【干货】用极少量样本有效的训练分类器-对抗自编码器PyTorch手把手实战系列
即使是非计算机行业, 大家也知道很多有名的神经网络结构, 比如CNN在处理图像上非常厉害, RNN能够建模序列数据. 然而CNN, RNN之类的神经网络结构本身, 并不能用于执行比如图像的内容和风格分离, 生成一个逼真的图片, 用少量的label信息来分类图像, 或者做数据压缩等任务. 因为上述几个任务, 都需要特殊的网络结构和训练算法 .
有没有一个网络结构, 能够把上述任务全搞定呢? 显然是有的, 那就是对抗自编码器Adversarial Autoencoder(AAE) . 在本文中, 我们尝试用极少量(1000个)的label去训练一个有效的分类器:用极少label分类MNIST。
本系列文章, 专知小组成员Huaiwen一共分成四篇讲解,这是第三篇:
自编码器实例应用: 用极少label分类MNIST
终于到了本系列的末尾,拖稿拖了很久了。。。。。。
在本系列中,我们自编码器开始讲起,先是阐述了什么是自编码器, 什么是对抗自编码器,以及他们的实现方法。然后利用对抗自编码器,学习了每个人的笔迹风格(字体),本篇,我们尝试用极少量(1000个)的label去训练一个有效的分类器。
首先我们要将MNIST数据集切分一下,切出少量label的训练集,而整体的10k的测试集不变。 具体切割代码见文章末尾。
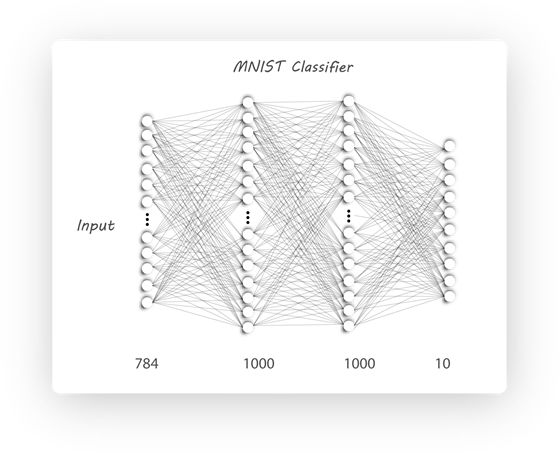
分割完之后,我们可以直接用1000个label做分类了,我们使用基础的全连接神经网络,我们可以称之为nn_basic ,见下图:
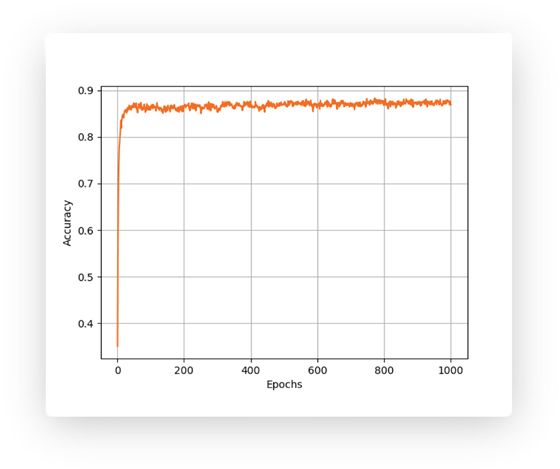
经过大概50个epoch,模型的测试精度已经达到了87%,如下图所示,注意,我们只用了1000个标记图像,如果用全部的50K个,效果会比这个高很多。
怎么在这1000个label数据上,继续往上提升性能?
仔细观察上一篇的架构图:
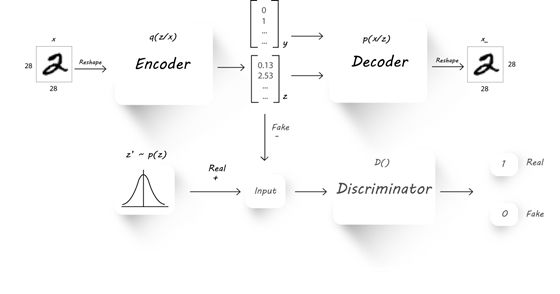
尤其是架构中y的位置,我们可以想到一个非常直观的idea,既然encoder能生成z,干脆也把y(label)生成了吧,y的位置这么适合生成
我们可以改一下上一篇的架构,让encoder顺便生成y:
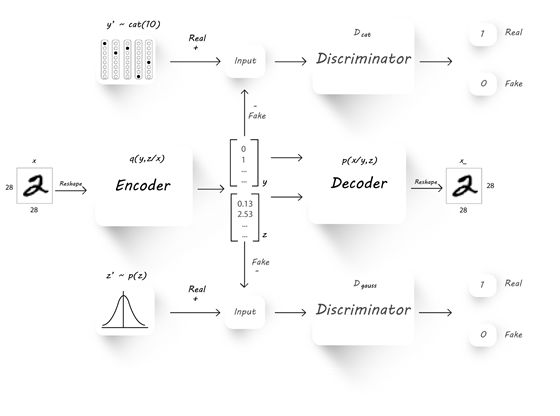
思路与上一篇的encoder生成z一模一样,我们从一个真实分布中采样y,然后把encoder生成的当做GAE中的生成器,目标是尽量让生成的y,与真实的y分布接近。
有了上述思路,我们接下来讨论,如何训练?
如何训练?
首先要降低重建误差,这也是自编码器的本质问题:
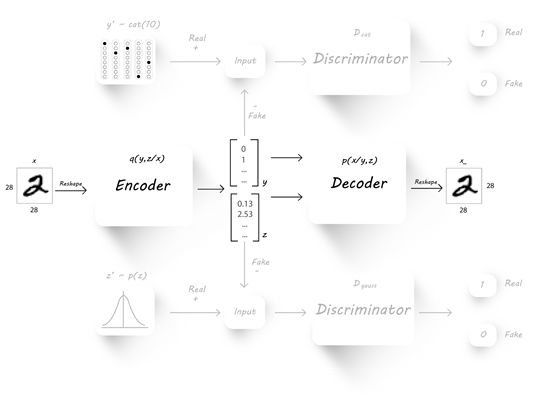
正如上图所示,抛开那些花里胡哨的GAN生成y和z的部分,中间的核心仍然是自编码器,我们的目标是降低重建误差。
降低完重建误差,我们要考虑,让encoder更好的生成y,同时让D_cat更好的区分y和y_fake,这是一个标准的GAN的训练流程:
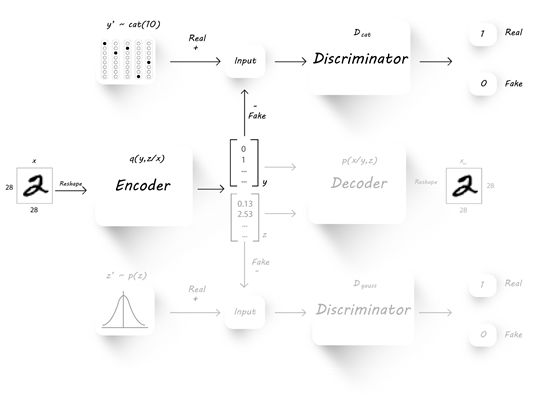
类似的步骤,相信看过上一篇文章的同学应该很熟悉了。之后,相信同学们会更熟悉,因为降低生成隐层z的误差的过程与上一篇文章一模一样。
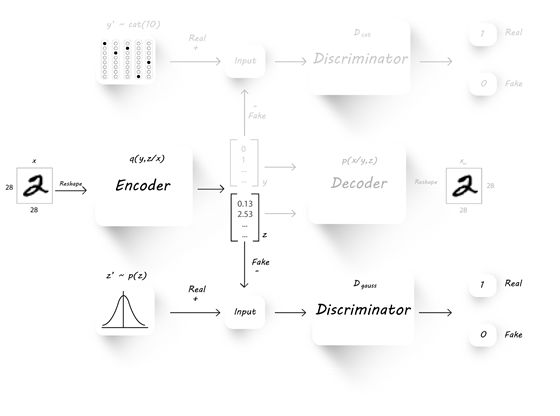
接下来,需要降低分类误差,这里我们的1000个监督信息要上场了:
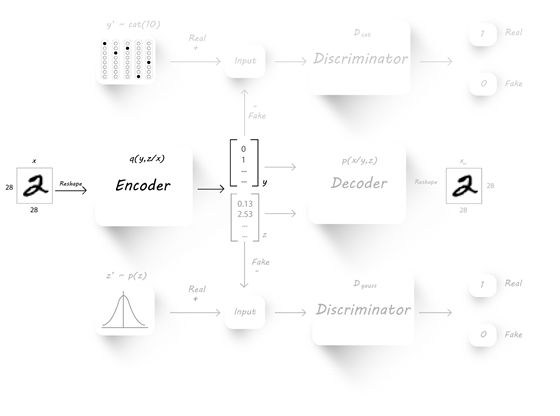
只看encoder 和它生成的y,这是一个简单的全连接分类器,正如我们一开始实现的那个nn_basic 一样。
具体代码
根据上面的架构图和训练流程,我们首先要修改Encoder:
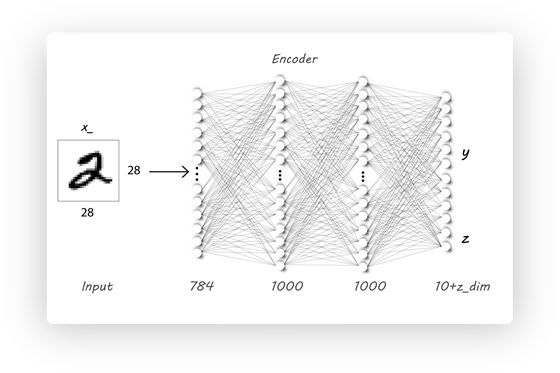
Encoder现在既要生成 y (10维的one-hot), 又要生成z(维度为:z_dim):
# Encoder
class Q_net(nn.Module):
def __init__(self):
super(Q_net, self).__init__()
self.lin1 = nn.Linear(X_dim, N)
self.lin2 = nn.Linear(N, N)
# 隐层变量 z
self.lin3gauss = nn.Linear(N, z_dim)
# 类别label y
self.lin3cat = nn.Linear(N, n_classes)
def forward(self, x):
x = F.dropout(self.lin1(x), p=0.25, training=self.training)
x = F.relu(x)
x = F.dropout(self.lin2(x), p=0.25, training=self.training)
x = F.relu(x)
xgauss = self.lin3gauss(x)
xcat = F.softmax(self.lin3cat(x))
return xcat, xgauss
那么Decoder也要根据架构图做相应修改:
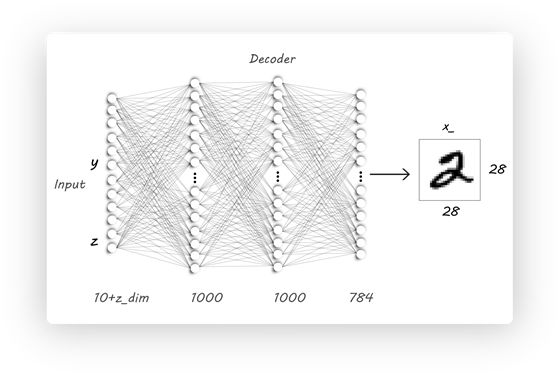
# Decoder
class P_net(nn.Module):
def __init__(self):
super(P_net, self).__init__()
self.lin1 = nn.Linear(z_dim + n_classes, N)
self.lin2 = nn.Linear(N, N)
self.lin3 = nn.Linear(N, X_dim)
def forward(self, x):
x = self.lin1(x)
x = F.dropout(x, p=0.25, training=self.training)
x = F.relu(x)
x = self.lin2(x)
x = F.dropout(x, p=0.25, training=self.training)
x = self.lin3(x)
return F.sigmoid(x)
下面我们来看z 和 y的判别器的实现:
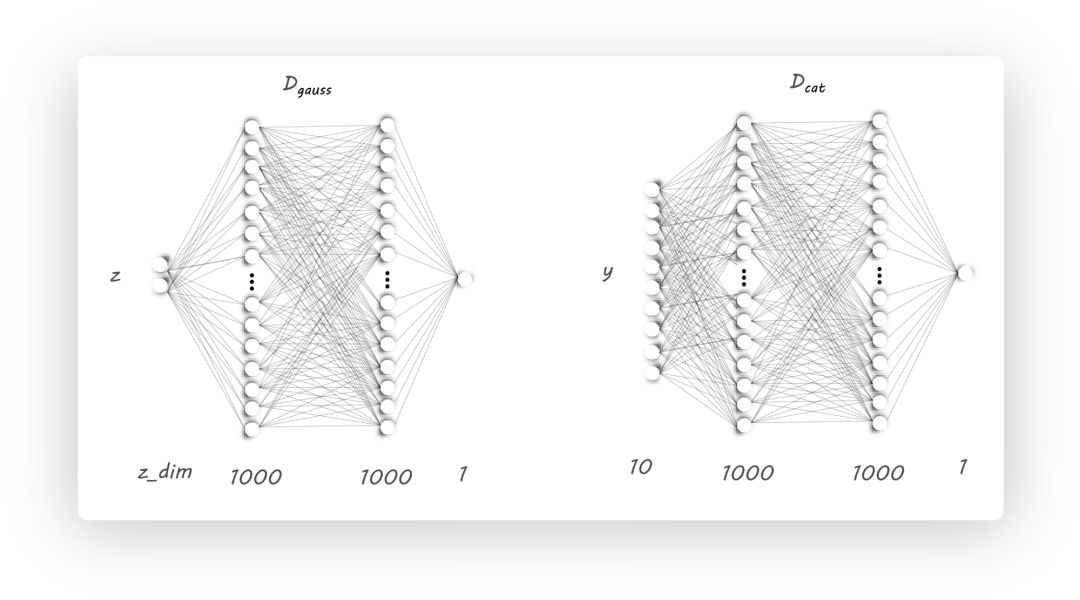
# 类别y 的判别器
class D_net_cat(nn.Module):
def __init__(self):
super(D_net_cat, self).__init__()
self.lin1 = nn.Linear(n_classes, N)
self.lin2 = nn.Linear(N, N)
self.lin3 = nn.Linear(N, 1)
def forward(self, x):
x = self.lin1(x)
x = F.relu(x)
x = F.dropout(x, p=0.2, training=self.training)
x = self.lin2(x)
x = F.relu(x)
x = self.lin3(x)
return F.sigmoid(x)
# 隐含向量z 的判别器
class D_net_gauss(nn.Module):
def __init__(self):
super(D_net_gauss, self).__init__()
self.lin1 = nn.Linear(z_dim, N)
self.lin2 = nn.Linear(N, N)
self.lin3 = nn.Linear(N, 1)
def forward(self, x):
x = F.dropout(self.lin1(x), p=0.2, training=self.training)
x = F.relu(x)
x = F.dropout(self.lin2(x), p=0.2, training=self.training)
x = F.relu(x)
return F.sigmoid(self.lin3(x))
具体的训练流程比较复杂,在这里,我们就贴一些关键步骤,详细请访问:
if not labeled:
z_sample = torch.cat(Q(X), 1)
X_sample = P(z_sample)
#######################
# autoencoder重建
#######################
recon_loss = F.binary_cross_entropy(X_sample + TINY,
X.resize(train_batch_size, X_dim) + TINY)
recon_loss = recon_loss
recon_loss.backward()
P_decoder.step()
Q_encoder.step()
P.zero_grad()
Q.zero_grad()
D_cat.zero_grad()
D_gauss.zero_grad()
recon_loss = recon_loss
#######################
# y, z的生成
#######################
Q.eval()
z_real_cat = sample_categorical(train_batch_size,
n_classes=n_classes)
z_real_gauss = Variable(torch.randn(train_batch_size, z_dim))
if cuda:
z_real_cat = z_real_cat.cuda()
z_real_gauss = z_real_gauss.cuda()
z_fake_cat, z_fake_gauss = Q(X)
D_real_cat = D_cat(z_real_cat)
D_real_gauss = D_gauss(z_real_gauss)
D_fake_cat = D_cat(z_fake_cat)
D_fake_gauss = D_gauss(z_fake_gauss)
D_loss_cat = -torch.mean(torch.log(D_real_cat + TINY) +
torch.log(1 - D_fake_cat + TINY))
D_loss_gauss = -torch.mean(torch.log(D_real_gauss + TINY) +
torch.log(1 - D_fake_gauss + TINY))
D_loss = D_loss_cat + D_loss_gauss
D_loss = D_loss
D_loss.backward()
D_cat_solver.step()
D_gauss_solver.step()
P.zero_grad()
Q.zero_grad()
D_cat.zero_grad()
D_gauss.zero_grad()
# Generator
Q.train()
z_fake_cat, z_fake_gauss = Q(X)
D_fake_cat = D_cat(z_fake_cat)
D_fake_gauss = D_gauss(z_fake_gauss)
G_loss = - torch.mean(torch.log(D_fake_cat + TINY)) -
torch.mean(torch.log(D_fake_gauss + TINY))
G_loss = G_loss
G_loss.backward()
Q_generator.step()
P.zero_grad()
Q.zero_grad()
D_cat.zero_grad()
D_gauss.zero_grad()
#######################
# 半监督部分,分类器的训练
#######################
if labeled:
pred, _ = Q(X)
class_loss = F.cross_entropy(pred, target)
class_loss.backward()
Q_semi_supervised.step()
P.zero_grad()
Q.zero_grad()
D_cat.zero_grad()
D_gauss.zero_grad()
最终,在没怎么调参的情况下,我们可以获得95%以上的准确率,见下图:
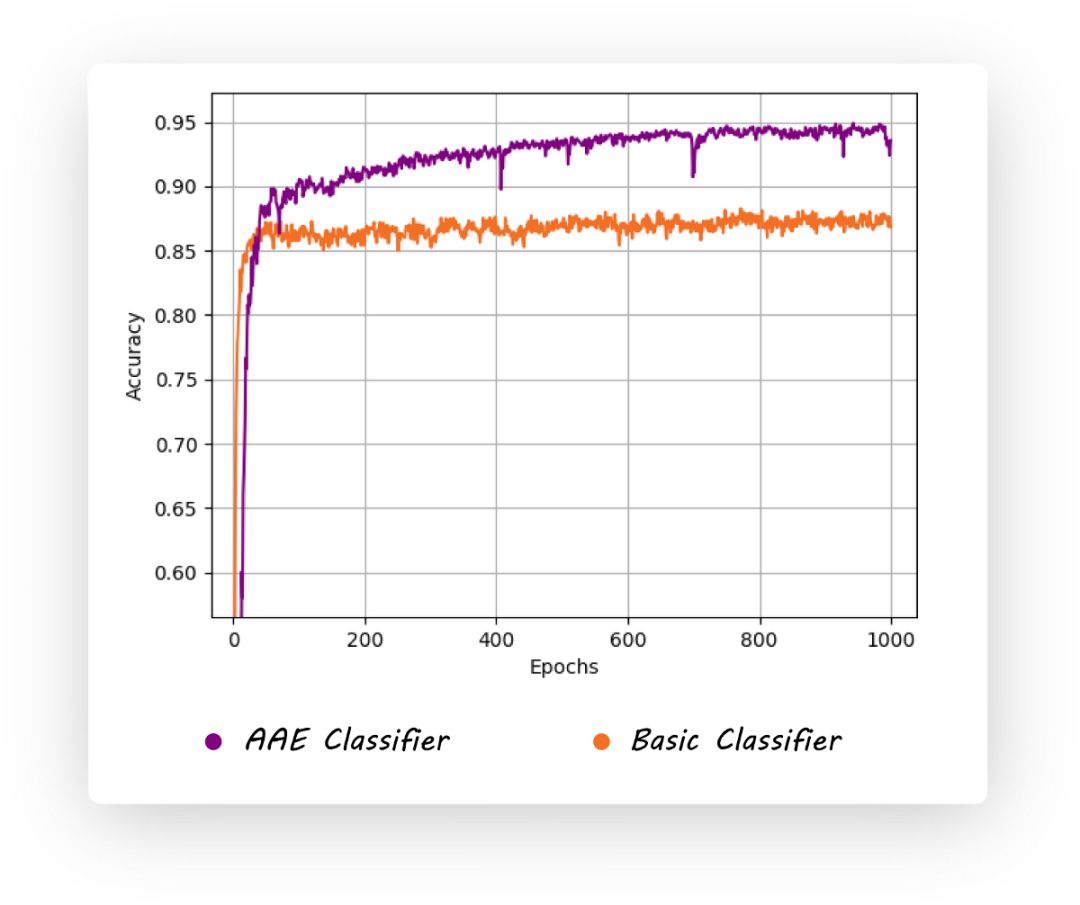
最后,让我们看一看整个模型的生成过程,验证一下训练过程有没有发生异常:
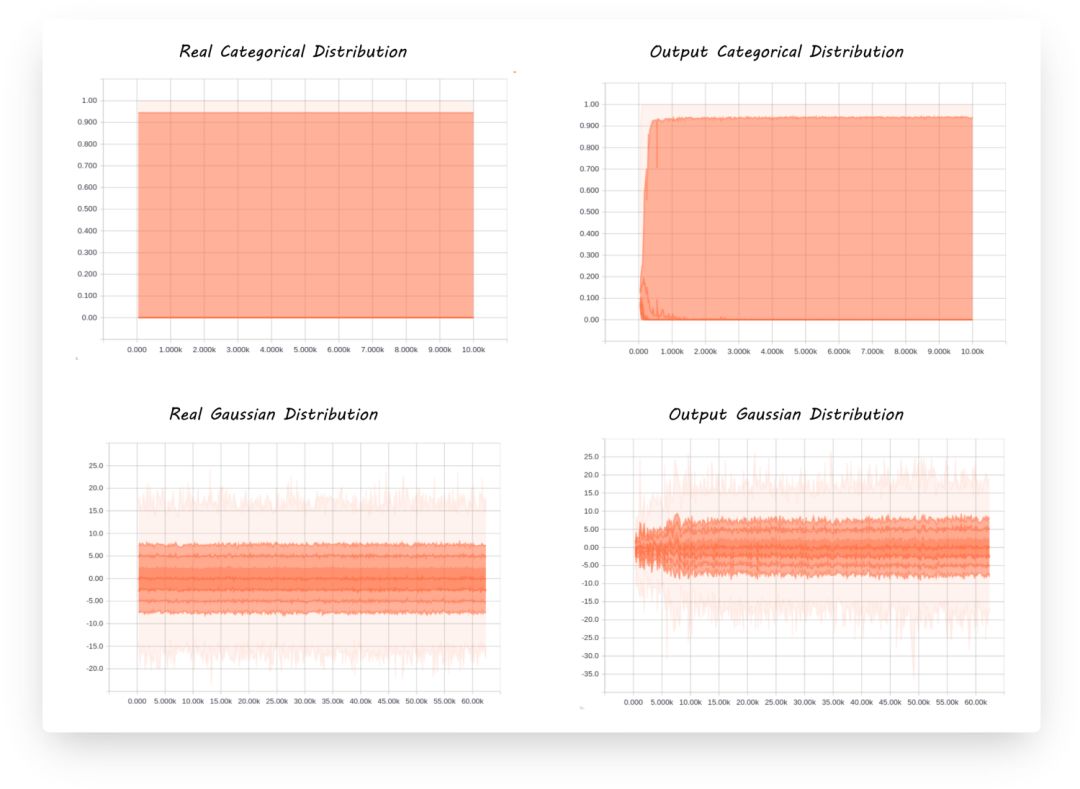
显然,encoder生成的y (右上),和生成的z (右下), 都在拟合左侧的真是分布。
那么,到此,对抗自编码的教程就全部结束啦,大家有什么意见和建议,可以跟我们联系,如果你希望我们出一下其他的教程,欢迎在评论区留言。
本文的代码链接:
http://p57mvlyrw.bkt.clouddn.com/code.zip
更多教程资料请访问:人工智能知识资料全集
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知



