技术动态 | 揭开知识库问答 KB-QA 的面纱 9 · 非结构化知识源篇
作者,四川大学博士生,刘大一恒。本文已经获得 ChatbotMagazine 公众号授权。
内容速览
☛ 非结构化的知识库——维基百科
☛ 思路与模型(文档检索与文档理解;段落encoding、问题encoding与答案预测)
☛ 实验与总结
如果你想寻找一个问题的答案,比如谢霆锋的出生年月,那么你可能会先去查看关于谢霆锋的百度百科 或者 维基百科,找到和出生年月相关的那一行信息,再提取答案。那么,我们能不能让机器也这样去回答问题呢?在我们前面讲到的文章中,我们都使用了结构化的知识库来回答问题,今天我们将介绍一种使用非结构化的知识库——维基百科作为知识源来进行KB-QA。

我们以斯坦福和Facebook AI Research17年较新的这篇文章Reading Wikipedia to Answer Open-Domain Questions为例,进行介绍。
非结构化的知识库——维基百科
相比更适合机器去理解的结构化知识库,维基百科的非结构化知识更适合人们去阅读,而这样的非结构化知识往往比结构化知识库更加的丰富和巨大,使用非结构化知识进行KB-QA具有更强大的泛化性。
给定一个问题,我们可以在维基百科中找到相关信息和答案,如下表所示:
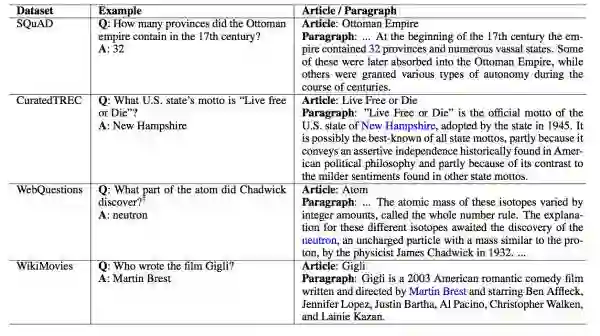
可以看出,对于问题我们可以在维基百科中找到相应的文章,根据文章找到与答案相关的段落,然后提取出答案。
思路与模型
我们的思路其实很简单,分为两个步骤:第一步根据问题检索出维基百科中的相关文章(Document Retriever),第二步在文章中找到相应的段落并提取出答案(Document Reader),第二步的过程其实和NLP中的阅读理解问题很相似,我们可以借鉴其中的技术来完成。整个流程如下图所示:

Document Retriever
通过问题检索出相关的文章有很多的方法,最简单的方法就是统计两者的TF-IDF得到词袋模型向量,然后通过cosine similarity等相似度度量方式进行检索。进一步可以将相邻词汇也考虑进去,使用n-gram的词袋模型。这篇文章中,作者使用bigram的词袋模型,为了加快效率,将bigram映射为murmur3 hash。
对于问题,我们通过Document Retriever检索出最相关的五篇文章。
Document Reader
接下来,我们使用NLP 阅读理解问题中的一些方法来得出答案。对于每篇文章的每个段落,我们去预测一个文本区间作为答案的概率,具体来说,我们根据问题去预测该自然段答案的起始位置(start position)和终止位置(end position)。依次对每篇文章的每个段落进行预测,选出概率最大的区间作为最终答案。
首先我们对每个段落进行encoding,我们将段落中的每一个token用一个特征向量表示,该特征向量包含以下四个部分:
1.词向量(Word-embbedings):300维度预训练好的词向量,由于问题中有些词语比较特殊,如疑问词,因此我们在训练中,对word-embedding中前1000的高频词进行fine-tune,其他词的word-embedding固定使用预训练的值,不再进行训练。
2.抽取匹配(Exact Match):我们用三个二元的指示器来表示该token是否在问题中出现,三个二元指示器分别表示该token的不同形式的表达(如大小写)。
3.符号的特征(Token Features):我们也将该符号的词性标注、命名实体和归一化后的TF作为3个特征加入到特征向量中。
4.引入对问题的注意力机制(Aligned question embedding):该特征和特征2抽取匹配类似,都是为了表征该token和问题的关联度,与特征2不同的是,该特征考虑了整个问题与它的相似度,而非某一个具体的单词,是一种soft-alignment。具体来说,将问题每个单词的embedding和该token通过点乘比较相似度得到加权系数,再对问题每个单词的embedding进行加权求和作为该特征,公式如下:
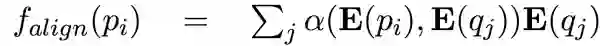
其中p代表段落中的token,q代表问题中的token,E表示embedding,alpha是二者点乘后的归一化相似度,即:
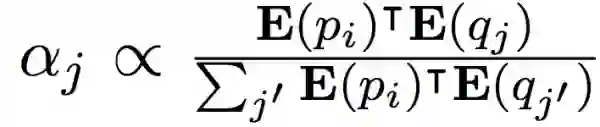
这样我们就将段落中的每一个token进行了向量化,接下来我们使用一个3层的双向LSTM对段落进行encoding,假设双向LSTM每一层隐层为h,我们将所有隐层连接起来,这样对于每个token就得到了一个6h大小的向量表达
接下来我们对问题进行encoding,使用另外一个3层的双向LSTM对问题的word-embedding进行编码,将每时刻的隐层进行加权求和,该归一化加权系数由训练得到,学习了问题中每个单词的重要程度,这样我们就得到了一个问题的向量表达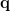
得到了问题和段落的编码,我们就可以进行答案区间的预测了,我们对于段落的每一个位置i,都用两个双线性项去分别预测它作为答案起始位置和终止位置的概率,公式如下:

我们在该段落中去寻找一个区间最有可能是答案的区间[i,i'],即满足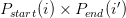
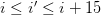
实验与总结
作者使用2016-12-21版的英语版维基百科作为知识源,通过对每一页进行文本提取和结构化元素的删除(section、list、figure、index)等预处理,最终得到了5,075,182篇文章,含9,008,962种token。
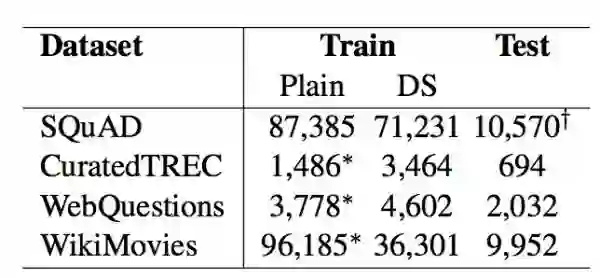
关于答案问题对,作者使用了三个数据集QA的数据集:CuratedTREC、WebQuestion和WikiMovies,作者也加入了阅读理解问题的数据集SQuAD,以上数据集的规模如下表所示:
与SQuAD数据集不同,其他三个QA数据集只有答案问题对,没有标注对应的维基百科文章和段落,因此作者使用以下方法去生成标签:
对于每个问题,检索出最相关的5篇文章,将不包含问题答案的段落,以及长度不满足区间25-1500的段落去掉,如果问题中带有命名实体,则也将不包含该命名实体的段落删除。对于剩下的段落,我们对包含答案的位置进行评分,评分的标准是问题和该段落位置20 token的window中一元和二元的重叠程度,选取重叠程度最高的作为远程监督学习的label。
对于document retriever的性能,作者在四个数据集上进行了测试,测试能够在最相关的5个文章中找到答案的概率,并与Wikipedia Search Engine进行比较,结果如下:

可以看出作者提出的document retriever在该问题上性能要优于Wikipedia Search Engine。
对于document reader,作者使用h=128的3层双向LSTM,0.3的dropout以及Adamax作为优化器进行训练,并比较了 1)只在SQuAD上训练,和2)先在SQuAD上预训练,再单独在三个QA数据集上进行远程监督训练fine-tune(+Fine-tune)以及3)在四个数据集上进行多任务训练的 测试结果——Top-1 exact-match 正确率,如下表所示:

可以看出,经过多任务训练之后的模型,效果会更好一些。
作者也用document reader在SQuAD上进行阅读理解任务的性能测试,与上面测试不同的是,上面是通过检索维基百科中的文章进行回答,而该测试是直接给定相关的段落,作者与其他的state-of-art方法进行了比较,效果如下:

可以看出,作者提出的这个document reader模型,在阅读理解领域效果也很不错。我们注意到,在这里作者也分析了token的四种feature对实验的影响,结果如下表:

可以看出aligned和exact_match这两个feature对性能影响较大。
总的来说,该文章提出来了一个将阅读理解技术应用到KB-QA的思路,使得我们不仅仅可以使用结构化的知识库作为知识源回答问题,也能使用非结构化的知识源通过阅读理解技术来帮助我们得到答案。
- End -
往期 KB-QA 系列文章如下:
ChatbotMagazine 是智言科技(深圳)有限公司旗下的一个技术分享栏目,智言科技是一家专注于基于知识图谱问答系统研发的 AI 公司。欢迎扫描二维码关注 ChatbotMagazine 公众号。

OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客



