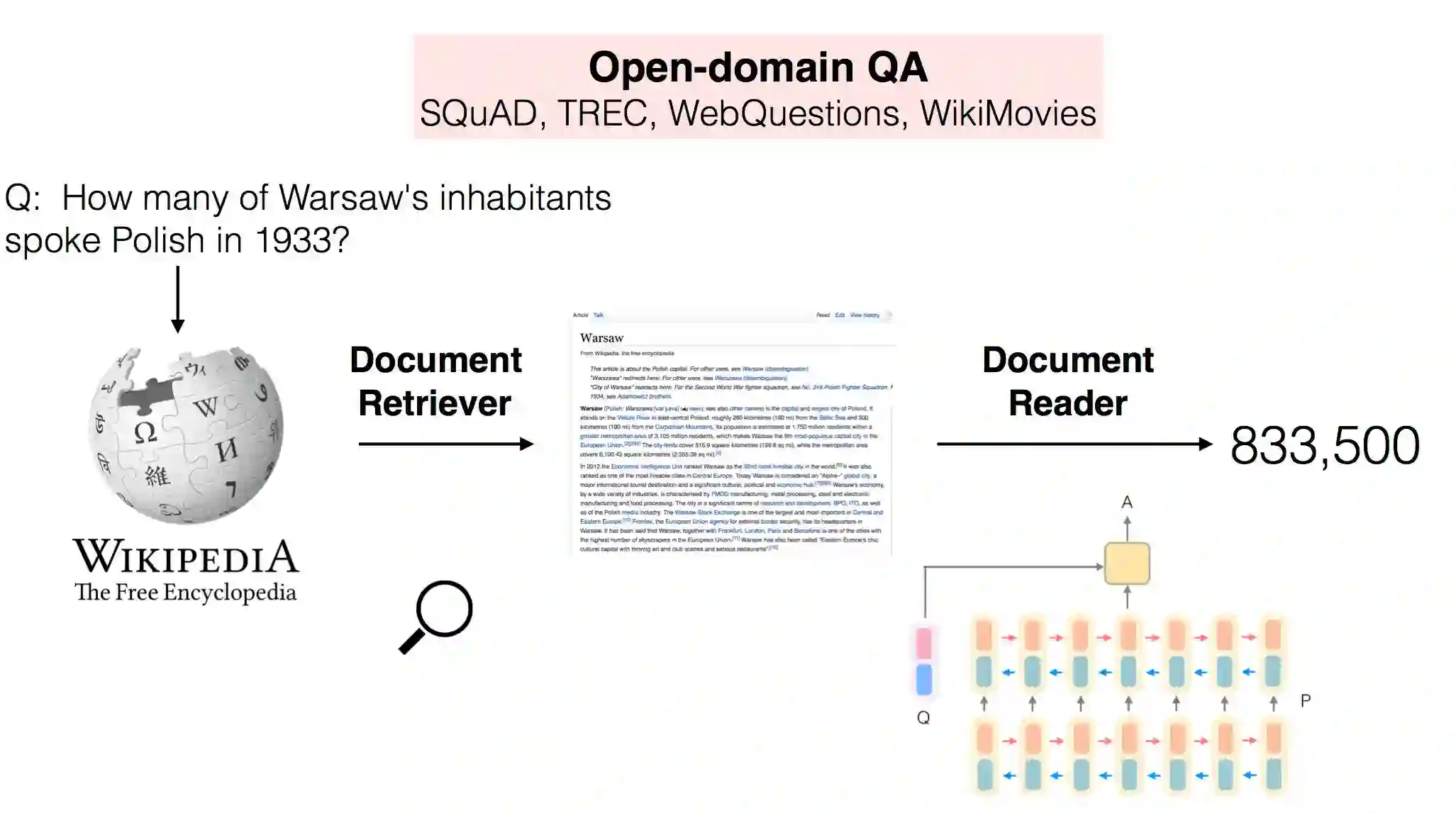
DrQA 是一个用于开放域问答的阅读理解系统。DrQA 特别针对的是被称为「大规模机器阅读(MRS:machine reading at scale)」的任务。在这种设置中,我们要在可能非常大的非结构化文档语料库(可能并不冗余)中搜索问题的答案。因此这个系统必然要将文档检索难题(寻找相关文档)与文本的机器理解(在这些文档中确定答案的范围)结合到一起。
我们使用 DrQA 的实验专注于回答事实性问题,同时仅使用维基百科作为文档的唯一知识源。维基百科是一个非常合适的大规模、丰富和详细的信息源。为了回答一个问题,系统必须首先检索超过 500 万篇文章中的少数几篇可能相关的文章,然后再仔细地扫描它们以确认答案。
注意,DrQA 将维基百科看作是文章的一般集合,而并不依赖其内部的图结构。因此 DrQA 可以直接被用于任何文档的集合,正如在文档检索器(Document Retriever)的 README 中描述的那样。
这个 repo 包含了代码、数据和用于处理和查询维基百科的预训练的模型,该模型如论文中描述的一样,参阅后文「训练后的模型与数据」一节。我们也列出了几种用于评估的不同数据集,参见后文「问答数据集」一节。注意这项工作是在原始代码基础上的重构版本,也更加有效。再生数(reproduction numbers)非常相似,但并不完全一样。
快速上手:演示
安装 DrQA 并下载我们的模型,然后开始问开放域问题吧!
运行 python scripts/pipeline/interactive.py 可进入交互式的会话。对于每一个问题,会返回其上面涉及的范围和其来源的维基百科段落。
>>> process('What is question answering?')
Top Predictions:
+------+----------------------------------------------------------------------------------------------------------+--------------------+--------------+-----------+
| Rank | Answer | Doc | Answer Score | Doc Score |
+------+----------------------------------------------------------------------------------------------------------+--------------------+--------------+-----------+
| 1 | a computer science discipline within the fields of information retrieval and natural language processing | Question answering | 1917.8 | 327.89 |
+------+----------------------------------------------------------------------------------------------------------+--------------------+--------------+-----------+
Contexts:
[ Doc = Question answering ]
Question Answering (QA) is a computer science discipline within the fields of
information retrieval and natural language processing (NLP), which isconcerned with building systems that automatically answer questions posed by
humans in a natural language.>>> process('What is the answer to life, the universe, and everything?')
Top Predictions:
+------+--------+---------------------------------------------------+--------------+-----------+
| Rank | Answer | Doc | Answer Score | Doc Score |
+------+--------+---------------------------------------------------+--------------+-----------+
| 1 | 42 | Phrases from The Hitchhiker's Guide to the Galaxy | 47242 | 141.26 | +------+--------+---------------------------------------------------+--------------+-----------+ Contexts: [ Doc = Phrases from The Hitchhiker's Guide to the Galaxy ]
The number 42 and the phrase, "Life, the universe, and everything" have
attained cult status on the Internet. "Life, the universe, and everything" isa common name for the off-topic section of an Internet forum and the phrase isinvoked in similar ways to mean "anything at all". Many chatbots, when asked
about the meaning of life, will answer "42". Several online calculators are
also programmed with the Question. Google Calculator will give the result to"the answer to life the universe and everything" as 42, as will Wolfram's Computational Knowledge Engine. Similarly, DuckDuckGo also gives the result of "the answer to the ultimate question of life, the universe and everything" as 42. In the online community Second Life, there is a section on a sim called 43. "42nd Life." It is devoted to this concept in the book series, and several attempts at recreating Milliways, the Restaurant at the End of the Universe, were made.>>> process('Who was the winning pitcher in the 1956 World Series?')
Top Predictions:
+------+------------+------------------+--------------+-----------+
| Rank | Answer | Doc | Answer Score | Doc Score |
+------+------------+------------------+--------------+-----------+
| 1 | Don Larsen | New York Yankees | 4.5059e+06 | 278.06 |
+------+------------+------------------+--------------+-----------+
Contexts:
[ Doc = New York Yankees ]
In 1954, the Yankees won over 100 games, but the Indians took the pennant withan AL record 111 wins; 1954 was famously referred to as "The Year the Yankees Lost the Pennant". In , the Dodgers finally beat the Yankees in the World
Series, after five previous Series losses to them, but the Yankees came back
strong the next year. On October 8, 1956, in Game Five of the 1956 World
Series against the Dodgers, pitcher Don Larsen threw the only perfect game inWorld Series history, which remains the only perfect game in postseason playand was the only no-hitter of any kind to be pitched in postseason play until
Roy Halladay pitched a no-hitter on October 6, 2010.你自己试试看吧!当然,DrQA 可能会提供其它的事实,所以请享受这段旅程吧。
安装 DrQA
DrQA 的设置很简单!
DrQA 需要 Python 3.5 或更高版本,也需要安装 PyTorch。它的其它依赖要求可参阅 requirements.txt 文件。
运行以下命令克隆这个库并安装 DrQA:
git clone https://github.com/facebookresearch/DrQA.git
cd DrQA; pip install -r requirements.txt; python setup.py develop注:requirements.txt 包含所有可能所需的软件包的一个子集。根据你要运行的内容,你可能需要安装其它软件包(比如 spaCy)。
如果你要使用 CoreNLPTokenizer 或 SpacyTokenizer,你还需要分别下载 Stanford CoreNLP jar 包和 spaCy en 模型。如果你使用 Stanford CoreNLP,让 jar 位于你的 Java CLASSPATH 环境变量中,或使用以下代码通过编程方式设置路径:
import drqa.tokenizers
drqa.tokenizer.set_default('corenlp_classpath', '/your/corenlp/classpath/*')重要:默认的 tokenizer 是 CoreNLP,所以你需要在 CLASSPATH 里面有它,以运行 README 示例。
比如:export CLASSPATH=$CLASSPATH:/path/to/corenlp/download/*
为了方便,如果没有给定模型参数,Document Reader、Retriever 和 Pipeline 模块将会尝试加载默认模型。参阅下面内容下载这些模型。
训练后的模型与数据
要下载我们提供的所有用于维基百科问答的训练后的模型和数据,请运行:
./download.sh警告:这会下载一个 7.5GB 的 tar 压缩包(解压后 25GB),需要一些时间。
这会将数据存储在各种模块的默认值指定的文件路径中的 data/ 中。通过将 DRQA_DATA 环境变量指定到其它地方,可以修改这个顶级目录。
默认目录结构(参见嵌入部分了解更多有关用于训练的额外下载的信息):
DrQA
├── data (or $DRQA_DATA)
├── datasets
│ ├── SQuAD-v1.1-<train/dev>.<txt/json>
│ ├── WebQuestions-<train/test>.txt
│ ├── freebase-entities.txt
│ ├── CuratedTrec-<train/test>.txt
│ └── WikiMovies-<train/test/entities>.txt
├── reader
│ ├── multitask.mdl
│ └── single.mdl
└── wikipedia
├── docs.db
└── docs-tfidf-ngram=2-hash=16777216-tokenizer=simple.npz不同模块的默认模型路径也可以通过下面的代码进行修改,比如:
import drqa.reader
drqa.reader.set_default('model', '/path/to/model')
reader = drqa.reader.Predictor() # Default model loaded for prediction文档检索器(Document Retriever)
使用维基百科(unigram 和 bigram、2^24 bin,简单 tokenization)的 TF-IDF 模型在多个数据集(这是测试集,开发集是 SQuAD)上的评估结果:

链接:https://s3.amazonaws.com/fair-data/drqa/docs-tfidf-ngram%3D2-hash%3D16777216-tokenizer%3Dsimple.npz.gz
这里 P@5 是指答案部分出现在前 5 个文档中的问题的百分比。
文档阅读器(Document Reader)
仅在 SQuAD 上训练的模型,在 SQuAD 背景中的评估结果:

链接:https://s3.amazonaws.com/fair-data/drqa/single.mdl
使用远程监督(distant supervision)在没有 NER/POS/lemma 功能的情况下训练的模型,在完全维基百科环境中的多个数据集(这是测试集,开发集是 SQuAD)上的评估结果:

链接:https://s3.amazonaws.com/fair-data/drqa/multitask.mdl
维基百科
我们的完全规模实验是在 2016 年 12 月 21 日转存的英语版维基百科上执行的。这个转存数据使用 WikiExtractor(https://github.com/attardi/wikiextractor)进行了处理,并为内部消岐、列表、索引和大纲页面(通常仅包含链接的页面)进行了过滤。我们将这些文档存储成了一个 sqlite 数据库,其中 drqa.retriever.DocDB 提供了一个接口。
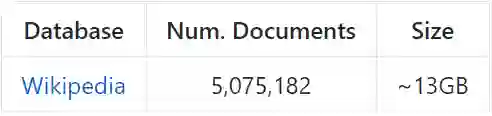
链接:https://s3.amazonaws.com/fair-data/drqa/docs.db.gz
问答数据集
用于 DrQA 训练和评估的数据集可以在这里找到:
SQuAD
训练:https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json
开发:https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json
WebQuestions
训练:http://nlp.stanford.edu/static/software/sempre/release-emnlp2013/lib/data/webquestions/dataset_11/webquestions.examples.train.json.bz2
测试:http://nlp.stanford.edu/static/software/sempre/release-emnlp2013/lib/data/webquestions/dataset_11/webquestions.examples.test.json.bz2
实体:https://s3.amazonaws.com/fair-data/drqa/freebase-entities.txt.gz
WikiMovies:训练/测试/实体:https://s3.amazonaws.com/fair-data/drqa/WikiMovies.tar.gz(这是从 https://research.fb.com/downloads/babi/ 以预期格式重新托管的)
CuratedTrec:训练/测试:https://s3.amazonaws.com/fair-data/drqa/CuratedTrec.tar.gz(这是从 https://github.com/brmson/dataset-factoid-curated 以预期格式重新托管的)
格式 A
retriever/eval.py、pipeline/eval.py 和 distant/generate.py 需要数据集是 .txt 文件,且其中每一行都是 JSON 格式编码的问答对,比如:
'{"question": "q1", "answer": ["a11", ..., "a1i"]}'...'{"question": "qN", "answer": ["aN1", ..., "aNi"]}'将 SQuAD 和 WebQuestions 转换成这种格式的脚本包含在 scripts/convert,这是在 download.sh 中自动完成的。
格式 B
reader 目录脚本需要数据集是 .json 文件,其中数据像 SQuAD 一样排布:
file.json
├── "data"│ └── [i]
│ ├── "paragraphs"│ │ └── [j]
│ │ ├── "context": "paragraph text"│ │ └── "qas"│ │ └── [k]
│ │ ├── "answers"│ │ │ └── [l]
│ │ │ ├── "answer_start": N
│ │ │ └── "text": "answer"│ │ ├── "id": "<uuid>"│ │ └── "question": "paragraph question?"│ └── "title": "document id"└── "version": 1.1实体列表
一些数据集有(可能很大的)可选答案列表。比如,WikiMovies 的答案是 OMDb 实体,而 WebQuestions 则基于 Freebase。如果我们已经知道了候选项,我们可以通过丢弃不在这个列表中的任何更高得分范围来强行使所有预测的答案必须在这个列表中。
DrQA 组件
文档检索器
DrQA 并未绑定任何特定类型的检索系统——只要其能有效地缩小搜索空间并重点关注相关文档即可。
按照经典的问答系统的做法,我们纳入了一个基于稀疏的、TF-IDF 加权的词袋向量的有效文档检索系统(非机器学习)。我们使用了 bags of hashed n-grams(这里是 unigrams 和 bigrams)。
要了解如何在新文档上构建你自己的模型,参阅检索器的 README:https://github.com/facebookresearch/DrQA/blob/master/scripts/retriever/README.md。
要交互式地查询维基百科:
python scripts/retriever/interactive.py --model /path/to/model如果 model 被忽略,就会使用我们的默认模型(假设已经下载了)。
为了评估该检索器在一个数据集上的准确度(前 5 个的匹配率):
python scripts/retriever/eval.py /path/to/format/A/dataset.txt --model /path/to/model文档阅读器
DrQA 的文档阅读器是一个多层循环神经网络机器理解模型,被训练用来执行提取式的问答。也就是说,该模型会使用一个返回的文档中的一段文本来作为问题的答案。
该文档阅读器的灵感来自于 SQuAD 数据集,并且也主要是在这个数据集上训练的。它也可以在类似于 SQuAD 的任务上单独使用,其中可以通过问题、包含在上下文中的答案来提供一个特定的语境。
要了解如何在 SQuAD 上训练该文档阅读器,参阅阅读器的 README:https://github.com/facebookresearch/DrQA/blob/master/scripts/reader/README.md
要使用训练后的模型交互式地询问关于文本的问题:
python scripts/reader/interactive.py --model /path/to/model同样,这里的 model 是可选的;如果忽略就会使用默认的模型。
要在数据集上执行模型预测:
python scripts/reader/predict.py /path/to/format/B/dataset.json --model /path/to/modelDrQA 流程
整个系统在 drqa.pipeline.DrQA 中链接到一起。
要使用完整的 DrQA 交互式地提问:
python scripts/pipeline/interactive.py可选参数:
--reader-model Path to trained Document Reader model.
--retriever-model Path to Document Retriever model (tfidf).
--doc-db Path to Document DB.
--tokenizers String option specifying tokenizer type to use (e.g. 'corenlp').
--candidate-file List of candidates to restrict predictions to, one candidate per line.
--no-cuda Use CPU only.
--gpu Specify GPU device id to use.要在数据集上运行预测:
python scripts/pipeline/predict.py /path/to/format/A/dataset.txt可选参数:
--out-dir Directory to write prediction file to (<dataset>-<model>-pipeline.preds).
--reader-model Path to trained Document Reader model.
--retriever-model Path to Document Retriever model (tfidf).
--doc-db Path to Document DB.
--embedding-file Expand dictionary to use all pretrained embeddings in this file (e.g. all glove vectors to minimize UNKs at test time).
--candidate-file List of candidates to restrict predictions to, one candidate per line.
--n-docs Number of docs to retrieve per query.
--top-n Number of predictions to make per query.
--tokenizer String option specifying tokenizer type to use (e.g. 'corenlp').
--no-cuda Use CPU only.
--gpu Specify GPU device id to use.
--parallel Use data parallel (split across GPU devices).
--num-workers Number of CPU processes (for tokenizing, etc).
--batch-size Document paragraph batching size (Reduce in case of GPU OOM).
--predict-batch-size Question batching size (Reduce in case of CPU OOM).远程监督(DS:Distant Supervision)
当提供了来自额外数据集的远程监督数据时,完全配置的 DrQA 的表现会显著提升。给定问答对但不提供支持语境,我们可以使用字符串匹配启发式方法来自动将段落与这些训练样本关联起来。
Question: What U.S. state’s motto is “Live free or Die”?
Answer: New Hampshire
DS Document: Live Free or Die “Live Free or Die” is the official motto of the U.S. state of New Hampshire, adopted by the state in 1945. It is possibly the best-known of all state mottos, partly because it conveys an assertive independence historically found in American political philosophy and partly because of its contrast to the milder sentiments found in other state mottos.
scripts/distant 目录包含用于生成和检查这种远程监督数据的代码。
tokenizer
为了方便,我们提供了一些不同的 tokenizer 选项。在依赖包需求、运行开销、速度和性能上,每一个选项都有自己的优势和劣势。对于我们报告的实验,我们使用了 CoreNLP(但结果都是相似的)。
可用的 tokenizer:
CoreNLPTokenizer:使用 Stanford CoreNLP(选项:corenlp),我们使用了 v3.7.0,需要 Java 8
SpacyTokenizer:使用 spaCy(选项:spacy)
RegexpTokenizer:基于自定义正则表达式的 PTB 风格的 tokenizer(选项:regexp)
SimpleTokenizer:基本的字母-数字/非空的 tokenizer(选项:simple)
查阅字符串选项名和 tokenizer 类别的对应列表:https://github.com/facebookresearch/DrQA/blob/master/drqa/tokenizers/__init__.py
引用
如果你在你的工作中使用 DrQA,请引用这篇 ACL 论文:
@inproceedings{chen2017reading,
title={Reading {Wikipedia} to Answer Open-Domain Questions},
author={Chen, Danqi and Fisch, Adam and Weston, Jason and Bordes, Antoine},
booktitle={Association for Computational Linguistics (ACL)},
year={2017}
}
与 ParlAI 连接
这个 DrQA 文档阅读器实现与 ParlAI 中的文档阅读器有紧密关联。但是这里的研究得到的扩展,以便能在开放域环境中与文档检索器进行交互。即使当 ParlAI API 的限制解除时(比如在预处理和回答范围等方面),它也或多或少在训练上更高效,而且能实现稍微更好的表现。
我们也计划将这个模型整合到 ParlAI 接口中,以便其阅读器可以使用 ParlAI 进行可交替的训练或在许多数据集上多任务执行。有关 ParlAI 的更多信息,可参阅机器之心文章《资源 | Facebook 开源人工智能框架 ParlAI:可轻松训练评估对话模型》。
证书
DrQA 使用 CC-BY-NC 证书。
论文:阅读维基百科以回答开放域问题(Reading Wikipedia to Answer Open-Domain Questions)

论文链接:https://arxiv.org/abs/1704.00051
本论文提出可使用维基百科作为唯一知识源来解决开放域问答问题(open-domain question answering):任何事实性问题的答案都是一篇维基百科文章里面的一段文本。这种大规模机器阅读任务将文档检索难题(寻找相关文章)与文本的机器理解(在这些文章中确定答案的范围)。我们的方法结合了基于二元语法哈希(bigram hashing)和 TF-IDF 匹配的搜索组件与一个训练用于检测维基百科段落中答案的多层循环神经网络。我们在多个已有问答数据集上的实验表明:(1) 这两个模块与当前的竞争者相比都有很高的竞争力,(2) 在它们的组合上使用远程监督(distant supervision)的多任务学习是在这种高难度任务上的有效完备系统。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



