YOLO升级到v3版,检测速度比R-CNN快1000倍
2018 区块链技术及应用峰会(BTA)·中国
倒计时 2 天
2018,想要follow最火的区块链技术?你还差一场严谨纯粹的技术交流会——2018区块链技术及应用峰会(BTA)·中国将于2018年3月30-31日登陆北京喜来登长城饭店。追求专业性?你要的这里全都有:当超强嘉宾阵容遇上业界同好的脑洞大联欢,1+1=无限可能,目前门票预购火热进行中。
活动详情: http://dwz.cn/7FI1Ch
译者 | 林椿眄
出品 | 人工智能头条(公众号ID:AI_Thinker)
【人工智能头条导读】YOLO 是当前性能最佳的一个实时检测系统,它在 Pascal Titan X 显卡上处理 COCO test-dev 数据集的图片,速度能达到 30 FPS, mAP 可达 57.9% 。另外, YOLOv3 的检测速度非常快,比 R-CNN 快 1000 倍,比 Fast R-CNN 快 100 倍。本文详细展示了升级后的 YOLOv3 与其他检测器的数据对比,以及 YOLOv3 的工作原理等。
▌与其他检测器相对比
YOLOv3 是非常快速而且准确的检测器。在 IoU=0.5 的情况下,其 mAP 值与 Focal Loss 相当,但检测速度快了 4 倍。此外,你可以根据你的需要,在只需改变模型的大小而不需要进行重新训练的情况下,就可以轻松地权衡检测速度和准确度。
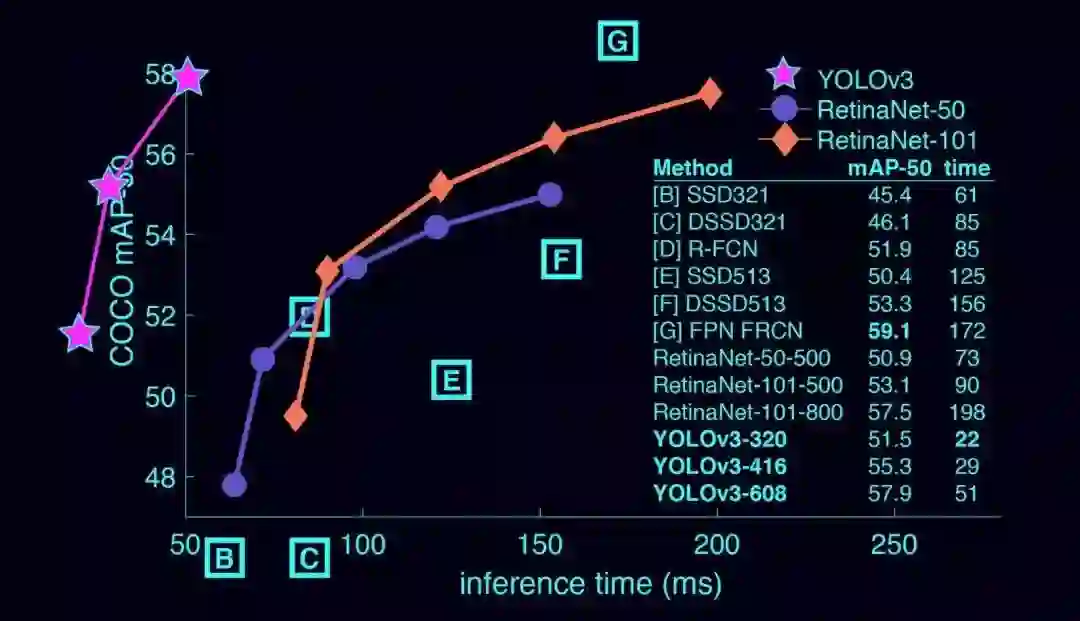
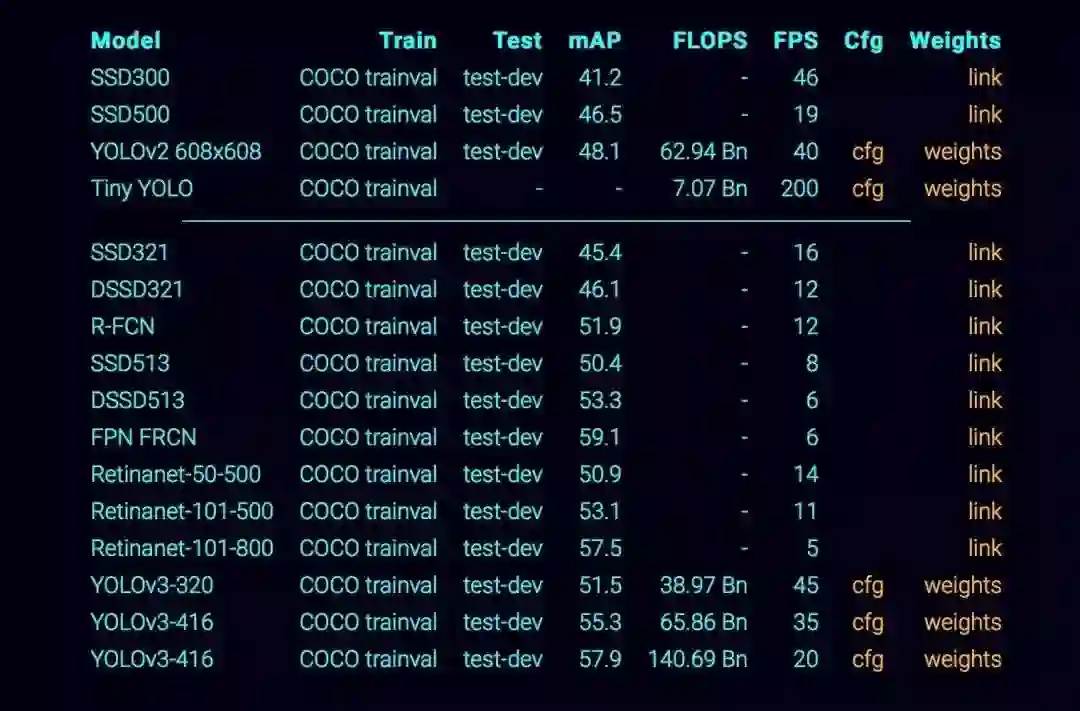
▌在 COCO 数据集上的表现
▌YOLOv3 的工作原理
先前的检测系统是分别设计分类器或定位器,并让其分别来执行检测任务。它们将模型应用于图片中,图片中目标的位置和尺寸各不相同,图片的高得分区域被认为是检测区域。
在此,我们采用了完全不同的方法。我们将一个简单的神经网络应用于整张图像。该网络会将图像分割成一块块区域,并预测每个区域目标的的边界框(bounding box)和概率。此外,预测的概率值还对这些边界框进行加权。

我们的模型相较之前的基于分类的检测系统有如下优势:在测试阶段,它是以整张图像作为输入,预测会由图像中的全局上下文 ( global context ) 引导。此外,我们的模型不像 R-CNN 这种检测系统,需要对一张图做出成千上万次预测,我们的模型只需要通过单个神经网络既能够做出预测评估。
不仅如此,YOLOv3 的检测速度非常快,比 R-CNN 快 1000 倍,比 Fast R-CNN 快 100 倍。感兴趣的可以参阅论文(https://pjreddie.com/media/files/papers/YOLOv3.pdf),了解更多关于完整系统的细节。
YOLOv3 的创新点
YOLOv3 用了一些小技巧来改善模型训练并提高其检测性能,包括多尺度预测,更好的主干分类器等等。更多详细信息可以通过我们的论文进一步了解。
用一个预训练模型进行检测
接下来,我们将使用一个预训练模型,在 YOLO系统中实现目标检测。首先,请先确认你已安装了 Darknet 。接下来运行如下语句:
git clone https://github.com/pjreddie/darknet
cd darknet
make
这样一来,在你的 cfg/ 子目录中就有了 YOLO 配置文件。接下来你需要下载预训练的 weight 文件( https://pjreddie.com/media/files/yolov3.weights ),大小约为 237 MB。或者也可以运行如下语句来获得:
wget https://pjreddie.com/media/files/yolov3.weights
然后运行检测器。
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
你将看到类似如下的输出结果:
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
.......
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
truth_thresh: Using default '1.000000'
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 0.029329 seconds.
dog: 99%
truck: 93%
bicycle: 99%
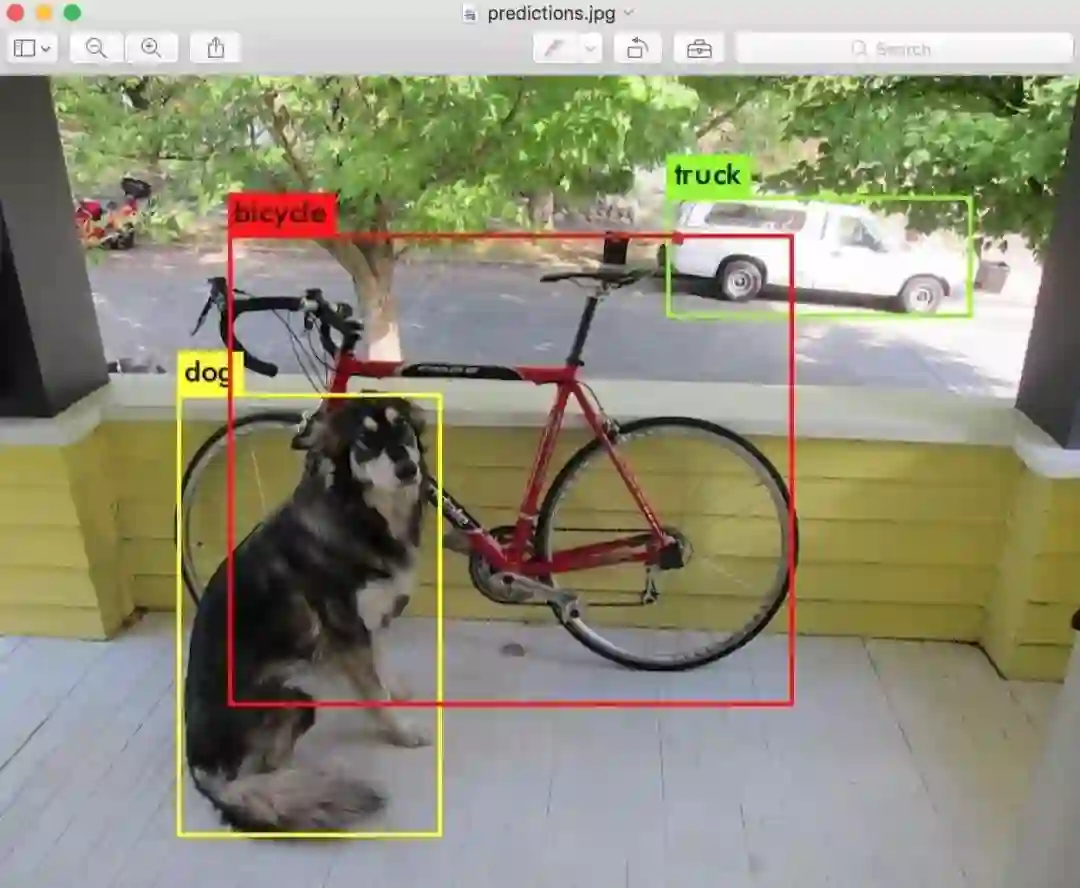
Darknet 会输出检测到的物体、置信度 confidence 以及检测的时间。我们没有用 OpenCV 来编译 Darknet ,所以我们无法直接查看检测情况。检测的结果将被保存在 predictions.png 中。你可以打开这个图片来查看我们模型所检测到的对象。此外,由于我们是在 CPU 上使用 Darknet ,检测每张图片大约需要 6-12 秒,如果有条件使用 GPU 的话,检测速度将快得多。
此外,我还附上了一些例图来供参考,你可以用我们的模型尝试 data/eagle.jpg ,data/dog.jpg , data/person.jpg 或 data/horses.jpg 这些图片,看看最终的检测结果。
detect 指令是对命令行的常规版本的缩写,它等价于如下的命令行操作:
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
如果你只是想检测一张图像,那么你并不需要了解这个,但如果你想做其他的事情,比如在网络摄像头上运行 YOLO (稍后详细描述),那么这将对你非常有用。
检测多张图像
相比于在命令行写入一张图像信息,你可以尝试在一行命令中运行多张图片。随后,模型会加载配置和权重,你将看到如下提示:
./darknet detect cfg/yolov3.cfg yolov3.weights
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
.......
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
Loading weights from yolov3.weights...Done!
Enter Image Path:
输入一个类似 data/horses.jpg 的图像路径来预测图中目标的边框。
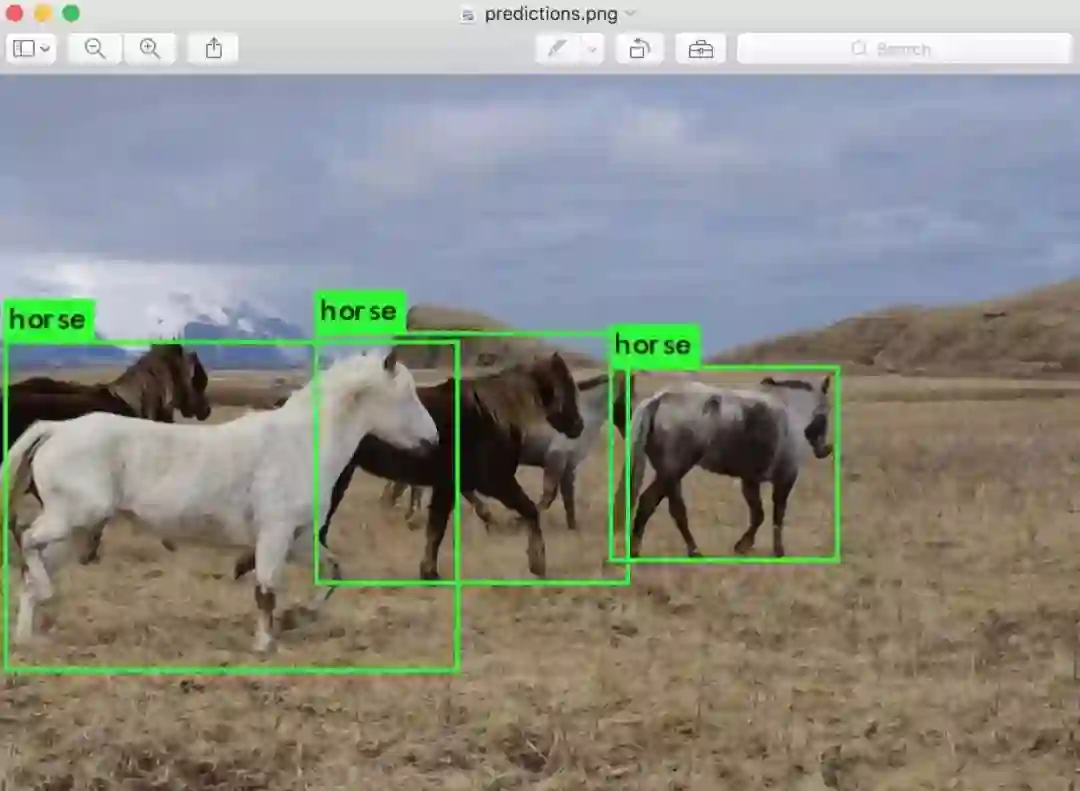
一旦完成,它将提示你输入更多路径来检测不同的图像。使用 Ctrl-C 退出当前程序。
改变检测的阈值
默认情况下,YOLO 只会显示检测目标的置信度 confidence 大于等于 0.25 的物体。你也可以在 YOLO 命令中加入 -thresh <val> 语句来更改检测置信度阈值。例如,将置信度阈值设置为 0 可以显示所有的检测结果:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0
可以看到,这样的阈值设置并不是特别有用。你应该根据你的需要设置不同的阈值来控制你想要的检测结果。
▌使用网络摄像头进行实时检测
如果在测试数据上运行 YOLO 却得不到想要的检测结果,那将是很郁闷的事情。与其用一堆图片作为 YOLO 的输入,不如选择摄像头输入。
要运行如下 demo,你只需要用 CUDA 和 OpenCV 来编译 Darknet 。接下来运行如下命令行:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
YOLO 将会显示当前的 FPS 和目标的预测分类,以及带 bounding box 的图像。
你需要一个连接到电脑的摄像头以便连接 OpenCV,否则它将无法工作。如果你连接了多个摄像头而只想选择其中某一个,可以使用 -c <num> 语句 ( OpenCV 在默认情况下使用摄像头 0 )。
如果 OpenCV 可以直接读取视频数据,那么你也可以在视频文件中运行如下命令:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>
以上就是我们展示的是如何使用Youtube视频数据作为YOLO的输入。
▌在 VOC 数据集上训练 YOLO
如果你想在 YOLO 上尝试不同的训练机制,超参数或数据集,那么你可以从头开始训练 YOLO 。 以下我将展示是如何在 YOLO 上使用 Pascal VOC 数据集。
获取 Pascal VOC 数据
首先我们需要 2007 - 2012 年间的所有 VOC 数据,你可以通过这个链接下载获取( https://pjreddie.com/projects/pascal-voc-dataset-mirror/ )。然后,你需要先存储这些数据,运行如下命令:
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
这样,所有的 VOC 训练数据都在 VOCdevkit / 子目录下。
生成 VOC 数据集的标签
现在,需要生成 Darknet 模型所需的标签文件。Darknet 需要的是每张图片的 .txt 文件,其内容是图片中目标的真实标签值,格式如下:
<object-class> <x> <y> <width> <height>
其中,x ,y , width 和 height 分别对应图像的宽和高。需要在 Darknet 中的 scripts/ 子目录下运行 voc_label.py 脚本来生成这些文件。我们运行如下命令行来演示下这个过程:
wget https://pjreddie.com/media/files/voc_label.pypython voc_label.py
几分钟后,这个脚本将生成 Darknet 的所需文件。大部分标签文件是在 VOCdevkit/VOC2007/labels/ 和 VOCdevkit/VOC2012/labels/ 下,你可以在目录下查看如下信息:
ls
2007_test.txt VOCdevkit
2007_train.txt voc_label.py
2007_val.txt VOCtest_06-Nov-2007.tar
2012_train.txt VOCtrainval_06-Nov-2007.tar
2012_val.txt VOCtrainval_11-May-2012.tar
诸如 2007_train.txt 这样的文件列出了图像文件的年份和所处的图像集。Darknet 需要一个包含你想要训练的所有图片的文件。在这个例子中,我们要训练的是除了 2007 测试集以外的所有数据。你可以运行如下语句:
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
这样,我们可以用一个大的列表来显示我们想要的数据,包括 2007 trainval 和 2012 trainval 数据集。以上就是我们数据准备阶段的工作。
修改 Pascal Data 中的 cfg 文件
现在,我们在 Darknet 目录,改变 cfg/voc.data 配置文件并使其指向我们的数据,运行如下命令:
1 classes= 20
2 train = <path-to-voc>/train.txt
3 valid = <path-to-voc>2007_test.txt
4 names = data/voc.names
5 backup = backup
可以将 <path-to-voc> 替换为你存放 VOC 数据集的目录。
下载预训练好的卷积权重
训练阶段,我们使用在 Imagenet 上预训练的卷积权重。在这里我们使用预训练的 darknet53 模型权重,你可以点击这里下载卷积层权重( https://pjreddie.com/media/files/darknet53.conv.74 ),大小约为 76 MB:
wget https://pjreddie.com/media/files/darknet53.conv.74
训练模型
现在,我们运行如下命令来训练我们的模型:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
▌在 COCO 上训练 YOLO
如果你想在 YOLO 上尝试不同的训练机制,超参数或数据集,那么你可以从头开始训练 YOLO 。 以下我将展示是如何在 YOLO 上使用 COCO 数据集。
获取 COCO 数据
为了在 COCO 数据集上训练 YOLO 模型,首先你需要获取 COCO 数据及其标签。运行 scripts/get_coco_dataset.sh 脚本,并给出你想存放 COCO 数据的地址,然后下载数据,如下命令:
cp scripts/get_coco_dataset.sh data
cd data
bash get_coco_dataset.sh
现在,你已经有了训练 Darknet 模型所需的数据及标签值。
修改 COCO 数据集中的 cfg 文件
现在,我们在 Darknet 目录,改变 cfg/voc.data 配置文件并使其指向我们的数据,运行如下命令:
1 classes= 80
2 train = <path-to-coco>/trainvalno5k.txt
3 valid = <path-to-coco>/5k.txt
4 names = data/coco.names
5 backup = backup
你可以将 <path-to-coco> 替换为你存放 COCO 数据集的目录。
你还需要在训练时修改模型的 cfg 文件,而不是测试阶段的 . cfg/yolo.cfg,操作如下:
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=8
....
训练模型
现在,我们运行如下命令来训练我们的模型:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74
如果你想在多 GPU 环境下运行的话,运行如下命令:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74 -gpus 0,1,2,3
如果你想在停止当前训练并从某个检查点 ( checkpoint ) 开始重新训练的话,运行如下命令:
./darknet detector train cfg/coco.data cfg/yolov3.cfg backup/yolov3.backup -gpus 0,1,2,3
▌旧版本的 YOLO
如果你想使用 YOLO2 版本,你可以通过以下链接获取:https://pjreddie.com/darknet/yolov2/
▌引用
如果你想在你的研究中使用 YOLOv3 ,请引用我们的论文:
@article{yolov3,
title={YOLOv3: An Incremental Improvement},
author={Redmon, Joseph and Farhadi, Ali},
journal = {arXiv},
year={2018}
}
作者 | Joseph Redmon Ali Farhadi
原文链接 | https://pjreddie.com/darknet/yolo/
2018年3月30-31日,第二届中国区块链技术暨应用大会将于北京喜来登长城饭店盛大开场,50+区块链技术领导人物,100+区块链投资商业大咖,100+技术&财经媒体,1000+区块链技术爱好者,强强联合,共同探讨最in区块链技术,豪华干货礼包享不停。八折门票火热抢购中!2018,未来已来,带你玩转区块链。