模仿学习 比较图
ONE-SHOT HIGH-FIDELITY IMITATION: TRAINING LARGE-SCALE DEEP NETS WITH RL
Tom Le Paine∗ , Sergio Gomez Colmenarejo ´ ∗ , Ziyu Wang, Scott Reed, Yusuf Aytar, Tobias Pfaff, Matt Hoffman, Gabriel Barth-Maron, Serkan Cabi, David Budden, Nando de Freitas DeepMind London, UK {tpaine,sergomez,ziyu,reedscot,yusufaytar,tpfaff, mwhoffman,gabrielbm,cabi,budden,nandodefreitas}@google.com
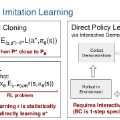
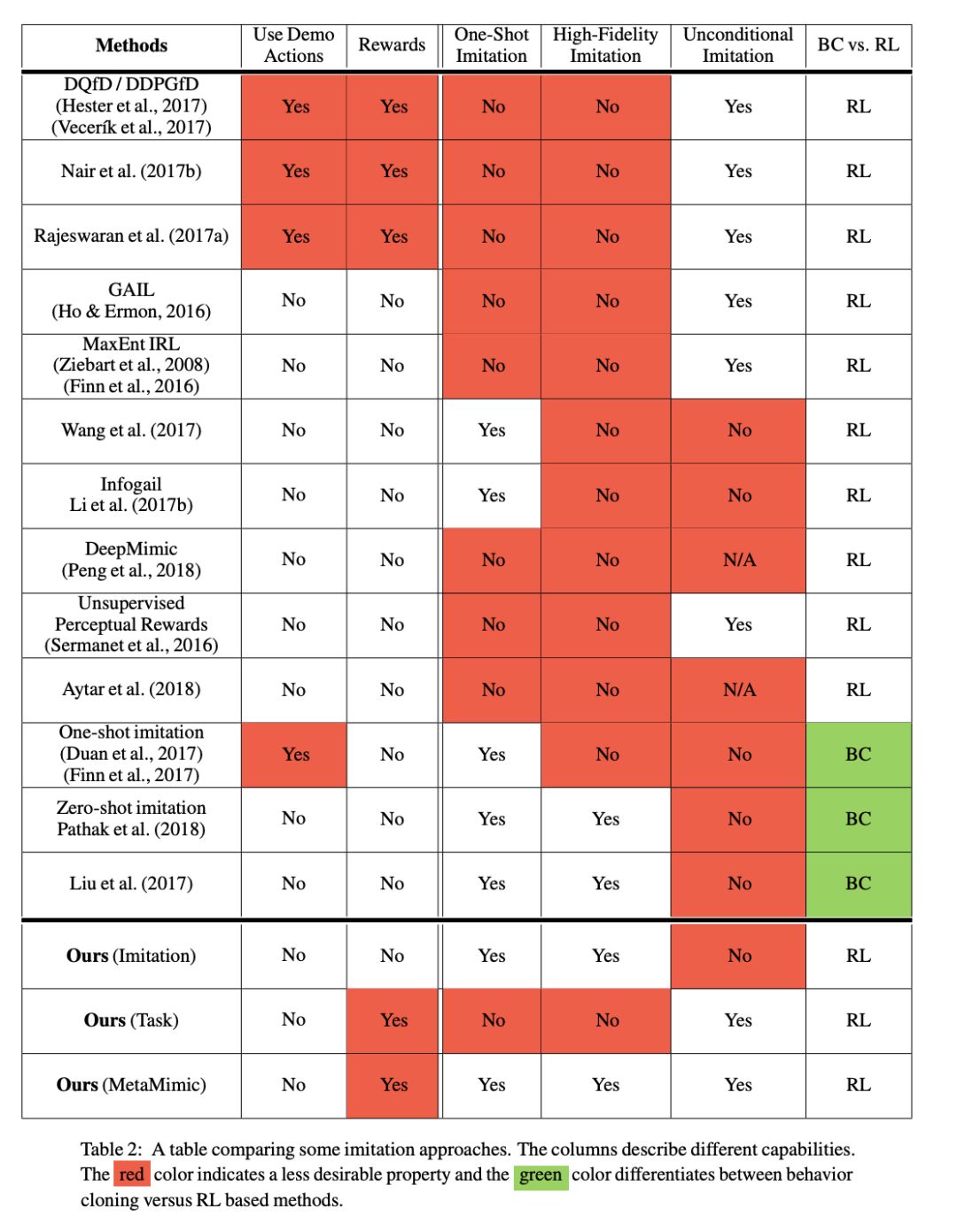
ABSTRACT Humans are experts at high-fidelity imitation – closely mimicking a demonstration, often in one attempt. Humans use this ability to quickly solve a task instance, and to bootstrap learning of new tasks. Achieving these abilities in autonomous agents is an open problem. In this paper, we introduce an off-policy RL algorithm (MetaMimic) to narrow this gap. MetaMimic can learn both (i) policies for high-fidelity one-shot imitation of diverse novel skills, and (ii) policies that enable the agent to solve tasks more efficiently than the demonstrators. MetaMimic relies on the principle of storing all experiences in a memory and replaying these to learn massive deep neural network policies by off-policy RL. This paper introduces, to the best of our knowledge, the largest existing neural networks for deep RL and shows that larger networks with normalization are needed to achieve one-shot high-fidelity imitation on a challenging manipulation task. The results also show that both types of policy can be learned from vision, in spite of the task rewards being sparse, and without access to demonstrator actions.
https://arxiv.org/pdf/1810.05017.pdf