语言模型微调领域有哪些最新进展?一文详解最新趋势
转载机器之心
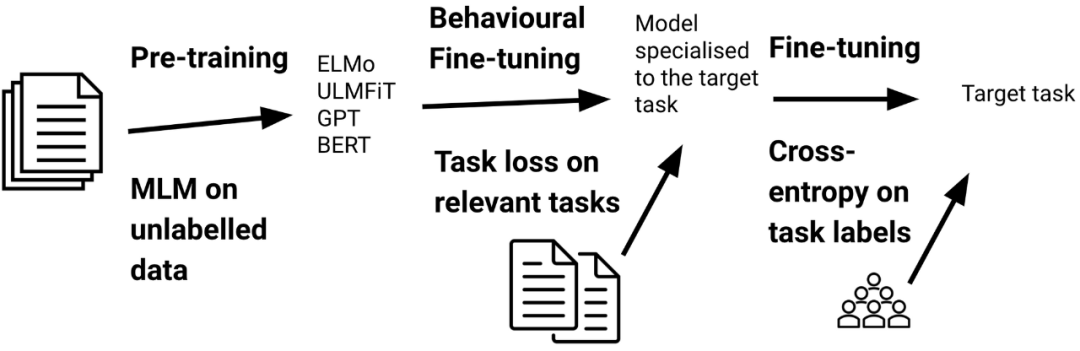
详解 2020 最具影响力的十大 ML、NLP 研究的 DeepMind 研究科学家又来了,这次来讲讲语言模型微调领域的最新进展。
 的参数(其中 D 是模型的维数),需要学习特定于任务的参数向量
的参数(其中 D 是模型的维数),需要学习特定于任务的参数向量
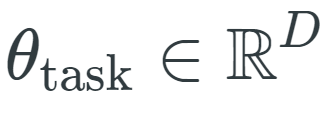 来捕获更改预训练模型参数
来捕获更改预训练模型参数
 的方法。
微调后的参数是将任务特定的排列应用于预训练参数的结果:
的方法。
微调后的参数是将任务特定的排列应用于预训练参数的结果:

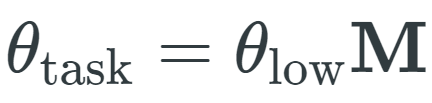 其中,θ_low 是一种低维向量,M 是随机线性投影。
其中,θ_low 是一种低维向量,M 是随机线性投影。
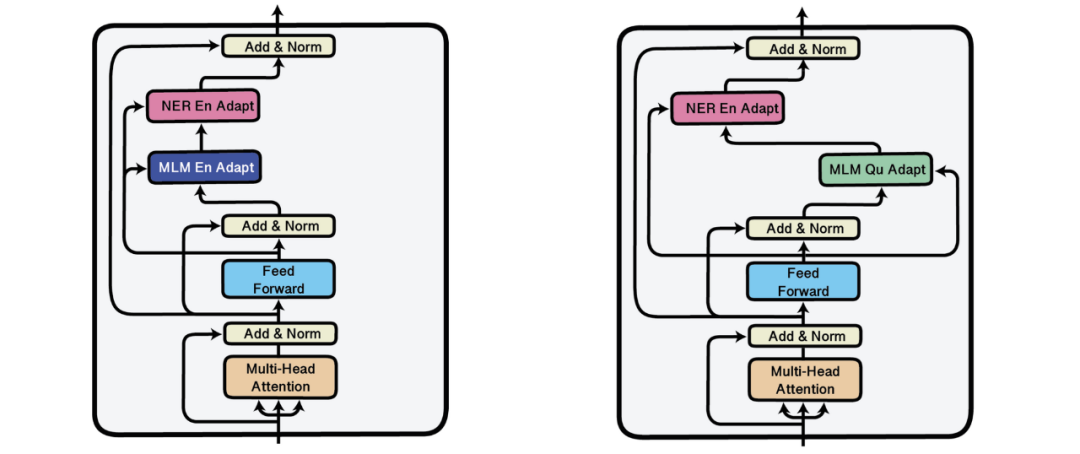
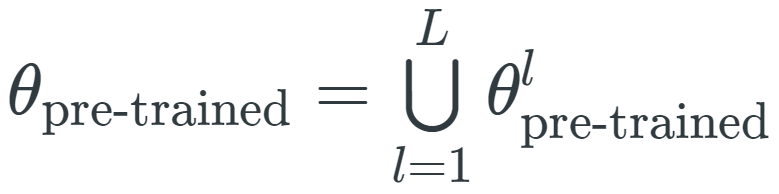 ,其中
,其中
 是与第 l 层相关联的参数向量,表示形式和θ_fine-tuned、θ_task 类似。
因此,仅对最后一层进行微调等效于:
是与第 l 层相关联的参数向量,表示形式和θ_fine-tuned、θ_task 类似。
因此,仅对最后一层进行微调等效于:
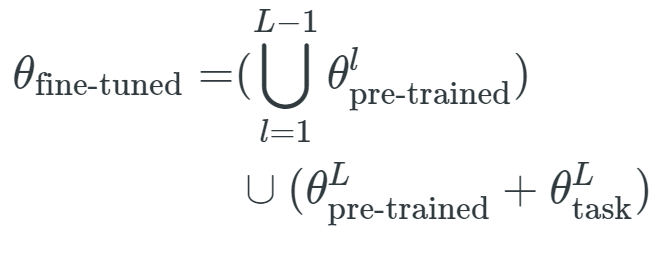
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DAS” 就可以获取《领域自适应研究综述》专知下载链接



登录查看更多
相关内容


相关VIP内容
相关资讯