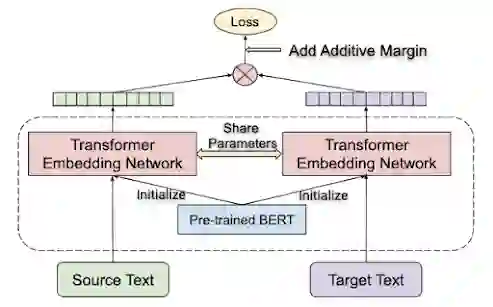
![]()
来源:Google
编辑:雅新
【新智元导读】谷歌研究人员提出了一种LaBSE的多语言BERT嵌入模型。该模型可为109种语言生成与语言无关的跨语言句子嵌入,同时在跨语言文本检索性能优于LASER。
近日,谷歌AI研究人员提出了一种称为LaBSE的多语言BERT嵌入模型,
该模型可为109种语言生成与语言无关的跨语言句子嵌入。
这一论文题目为「Language-agnostic BERT Sentence Embedding」,目前已在arxiv上发表。
论文地址:
https://arxiv.org/pdf/2007.01852.pdf
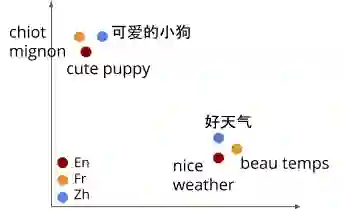
多语言嵌入模型是一种功能强大的工具,可将不同语言的文本编码到共享的嵌入空间中,从而使其能够应用在一系列下游任务,比如文本分类、文本聚类等,同时它还利用语义信息来理解语言。
用于生成此类嵌入的现有方法如LASER或m~USE依赖并行数据,将句子从一种语言直接映射到另一种语言,鼓励句子嵌入之间的一致性。
尽管这些现有的多语言嵌入方法可在多种语言中有良好的整体性能,但与专用双语模型相比,它们在高资源语言上通常表现不佳。
此外,由于有限的模型容量、低资源语言的训练数据质量通常较差,可能难以扩展多语言模型以支持更多语言,同时保持良好的性能。
改善语言模型的最新研究包括开发掩码语言模型(MLM)预训练,如BERT,ALBER和RoBERTa使用的预训练。由于这种方法仅需要一种语言的文字,因此在多种语言和各种自然语言处理任务中均取得了非凡的成就。
另外,MLM预训练已经扩展到多种语言,通过将MLM预训练修改为包括级联翻译对,也称作翻译语言模型(TLM),或者仅引入来自多种语言的预训练数据。
但是,尽管在进行MLM和TLM训练时学习到的内部模型表示形式对下游任务进行微调很有帮助,但它们不能直接产生句子嵌入,而这对于翻译任务至关重要。
在这样情况下,研究人员提出了一种称为LaBSE的多语言BERT嵌入模型。
该模型使用MLM和TLM预训练在170亿个单语句子和60亿个双语句子对上进行了训练,即使在训练期间没有可用数据的低资源语言上也有效。
此外,该模型在多个并行文本检索任务上有表现出良好的性能。
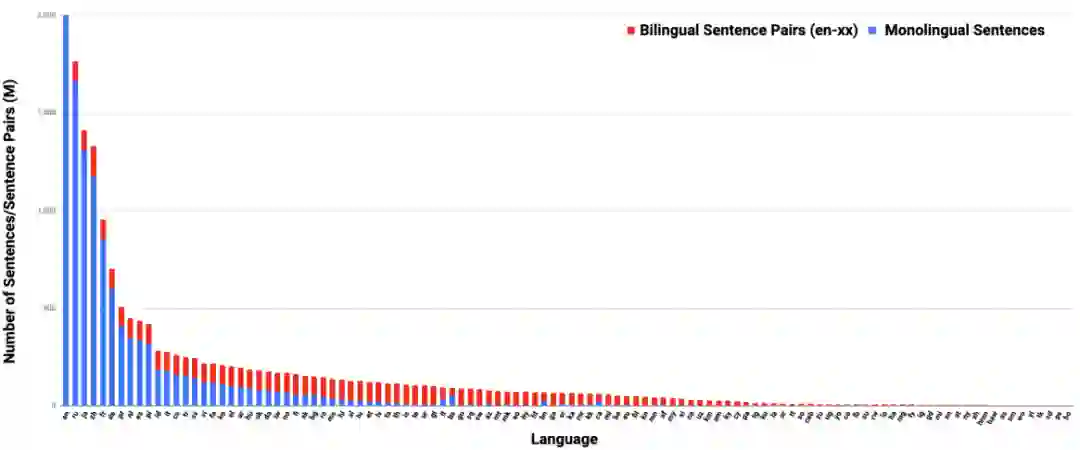
![]() 收集109种支持语言的训练数据
收集109种支持语言的训练数据
LaBSE模型可在单个模型中提供了对109种语言的扩展支持
在先前的工作中,研究者曾建议使用翻译排名任务来学习多语言句子嵌入空间。该方法通过给定源语言中的句子,对模型进行排序,从而对目标语言中的句子的正确翻译进行排名。
翻译排名任务通过使用带有共享变压器的双编码器体系结构进行训练的,让双语模型在多项并行文本检索任务表现出最先进的性能。
但是,由于模型能力、词汇量覆盖范围、训练数据质量等方面的限制,将双语模型扩展为支持多种语言(在研究者的测试案例中为16种语言)时,模型表现并不优。
对于LaBSE,研究人员在类似BERT的体系结构上利用了语言模型预训练的最新成果,包括MLM和TLM,并在翻译排名任务上进行了微调。
使用MLM和TLM在109种语言上预先训练的500k令牌词汇表的12层转换器,用于增加模型和词汇表覆盖范围。
最终,LaBSE模型在单个模型中提供了对109种语言的扩展支持。
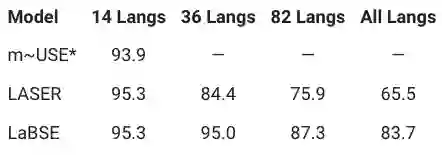
LaBSE模型在跨语言文本检索的性能优于LASER
研究者使用Tatoeba语料库评估提出的模型,Tatoeba语料库是一个数据集,包含多达112个语言的1000个英语对齐的句子对。
对于数据集中30种以上的语言,该模型没有训练数据。该模型的任务是查找给定句子的最近相邻的翻译,并使用余弦距离进行计算。
为了了解训练数据分布的开头或结尾处的语言模型的性能,研究人员将语言集分为几组,并计算每组语言的平均准确性。
下表列出了与每种语言组的m〜USE、LASER以及LaBSE模型实现的平均准确性对比结果。
可以看出,所有模型在涵盖大多数主要语言的14语言组中均表现出色。当涵盖的语言增多,LASER和LaBSE的平均准确度都会下降。
但是,
随着语言数量的增加,LaBSE模型的准确性降低的要小得多,明显优于LASER
,尤其是当包括112种语言的全部分发时,LaBSE准确性为83.7%,LASER为65.5%。
此外,LaBSE还可用于从Web规模数据中挖掘并行文本。
谷歌研究人员已经通过tfhub向社区发布了预先训练的模型,其中包括可以按原样使用或可以使用特定于域的数据进行微调的模块。
链接:https://tfhub.dev/google/LaBSE/1
参考链接:
https://ai.googleblog.com/


 收集109种支持语言的训练数据
收集109种支持语言的训练数据