每日三篇 | 微软vscode与pytorch深度集成;音频中的迁移学习;密集物体检测的焦点损失
Neural Style Transfer for Audio Spectograms
斯坦福的Prateek Verma和Julius O. Smith基于音频的光谱图,利用视觉领域的风格迁移技术进行音频迁移任务。下图中,a为高斯噪声,b是人声(相当于内容图像),c是小提琴音(相当于风格图像),d是神经风格迁移输出(内容为人声,乐器为小提琴)。他们使用的模型为AlexNet,并针对音频任务的特点进行了一些改造,主要是调整损失函数和缩小感受野(以避免产生杂音)。虽然效果不像图像风格迁移那么出色,但这种转换图像,以利用计算机视觉领域技术的思路值得借鉴。
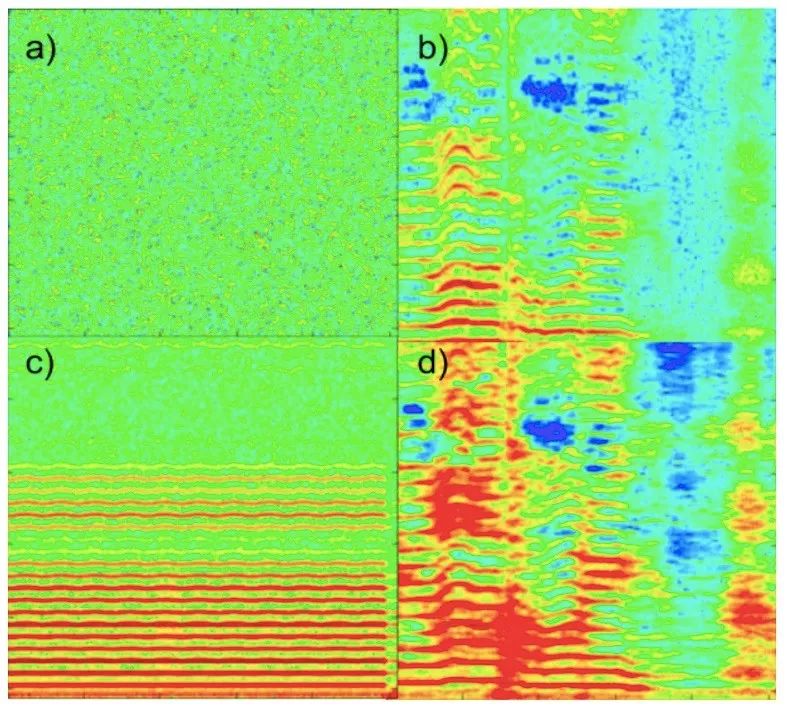
地址:https://arxiv.org/abs/1801.01589
Focal Loss for Dense Object Detection
截至目前,物体检测领域的最高精度模型都基于由R-CNN推广的two-stage方法,把分类器应用于稀疏的候选对象位置集。相比之下,如果我们能用one-stage检测算法在物体可能出现的位置密集采样,物体检测能更快,也更简单,但这种方法目前在精度还有所欠缺。在本文中,我们经过实验发现极端的前景—背景类不平衡是导致one-stage精度不佳的主要原因,而这个不平衡问题可以用重新设计的标准交叉熵损失来解决。
地址:https://arxiv.org/abs/1708.02002
微软vscode与pytorch深度集成
今天,微软vscode推出一项重大更新,让Jupyter Notebook第一次感到“瑟瑟发抖”。它集成了pytorch,当用户在编辑器写代码时,面板左侧能直接显示张量内的值,同时,只要把鼠标简单地悬停在变量上,用户就能直接读取它的类型、权重、bias、dtype、设备等信息。目前Azure还不支持这项更新,但如果微软真的跟进了后续支持,你会放弃AWS上的Jupyter,转投Azure的怀抱吗?
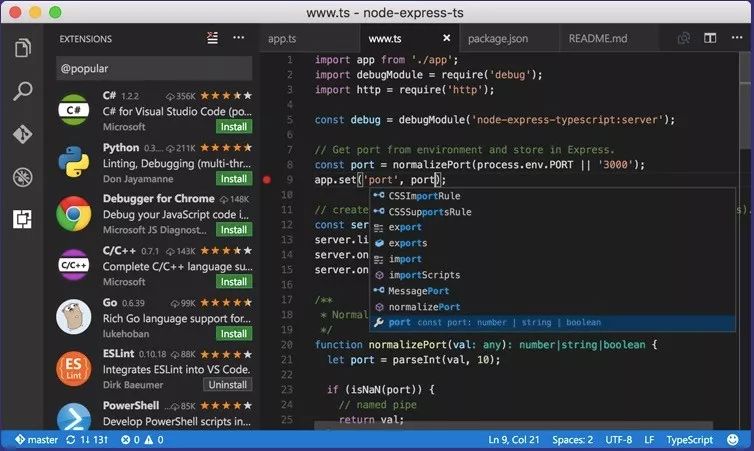
地址:https://code.visualstudio.com/


登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文