媲美人类有何不可?深度解读微软新 AI 翻译系统四大秘技

3 月 15 日的文章《机器翻译新突破,微软中英新闻翻译达人类水平》中,我们介绍了微软亚洲研究院与雷德蒙研究院共同研发的新的机器翻译系统,微软称它在 newstest2017 的中 - 英测试集上达到了与人工翻译媲美的水平。
这则消息不仅引起了我们的好奇,让我们的编辑记者们感叹「人工智能这么快就又下一城」,同时也引起了一些读者的疑问。毕竟,我们时常见到新模型在公开测试中刷榜,能够和人类拿到同样的分数,但不一定换一个数据集就还能和人类媲美,尤其是对于灵活多变的人类语言而言;另一面,谷歌、搜狗、百度等互联网巨头都有自己神经网络翻译系统,大家都或多或少体验过,即便最新的模型都普遍使用了注意力机制,但翻译质量不尽如人意的地方仍时常出现,继续做出大跨步式的突破又谈何容易呢?
微软官方博客中提到,新的翻译系统中用到了四大技术:对偶学习、联合训练、推敲网络和一致性正则化,对应的论文也已经公开。雷锋网 AI 科技评论下面根据论文,结合以往的相关研究详细讲讲用在新翻译系统中的这四大技术到底是怎么回事,品味品味当这四项技术同时使用的时候,能够达到人类水准到底能不能算是「合情合理」。文末我们也会贴出一些微软提供的中文到英文翻译结果,不知道能否彻底打消可能的疑惑。
一,对偶学习 Dual Learning
深度学习模型的训练需要大量数据,这不仅是领域内的常识,也是限制在更多场景下使用深度学习的一大障碍。对偶学习的提出就主要是为了减少对数据的依赖。相比标签传播(Label Propagation)、多任务学习(Multi-task Learning)、迁移学习(Transfer Learning)这样利用数据相似性的解决方法,对偶学习(Dual Learning)利用的是 AI 任务中自然出现的对称性。比如:
机器翻译,有英翻中和中翻英的对称;
语音处理,需要语音转文字(语音识别),也有文本转语音(语音合成)的任务;
图像理解,图像描述(image captioning)与图像生成 (image generation)是一个对称的过程;
对话任务,问题回答(Question answering)与问题生成(Question generation);
按照传统的监督学习范式,这些对称的任务都需要分别训练,每个方向都需要大量有标签数据。那么考虑到任务的对称性,如果一个英文句子被翻译成英文,再从中文翻译成英文,还能跟一开始的句子非常相近的话,就可以认为「英翻中」和「中翻英」两个翻译器都表现很好。这也符合人们的常识。
微软亚研主管研究员秦涛博士就曾带领团队分别在 NIPS 2016 和 ICML 2017 发表「对偶学习」(https://arxiv.org/abs/1611.00179 )和「对偶监督学习」(https://arxiv.org/abs/1707.00415 )两篇论文,介绍了对偶学习在无监督学习和监督学习两种模式下的形式及表现。雷锋网硬创公开课也曾邀请到秦涛博士给大家做了前一篇 NIPS 论文的详细分享。
对偶学习
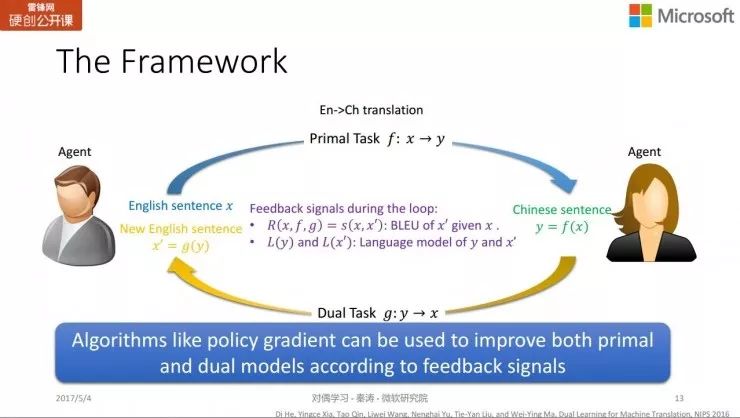
NIPS 2016 对偶学习论文的范式示意图
如图,对于对偶学习,主任务 f 把无标注英文句子 x 翻译为中文 y,对偶任务 g 把中文 y 翻译回英文 x'。模型从过程中得到两个反馈,一个部分反馈是来自懂中文的智能体,评价中文 y 的翻译质量如何;另一个反馈是来自懂英文的智能体,比较 x 和 x' 获得反馈。这样,一个流程结束以后,模型就可以获得完整反馈。
有了反馈,就可以把强化学习的一些方法直接用于训练更新模型 f 和 g 。论文中所用的方法为策略梯度 policy gradient,增加主任务 f 和对偶任务 g 中好的行为出现的概率,降低不好的行为出现的概率。另一方面,由于只有单一输入,由两个智能体自己产生反馈,不需要把翻译结果与输入对应的标签对比,所以这是一种无监督学习方法。
学习效果上,在使用了 1200 万个双语标注句的英法翻译实验中,相比于 2016 年时效果最好的基于深度神经网络的机器翻译算法(NMT),对偶学习只需要其中 10% 的双语数据就可以达到 NMT 采用了全部数据进行训练的准确度。训练所需数据量可以减少 90%,很好地达成了预期效果。
根据秦涛博士介绍,对偶学习有一个问题是很难冷启动,即需要先对主任务和对偶任务的两个智能体进行一定的训练后才能够利用对偶学习进行联合反馈训练,否则模型收敛会很慢。
对偶监督学习
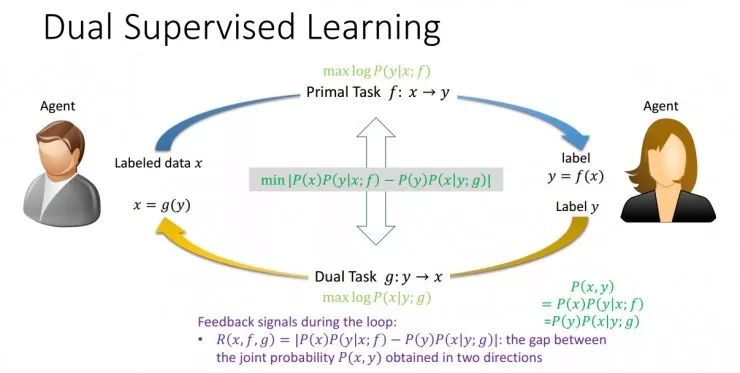
ICML 2017 对偶监督学习论文的范式示意图
仍以翻译任务为例,在监督学习中,当知道主任务 f 应该得到的正确翻译为 y 之后,就可以用最大似然准则更新 f,使 y 出现的概率越大越好。
对于对偶监督学习,需要主任务 f 和对偶任务 g 各自都能出现正确翻译 y 与 x,这样就会存在一个联合概率 P(x,y)。如果 f 与 g 的更新是同步的,通过 f 和 g 都可以单独计算出这个联合概率。但如果 f 和 g 是根据监督学习分开训练的,就不能保证单独计算出的联合概率相同。
为了解决这个问题,论文中在 f 、g 两个任务分别的损失函数基础上,为对偶监督学习增加了一项正则化项,它的含义是将「f 得到正确结果 y」和「g 得到正确结果 x」两个概率的差值最小化,从而通过结构的对称性加强了监督学习过程,让两个互为对称的任务共同进行学习。(上图中间的式子) 这与 SVM 正则化项的区别在于,SVM 的正则化项与模型有关,与数据无关;但对偶监督学习中讨论的正则化项还与数据相关。由于具有了这样的正则化项,每个训练数据都能够参与到正则化项中,而且主任务、对偶任务的两个模型可以互相影响。
根据论文中的测试,对偶监督学习模型在机器翻译、图像分类、句子情感分析三对任务中都取得了明显的提高。尤为让人印象深刻的是句子情感分析这一对任务:判断一个句子是正面还是负面情感,或者根据给定的正面 / 负面情感反向生成句子,任务中的信息损失非常严重,只留下了 1bit 的信息而已。测试结果中情感分析的错误率仅从基准模型的 10.1% 下降到对偶监督学习模型的 9.2%,作者们认为就和信息损失严重有关。
不过到了反向生成句子的时候,对偶监督学习模型展现出了强大的表现力,对简单短句的使用变少了,并且选用的单词、词语、句式表达出的情感更强烈、更具体。如下图
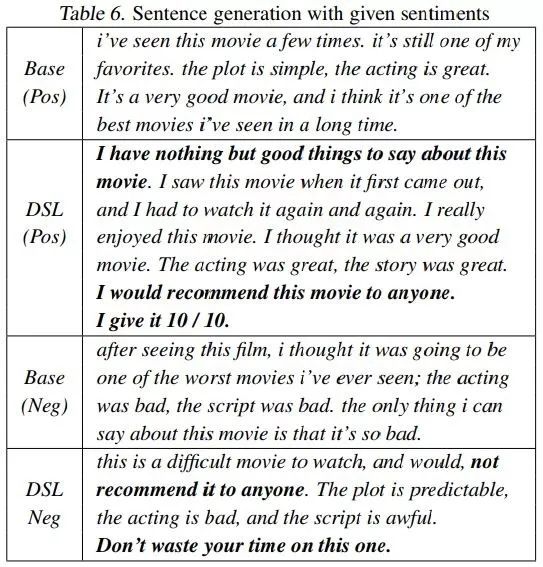
在这次新的机器翻译系统中,基于单语语言语料的对偶学习和基于双语语料的对偶监督学习都有使用,提升了语料的训练成效。
二,联合训练 Joint Training
即便有了对偶学习这样的可以提高数据利用效率的方法,高质量的双语训练数据毕竟还是越多越好 —— 而实际上这样的数据没有那么多。所以论文中还引入了联合训练,让中到英和英到中的两个互译模型生成新的数据,并把新生成的数据也当作训练数据,迭代进行训练。
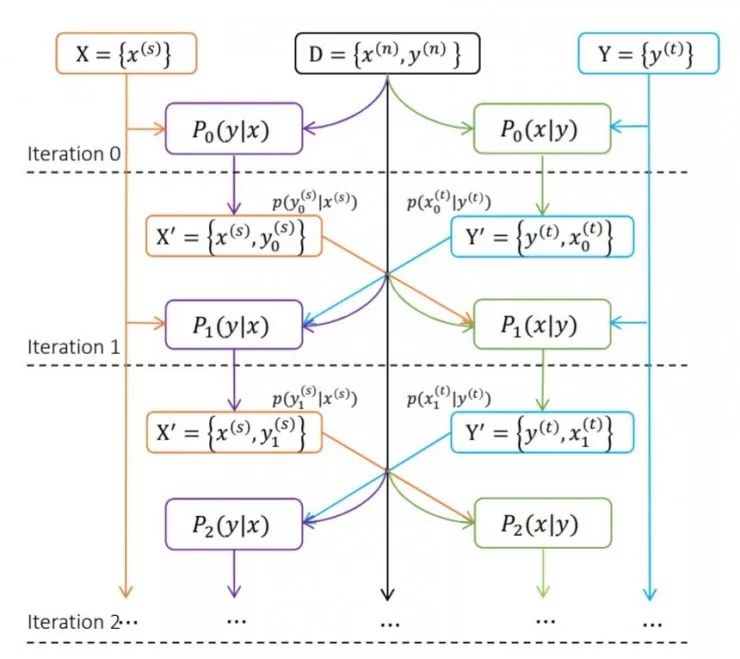
具体做法如图所示,对于现有的双语语料库 D 中的语句对 (X,Y),用预训练过的一对翻译器把 X 翻译为 Y'、把 Y 翻译成 X',构成新的语句对 (X',Y')。在每轮迭代中,新生成的语句对会添加到现有的双语训练数据中,继续训练两个方向的两个模型;经过训练的模型会再一次翻译出新的(X',Y'),作为新的训练数据。同时也设计了半监督的训练损失,同时包含了两个方向模型的表现,以便能让一个模型的进步显式地帮助另一个模型的表现提高。
为了保证新生成的、即将用于下一轮训练的生成语句对的质量,生成的语句也要挑选出最好的一部分,而且选出的语句要经过神经网络翻译模型的翻译概率权重评分,以便最大程度减小不好的翻译语句带来的负面影响。那么,在一轮轮的迭代过程中,两个方向的翻译语句质量会越来越高、模型也被训练得更好,这样的迭代训练过程会进行到表现不能继续提高为止。
三,推敲网络 Deliberation Networks
除了训练数据带来的限制之外,当前的神经网络翻译系统普遍还存在曝光偏倚(exposure bias)的问题。即,在输出结果的序列式生成过程中,早期出现的错误会在后来得到增强,误导序列生成结果。推敲网络就是解决这个问题的第一招。
推敲网络设计
以往的翻译模型都把输入句子作为一个序列输入,然后同样把翻译结果作为一个序列一次性输出。乍看之下不出错的话也没什么不妥,但是相比之下人类写作时经常会对用词反复推敲,甚至写完一整段话、一整篇后再从头调整修改一遍,文本的质量也得以继续提高。在「生成后再修改」的想法下,中国科大 - 微软博士联合培养班的夏应策作为一作在 NIPS 2017 发表了论文 《Deliberation Networks: Sequence Generation Beyond One-Pass Decoding》(http://suo.im/17L13u ),也在 GAIR 大讲堂的线上公开课上详细分享了推敲网络的细节。
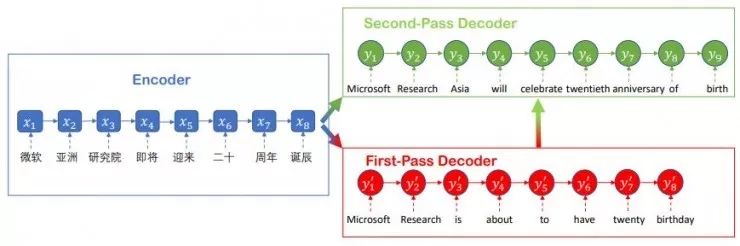
推敲网络的做法梗概是,它在编码器之后使用了如上图所示的两阶段解码器,第一段解码器把来自编码器的源语句嵌入直白地解码成目标语言的草稿语句,然后第二阶段的解码器再次对刚才的草稿句子进行调整美化。
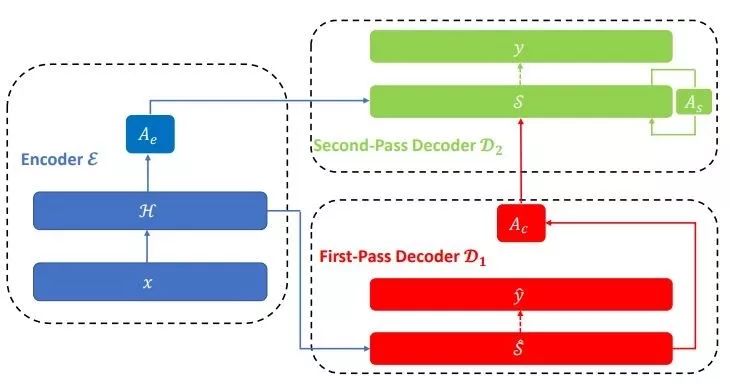
具体来讲,模型架构是在 Transformer 网络架构上增加一个推敲网络。与标准的 Transformer 网络相同,编码器 ε 和第一阶段的解码器 D1 都是多层神经网络,以注意力机制连接起来。在这里,编码器 ε 会基于原始词嵌入和来自词之间顺序的上下文信息为源句的每个词 Ts 生成词表征,这些表征组成序列 H。编码器 ε 读取句子 x 后就可以通过自我注意力输出带有隐含状态的序列 H。
第一阶段的解码器 D1 把 H 作为输入,执行第一阶段的解码,得到 softmax 前的隐含状态 S^ 以及草稿句子 y^。第二阶段的解码器 D2 也是多层神经网络,但和 D1 有很大不同,它会把来自编码器 ε 和解码器 D1 的隐含状态都作为自己的输入。由于 D2 有来自 D1 解码出的隐含状态,所以 D2 的输出是依赖于 D1 生成的草稿句子 y^ 的。这样的做法可以从源语句中获得全局信息,在生成句子时也就有正确的上下文语境信息供使用。
推敲网络和对偶学习的联合使用
对于两种技术如何结合,微软的研究人员们首先通过无监督及监督对偶学习训练中到英和英到中两个 Transformer 翻译模型。然后把英语语料句子 y 通过英到中翻译模型翻译为中文句子 x',并把 (x',y) 这个句对作为伪双语语料,把它加入现有的双语语料库中。扩大后的语料库就可以用来训练上文描述的构建于 Transformer 之上的推敲网络。解码器和第一阶段编码器是使用第一步中训练出的中到英翻译模型初始化的。
四,一致性正则化 Agreement Regularization
一致性正则化是防止曝光偏倚出现的另一个手段。研究员们发现,翻译顺序是从左往右的模型如果生成的句子里词的后缀使用得不好,那么用从右往左的模型预测这个译出的句子时,由于不好的后缀先被输入进编码器,它会导致隐含状态的破坏,得到的翻译结果也会较差。也就是说,好的翻译模型,不仅从左往右顺序翻译得好,它还能对应一个从右往左翻译也能得到好结果的模型。
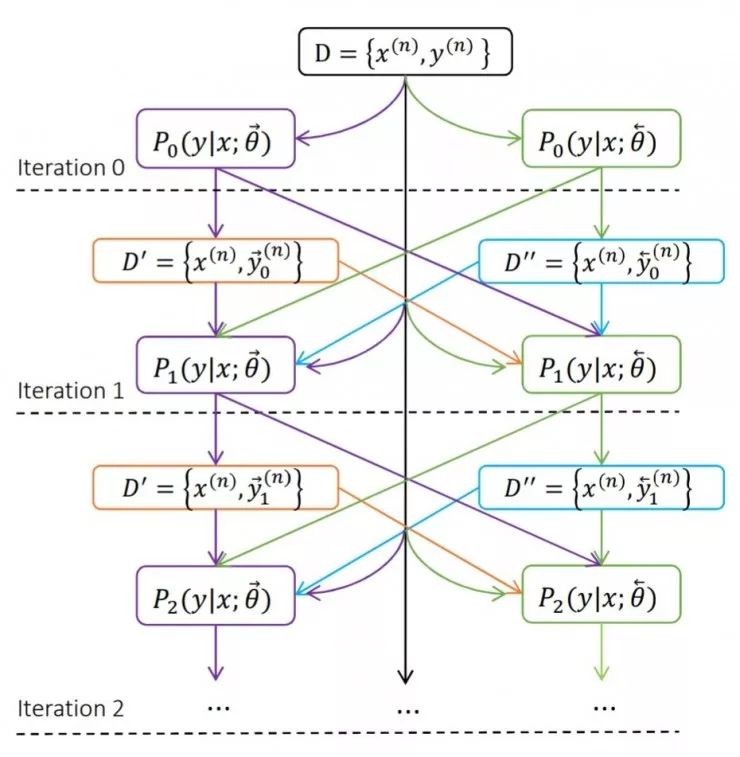
在此处的损失设计中,从左往右翻译的模型的损失包括:第一项,最大化这个模型自己的双语语料翻译的对数似然;第二项,对应的从右往左翻译的模型要生成一个「伪语料」作为中间过程的值,这个伪语料的对数自然也需要最大化;第三项,对比从左往右和从右往左两个模型翻译的句子,如果不一致则有惩罚。在这里,从右往左的模型不是最终需要的模型,但是它也参与训练,作为辅助系统生成伪语料,参与第二项和第三项损失的计算。
和前面的联合训练类似,由于损失项中同时含有两个模型的表现,其中一个模型的表现进步也可以显示地影响另一个模型,也就可以迭代更新进步,如上图所示。
实际上,中译英和英译中两个语言方向的模型,都可以分为从左往右和从右往左两个输入顺序的模型。这就一共有了四个模型,然后这四个模型可以依据一个统一训练框架,一同联合训练。训练过程中首先由从左往右的英到中模型生成中间过程伪语料,在一致性正则化的帮助下用来训练从左往右和从右往左两个中到英模型;接下来,已经经过训练增强的从左往右的中到英模型就会再生成一个伪语料用于训练从左往右和从右往左两个英到中模型。这四个模型互相促进、迭代训练,直到最终收敛。
例句尝鲜
对偶学习、联合训练、推敲网络和一致性正则化四项技术介绍完了,都是一些符合常识的改进,我们上一篇报道中的测试数据也已经展现出了可见的改进。
实际上在测试中,研究员们依据对偶学习 + 推敲网络、一致性正则化 + 联合训练、WMT 数据集 + 更多额外数据等选择,配置了许多种不同的系统,一面通过测试验证了各个改进项目的实际效果,另一面也可以把多个系统的不同结果做综合,得到更好的翻译结果。实际上,论文中声称达到人类翻译水平、BLEU 分数也超过 28 分的结果,就是由包含了 6 到 8 个模型结果的综合模型得到的,最高的一个综合模型有 28.46 分。(作为参考,拿下 WMT 2017 比赛最好结果的搜狗翻译为 26.40 分,论文中的各种单个系统都没有超过 28 分)
根据微软官方博客介绍,这个翻译系统的中到英翻译体验页面已经在 https://translator.microsoft.com/neural/ 上线了,由单个系统提供翻译,这个系统的 BLEU 分数为 27.60 分。页面上同时也直接提供了一些来自微软测试所用的 WMT 2017 newstest 数据集的中文新闻语料供参考。平心而论,这些中文语句还真的不那么简单,有相当的挑战性;也可以自己输入句子尝试。另外页面上也提供了两种不同的翻译供感受。
下面我们摘录三个来自测试集的中文语料,以及两条有难度的其它测试语句,感受一下翻译质量。而且要记得,这还并不是新的翻译系统(综合模型)的全部实力哦。
海口海事法院凌晨立案确保临高渔船沉没事件当事人权益
The early morning of Haikou Maritime Court to ensure the interests of the Lingao fishing boat sinking event
Haikou maritime court filed a case in the early morning to ensure the rights and interests of the parties involved in the sinking of the Lingao fishing boat
人道主义团体却对法院表示这些商店和餐馆极为重要,因为国家支持的协会及其他团体所提供的免费食物根本无法满足该难民营不断增长的难民的需求。
The humanitarian community has told the court that these shops and restaurants are extremely important, as free food provided by state-sponsored associations and other groups cannot meet the growing needs of refugees in the refugee camp.
Humanitarian groups, however, told the court that the shops and restaurants were extremely important because the free food provided by State-sponsored associations and other groups simply could not meet the growing needs of the refugees in the camp.
据媒体披露,由于此前资本大规模涌入互联网医药,造成目前产品同质化的问题严重,投资热潮渐退,资本进入观望期。
According to media disclosure, due to the previous massive influx of capital into the Internet medicine, resulting in the current serious problem of product homogenization, investment boom gradually receded, capital into the wait-and-see period.
According to media disclosure, due to the massive influx of capital before the Internet medicine, resulting in the current problem of homogenization of products, investment boom is receding, the capital into the wait-and-see period.
宝宝的经纪人睡了宝宝的宝宝,现在宝宝不知道宝宝的宝宝是不是宝宝亲生的宝宝
The baby's agent slept with the baby's baby and now the baby doesn't know if the baby's baby is the baby's biological baby
Baby's agent Sleeps baby's baby, now baby doesn't know baby's baby is not baby's baby
走廊灯关上,书包放,走到房间窗外望,回想刚买的书,一本名叫半岛铁盒
Corridor lights off, school bags put, went to look out the window of the room, recalled just bought a book, called the Peninsula Iron Box
The corridor light closes, the bag puts, walks to the room window looks, recalls just bought the book, a name Peninsula iron box
对于页面一次给出两种翻译,并且希望用户选出其中更满意的一个,我们认为微软还在尝试用更多语料以及加上更多人阅读的直观反馈,继续改进这个翻译系统。其它值得期待的改进点还包括语料较少的领域的双语翻译、系统的运行速度、如何把多个子系统融合成表现相当的一整个模型等。
以及我们也希望微软可以早日开放英文到中文的翻译体验,在测试阶段供大家更多感受新翻译系统的魅力。要是能成为生产级别的翻译系统正式开放,那就最好了。
翻译系统测试地址:https://translator.microsoft.com/neural/
论文地址:https://www.microsoft.com/en-us/research/uploads/prod/2018/03/final-achieving-human.pdf。
AI 研习社报道。

限时拼团
3 大模块,30 个课时
高校数学系教授带班
100% 学员好评
与 100 + 同学一起夯实数学基础,走稳机器学习入门第一步!
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
用 Keras 实现的神经网络机器翻译
▼▼▼