来自图宾根大学等机构的研究者进行了首个深入研究基于表格数据的深度学习方法的工作,为该领域内的研究者和从业者提供了一份宝贵的指南。
异构表格数据是最常用的数据形式,对于众多关键和计算要求高的应用程序至关重要。深度神经网络在同构数据集上往往性能优异,然而涉及建模表格数据(推理或生成)方面的应用仍然极具挑战性。
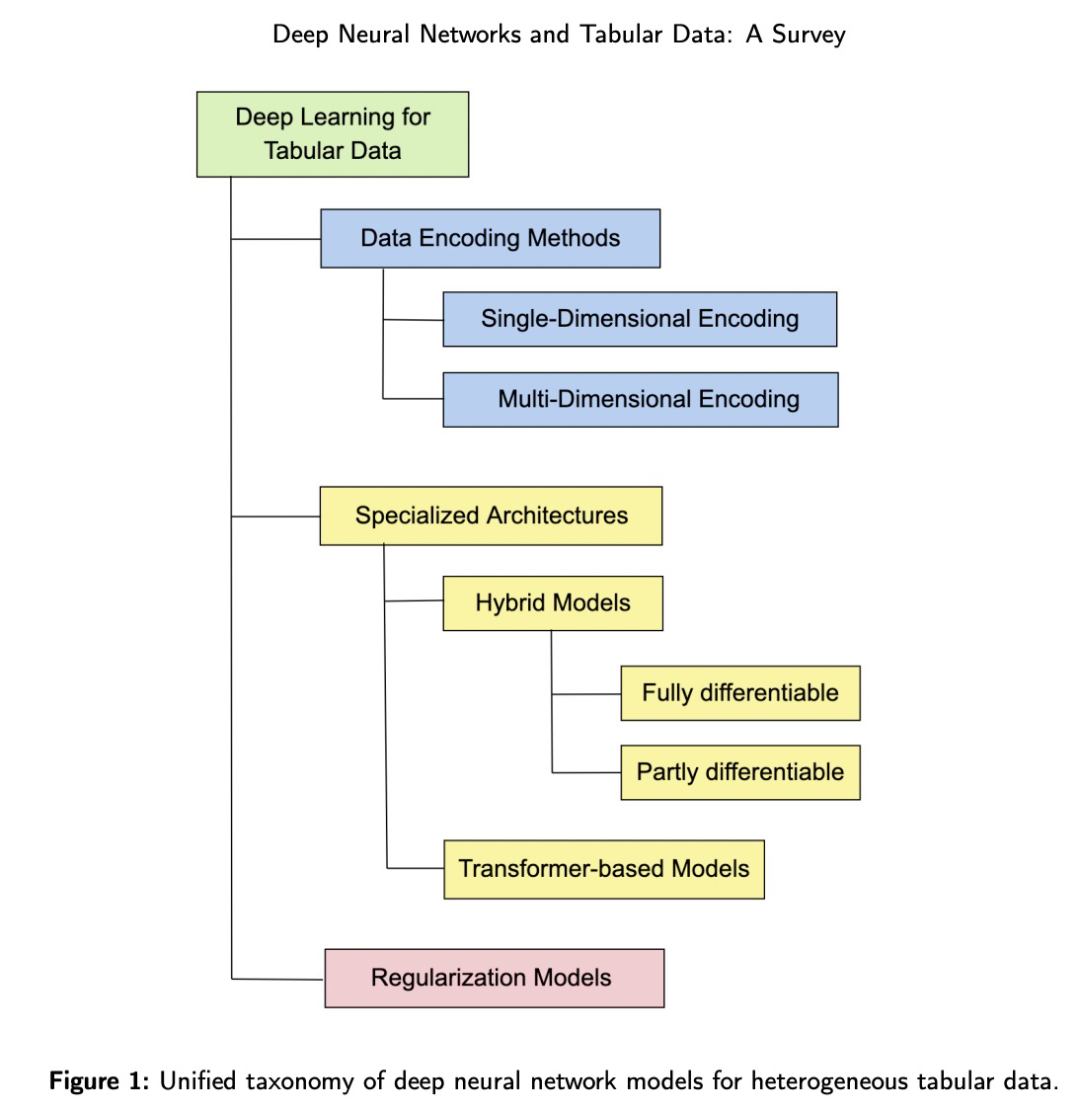
近日,来自图宾根大学等机构的研究者进行了一项表格数据 SOTA 深度学习方法的调查研究。该研究首先将这些方法分为三组:数据转换、专用架构和正则化模型,然后全面概述了每个组中的主要方法。
![]()
论文地址:https://arxiv.org/abs/2110.01889
通过解释表格数据上的深度学习模型,该研究对生成表格数据的深度学习方法展开了详细的讨论。主要贡献包括对领域内的主要研究流派和现有方法进行分类,同时突出相关挑战和开放型研究问题。这是领域内首个深入研究基于表格数据的深度学习方法的工作,可作为表格数据深度学习研究者和从业者的宝贵指南。
深度神经网络的成功是借助大量计算和存储资源和可用的大型标记数据集(Schmidhuber,2015;Goodfellow et al.,2016),特别是基于卷积、循环深度学习机制(Hochreiter and Schmidhuber,1997)或 transformer 网络(Vaswani 等,2017)。
尽管深度学习方法在同类数据(例如图像、音频和文本数据)上的分类或数据生成任务上均表现出色,但表格数据仍然对这些模型构成挑战(Arik and Pfister,2019;Popov et al.,2019); Shwartz-Ziv and Armon,2021)。Kadra 等(2021)将表格数据集命名为深度神经网络模型最后一个「未征服的城堡(unconquered castle)」。
与图像或语言数据相比,表格数据是异构的,导致其具有密集的数值特征和稀疏的分类特征。此外,这些特征之间的相关性也比图像或语音数据中的空间或语义关系弱。变量可以相关也可以独立,特征也没有位置信息。因此,在不依赖空间信息的情况下发现和利用相关性(Somepalli et al.,2021)是很有必要的。
异构数据是最常用的数据形式(Shwartz-Ziv and Armon,2021),它在许多关键应用中无处不在,例如基于患者病史的医学诊断(Ulmer et al.,2020;Somani et al.,2021;Borisov et al.,2021),金融应用的预测分析(Clements et al.,2020)、点击率 (CTR) ) 预测(Guo et al.,2017)、用户推荐系统(Zhang et al.,2019)、客户流失预测(Ahmed et al.,2017;Tang et al.,2020)、网络安全(Buczak and Guven,2015) 、欺诈检测(Cartella et al.,2021)、身份保护(Liu et al.,2021a)、心理学(Urban and Gates,2021)、延迟估计(Shoman et al.,2020)、异常检测(Pang et al.,2021)等等。在所有这些应用程序中,预测性能和稳健性的提升可能对最终用户和提供此类解决方案的公司都有相当大的好处。但其中需要处理许多与数据相关的陷阱,例如噪音、不精确、不同的属性类型和值范围,或者值的不可用。
同时,深度神经网络与传统机器学习方法相比具有多种优势。它们非常灵活(Sahoo et al.,2017),并允许进行高效的迭代训练。深度神经网络对 AutoML 尤其有价值(He et al.,2021;Artzi et al.,2021;Shi et al.,2021;Fakoor et al.,2020;Gijsbers et al.,2019;Yin et al.,2020)。使用深度神经网络可以生成表格数据,例如,可以帮助缓解类不平衡问题(Wang et al.,2019c)。最后,神经网络可以用于多模态学习问题,其中表格数据可以是许多输入模态之一(Baltrušaitis et al.,2018;Lichtenwalter et al.,2021;Shi et al.,2021;Pölsterl et al.,2021;Soares et al.,2021),用于表格数据蒸馏(Medvedev and D'yakonov,2020;Li et al.,2020a),用于联邦学习(Roschewitz et al.,2021)以及更多场景。
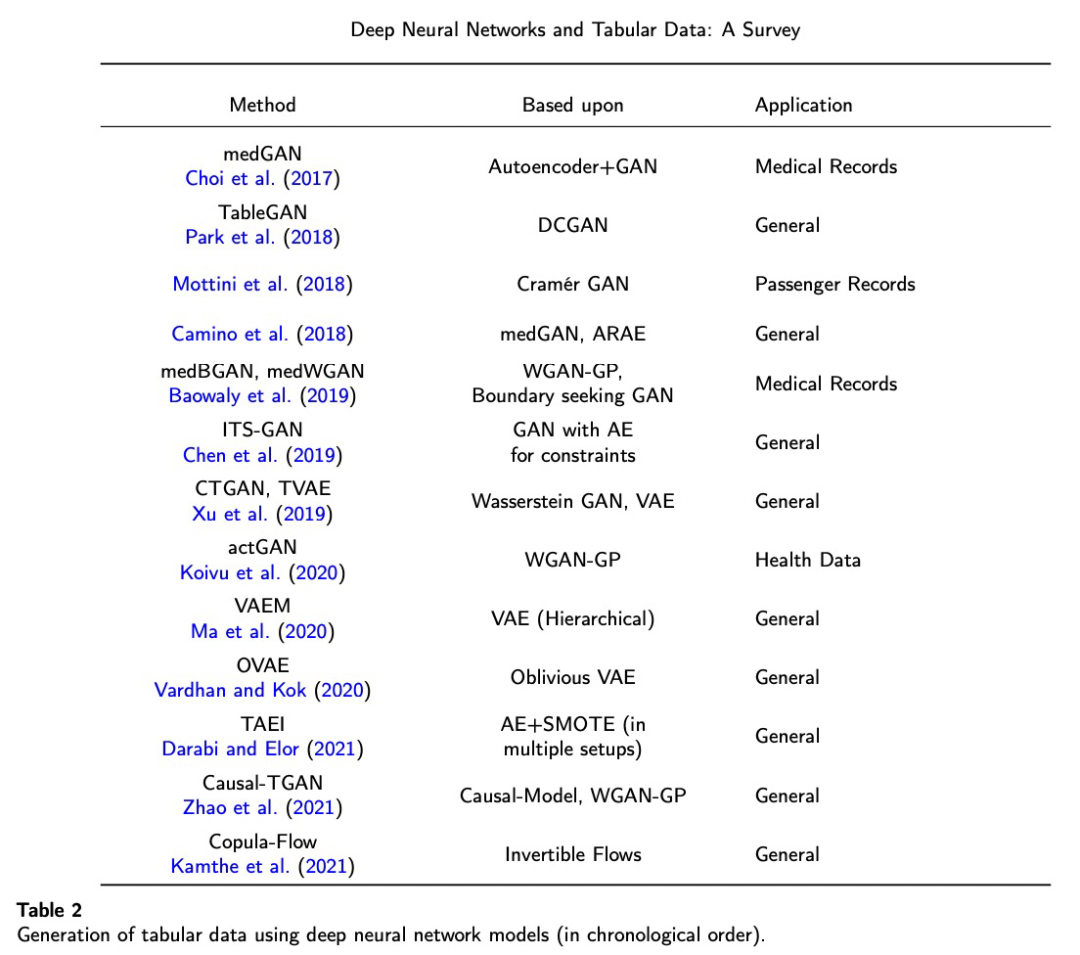
由于数据收集步骤,特别是对于异构数据,成本高昂且耗时,因此有多种方法可以生成合成表格数据。然而,对表格数据中行的概率分布进行建模并生成真实的合成数据具有挑战性,因为异构表格数据通常包括离散和连续变量的混合。连续变量可能有多种模式,而离散列通常是不平衡的。所有这些缺陷与缺失值、噪声值或无界值相结合,使得表格数据生成问题变得相当复杂,即使对于现代深度生成架构也是如此。第 5 章讨论了 SOTA 表格数据生成方法。
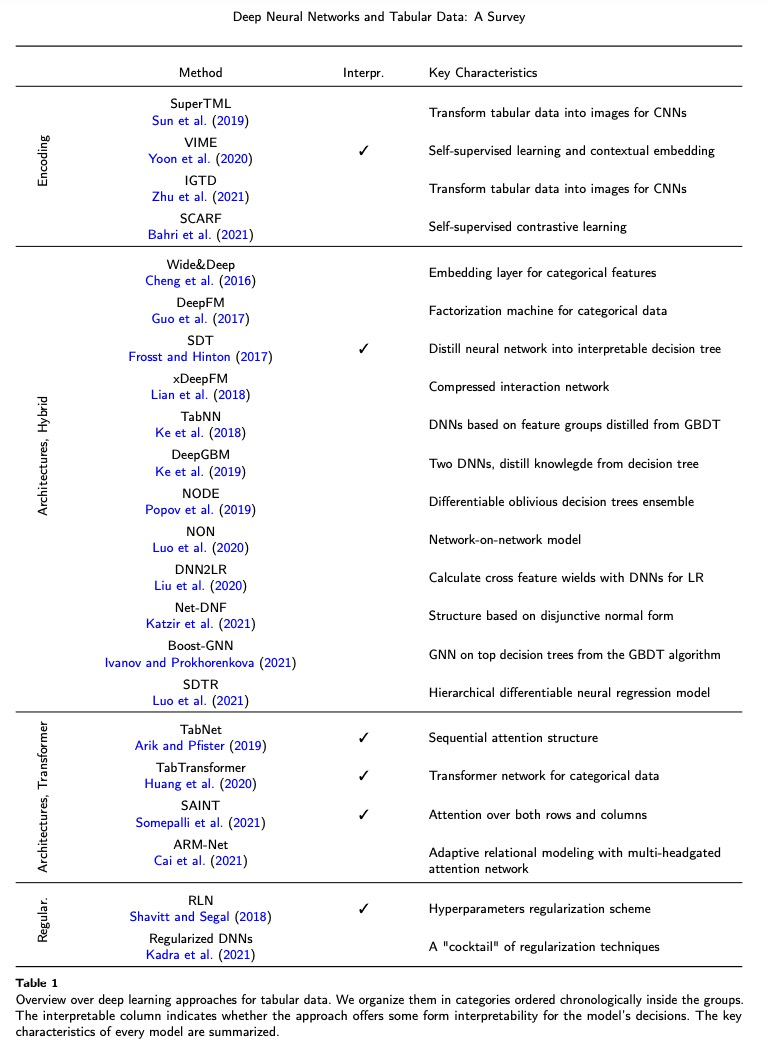
另一个重要方面是对表格数据的深度神经网络的解释(Grisci et al.,2021)。许多用于解释深度神经网络的流行方法源于计算机视觉领域,其中突出显示像素组,创建所谓的显著图。尽管如此,对于表格数据集,突出显示变量关系也是必不可少的。许多现有方法,尤其是那些基于注意力机制的方法 (Vaswani et al., 2017),是通过设计突出显示关系,并且它们的注意力图可以很容易地可视化。
基于本研究,数据科学从业者和研究人员将能够快速为用例或研究问题确定起点和指导。
![]()
![]()
下图 2 是基于表格数据的生成模型的概览(按时间排序)。
![]()
第 2 章讨论相关工作。为了向读者介绍该领域,在第 3 章描述了领域内的数据形式、该领域历史的简要概述、列出了通常遇到的主要挑战,并提出了使用表格数据进行深度学习的可能方法的统一分类法。第 4 章详细介绍了使用深度神经网络对表格数据进行建模的主要方法。第 5 章概述了使用深度神经网络生成表格数据。第 6 章概述了表格数据深层模型的解释机制。在第 7 章总结了该领域的状态并给出了未来的观点。第 8 章论文列出了一些开放型研究问题。
第一期:快速搭建基于Python和NVIDIA TAO Toolkit的深度学习训练环境
英伟达 AI 框架 TAO(Train, Adapt, and optimization)提供了一种更快、更简单的方法来加速培训,并快速创建高度精确、高性能、领域特定的人工智能模型。
11月15日19:30-21:00,英伟达专家带来线上分享,
将介绍:
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com