ACL 2018 | 神经语言模型如何利用上下文信息:长距离上下文的词序并不重要
选自arXiv
作者:Urvashi Khandelwal等
机器之心编译
参与:Geek AI、刘晓坤
本研究旨在回答「神经语言模型如何利用上下文信息」的问题。通过控制变量法,斯坦福的研究者实验探究了神经语言模型使用的上下文信息量、近距离和远距离的上下文的表征差异,以及复制机制对模型使用上下文的作用这三个议题。
语言模型是诸如机器翻译和总结等自然语言生成任务中的一个重要组成部分。这些任务会利用上下文(词序列)信息估计待预测单词的概率分布。近年来,一系列神经语言模型(NLM)(Graves, 2013; Jozefowicz et al., 2016; Grave et al., 2017a; Dauphin et al., 2017; Melis et al., 2018; Yang et al., 2018)都已经取得了超过经典的 n-gram 模型的性能,这一提升往往归功于它们在距离较远的上下文中对长距离依赖进行建模的能力。然而,目前仍然缺乏对「这些神经语言模型如何利用上下文信息」这一问题的解释。
最近的研究已经开始转向解释由长短期记忆(LSTM)网络编码的信息。它们可以记住句子的长度、词性以及词序(Adi et al., 2017),能够捕获一些像「主谓一致」(Linzen et al., 2016)这样的句法结构,还可以对某些特定的诸如「否定」和「强调」(Li et al., 2016)这样的语义组合进行建模。
然而,之前对 LSTM 的研究都停留在句子层面上,尽管这样做确实可能对更长的上下文进行编码。本文的目标是对前人的工作进行补充,提供一个对上下文的作用更加丰富的理解。具体而言,本研究对比句子更长的上下文文本进行编码。本文的工作旨在回答以下 3 个问题:(1)就单词个数而言,神经语言模型使用了多少上下文信息?(2)在这个范围内,近距离和远距离的上下文是否有不同的表征?(3)复制机制如何帮助模型使用上下文的不同区域?
本文通过对标准的 LSTM 语言模型(Merity et al., 2018)进行控制变量来研究这些问题,使用两个语言模型数据集(Penn Treebank 和 WikiText-2)作为对比基准。给定一个预训练好的语言模型,在测试时以多种方式扰动先验的上下文,探究经过扰动之后的信息对于模型的性能有多大的影响。具体而言,研究者通过改变上下文的长度来学习有多少单词被使用,通过重新排列单词去测试 LSTM 的性能是否与局部和全局的上下文都有关系,通过删除和替换目标单词测试带/不带外部复制机制(例如,Grave 等人在 2017 年提出的神经缓存(neural cache))的 LSTM 的复制能力。这种缓存首先记录历史数据中出现的目标单词和它们的上下文表征,接着在当前的上下文表征与该单词存储在缓存中的上下文向量相匹配时,会鼓励模型复制一个过去的单词。
通过实验,本研究发现: LSTM 平均能够利用大约 200 个单词的上下文,并且在更改超参数的设置时没有显著的改变。在这个上下文的范围内,词序仅仅与 20 个最邻近的单词或者大约一个句子长度的单词相关。在长距离上下文中,词序对性能几乎没有影响,这表明模型保存了远距离单词的高层次的、有模糊语义的表征。最后,本研究发现 LSTM 能够重新生成邻近的上下文中的一些单词,但是这高度依赖于缓存帮助它们从长距离上下文中复制单词。
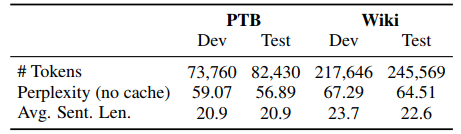
表 1:数据集的统计信息以及与本研究实验相关的性能。
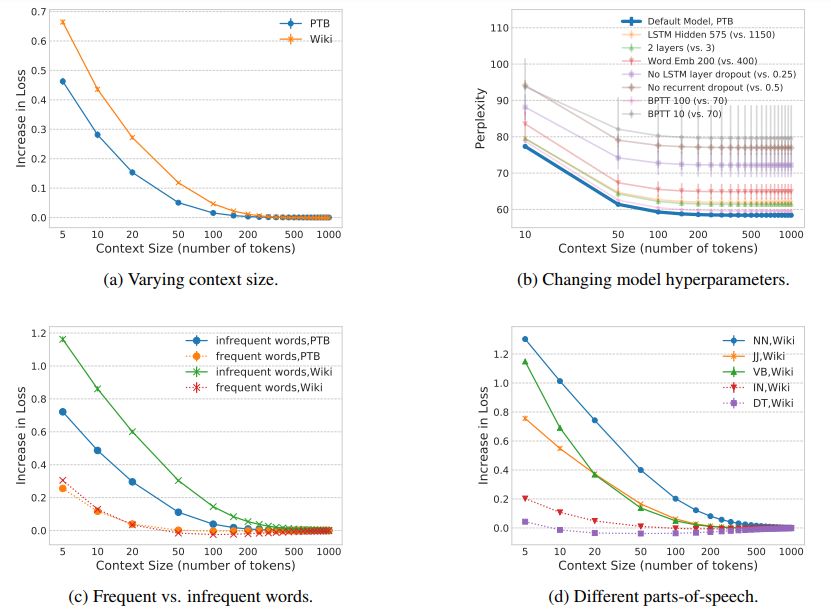
图 1:改变上下文中包含的单词数的影响,与在相同的模型上使用无限制的上下文进行对比。损失的增长表示由于上下文限制,损失在整个语料库上的负对数似然的绝对增长。所有的曲线都是由三个随机种子生成的实验结果的平均,误差条表示标准差。(a)模型在 PTB 数据集上的有效上下文的大小为 150 个单词,在 Wiki 数据集上的有效上下文的大小为 250 个单词。(b)改变模型的超参数不会改变模型对上下文使用的趋势,但是确实会影响模型性能。本文展示了这种误差,强调这种一致的使用趋势。(c)非频繁出现的单词需要比频繁出现的单词更多的上下文。(d)实词比功能词需要更多的上下文。
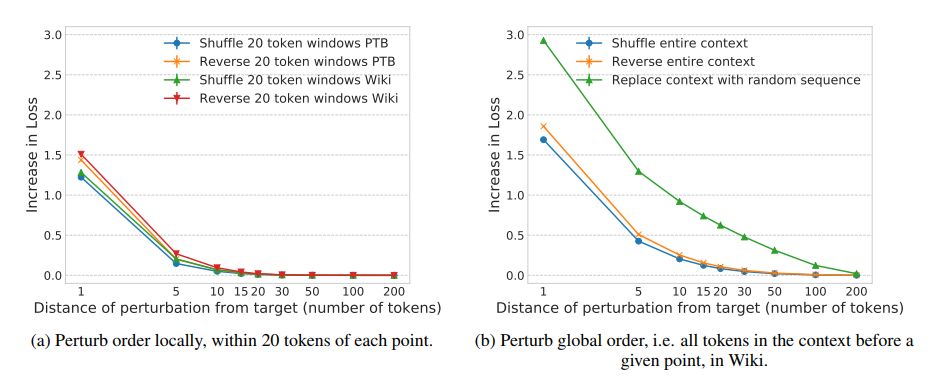
图 2:与未扰动的基线相比,在由 300 个单词组成的上下文中,对单词的顺序进行调整和颠倒单词顺序的影响。所有的曲线都是由三个随机种子生成的平均值,其中误差条表示标准差。(a)在与目标单词相距超过 20 个单词的上下文中,如果在一个由 20 个单词组成的窗口中改变词序,对损失的影响可以忽略不计。(b)在与目标单词相距超过 50 个单词的上下文中,改变全局的词序对损失没有影响。
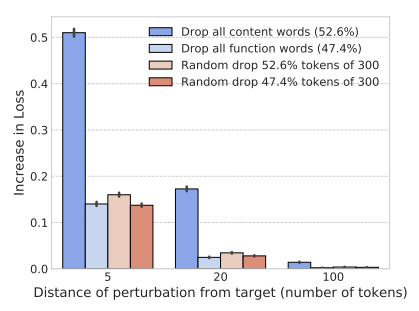
图 3:在 PTB 数据集上,将实词和功能词从上下文的 300 个单词中删除的影响,并与基线进行对比。误差条表示 95% 的置信区间。删除距离目标单词 5 个单词的上下文中的实词和功能词会导致很大的损失提升,而当上下文与目标单词距离超过 20 个单词时,只有实词与性能的改变有关。
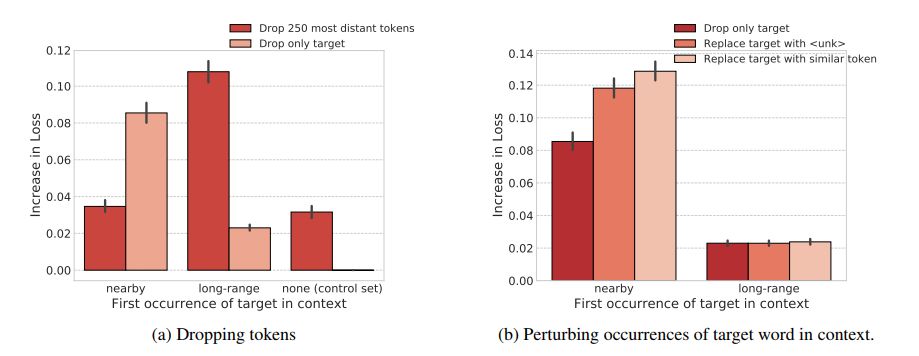
图 4:在 PTB 数据集上,对上下文中的目标词进行扰动的影响与完全删除长距离上下文的影响的对比。误差条表示 95% 的置信区间。(a)只能从长距离上下文中复制的单词对于删除所有长距离单词比对于删除目标单词更加敏感。对那些可以从邻近的上下文中复制的单词来说,只删除目标单词对于损失的影响比删除所有的长距离上下文的影响大得多。(b)对于可以从邻近的上下文中复制的单词来说,使用词汇表中的其它单词替换目标单词,比将其从上下文中删除更损害模型性能。而这对于只能从远距离上下文中复制的单词没有影响。
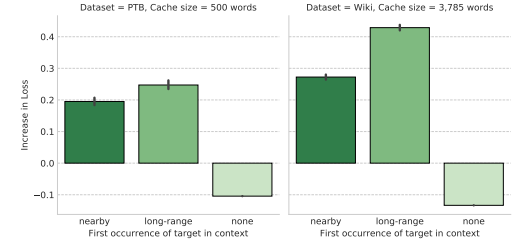
图 7:使用神经记忆缓存的模型性能。误差条表示 95% 的置信区间。使用缓存仅仅从长距离上下文中复制单词对性能提升贡献最大。
论文:Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use Context

论文地址:https://arxiv.org/abs/1805.04623
摘要:我们对神经语言模型(LM)如何利用先验的语言上下文知之甚少。本文通过控制变量研究探讨了上下文在 LSTM 语言模型中的作用。具体而言,本文分析了当先验的上下文中的单词被调序、替换或删除时模型困惑度的增加。在两个标准的数据集(Penn Treebank 和 WikiText-2)上,我们发现模型能够平均利用大约 200 个单词组成的上下文,但是能明显地将近邻的上下文(最近的 50 个单词)和过去的长距离上下文区分开来。模型对最近邻的句子中的词序变化十分敏感,但是长距离上下文(超过 50 个单词)的词序变化可以忽略不计,这说明长距离上下文中过去的单词仅仅被建模为一个模糊的语义场或主题。我们进一步发现神经缓存模型(Grave et al., 2017b)特别地有助于 LSTM 从这种长距离上下文中复制单词。综上所述,本文的分析提供了一个对「语言模型如何利用它们的上下文」这一问题的更好理解,也启发了基于缓存的模型在近期取得成功的原因解释。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



