机器学习-我妈妈也能看懂的入门篇

内容导读
机器学习打开了一个新世界的大门,我们不需告诉机器如何做,只需要给大量样本,它就能自动从中发掘规律, 这也是一个哲学问题,改变人类思考问题的方式,将关注点从数学科学转移到自然科学上,观察不确定的未知世界,用统计信息而非逻辑来分析实验结果 。下图简单的解释了TensorFlow的工作原理,它就象我妈用的压面机一样,把和好的面团塞进去,搅拌几下,可以挤压出不同形状的面条: 刀削面,挂面等,粗细宽窄随人。再写一行代码看看数据结构print(image.shape)得到输出结果是(512, 512, 3), 这就是一个3阶张量啊,说明这个图片的高和宽都是512像素,有三个颜色通道。最后写一行代码看看数据结构的长度print(image.size)打印结果是786432,等于512x512x3, 多阶数据扁平化以后TensorFlow才能线性的使用它。也就是说,机器要通过训练集数据调参优化,overall_score的计算公式里那些权重值都是我拍脑袋定出来的,一定不是最优组合,机器需要发现规律找到最合理的权重设置对未来的目标榴莲做出最精准的预测。偏差值允许分类器代表的直线左右平移(右图),它影响输出,但并不和原始数据产生关联。
前面几篇文章可以算作是机器学习中计算机视觉处理的范畴但并未真正涉及到学习二字,现在开始准备写一系列真正的学习相关的文章,还是主要和图片识别相关,包括这个入门篇,手写数字识别,时尚商品识别,鱼类甚至是细分鱼的品种的识别。
写这篇文章也希望让我妈也能看懂机器学习,所以力求从不同视角用大白话把这件事说清楚,文中也会尽量避免出现数学公式,如果我妈都能看懂,那么非技术人员也就能看懂。正如一篇近日刷屏的文章提到那样,真正的AI并未实现,现在无非是在做一些比较高效的统计概率分析工作而已,但是这已经足够对各行各业带来深远影响,前提是非技术人员也能明白机器学习是怎么回事,它能做什么,能给业务场景创造什么样的价值。
机器学习打开了一个新世界的大门,我们不需告诉机器如何做,只需要给大量样本,它就能自动从中发掘规律,这也是一个哲学问题,改变人类思考问题的方式,将关注点从数学科学转移到自然科学上,观察不确定的未知世界,用统计信息而非逻辑来分析实验结果。
因为后续文章会用到TensorFlow来计算,所以这里先提一下。Google开源的TensofFlow是目前最流行的深度学习框架,在计算机视觉,音频处理,自然语言处理,推荐系统等场景下都有广泛应用,虽然深度学习框架有很多选择,但我相信选择最主流的框架是最安全的。
TensorFlow 按照字面理解就是张量(Tensor)流(Flow), 表示通过张量的流动来表达计算。下图简单的解释了TensorFlow的工作原理,它就象我妈用的压面机一样,把和好的面团塞进去,搅拌几下,可以挤压出不同形状的面条: 刀削面,挂面等,粗细宽窄随人。TensorFlow 的内核是数据流图(Data Flow Graphs), 所有的变量和计算都是存储在这个图上,构建完这张图后,打开一个会话(Session)就可以运行整张图了。

Tensor到底是什么?
首先要明白什么是张量(Tensor)。这个名词起源于力学,它最初是用来表示弹性介质中各点应力状态的,爱因斯坦的广义相对论就是用张量语言来表述的,后来张量也成为了数学的一个重要分支学科。解释张量之前,我们再看几个名词: 标量(Scalar), 向量(Vector)和矩阵(Matrix), 用我妈可以看懂的语言来描述,标量是点(即0阶张量),向量是线(即1阶张量),矩阵是平面(即2阶张量),不仅于此,张量还可以有无穷多阶的形式存在,3阶张量就想象成三维空间吧,N阶张量自然就是N维空间了。
之所以引入张量,是因为这是让机器理解世间万物的基础,任何物体用机器的语言描述都是多维的特征向量,为了形象的说明这个道理我们还是拿Playboy美女Lena图片来做分析。

写两行代码打开图片直接打印出来
import cv2
image = cv2.imread('C:/dev/lena_std.jpg')
print(image)

原来在机器的理解中,这张图片就是一大堆的数字的张量形式表达。每行有三个数字代码的是每个像素点的颜色,RGB(红绿蓝)三种颜色。
再写一行代码看看数据结构
print(image.shape)
得到输出结果是(512, 512, 3), 这就是一个3阶张量啊,说明这个图片的高和宽都是512像素,有三个颜色通道。如果是黑白图片的话只有一个颜色通道,那么用2阶张量来描述即可。如果有多张彩色图片则可以用4阶张量来描述,加多一个图片编号的维度即可。
最后写一行代码看看数据结构的长度
print(image.size)
打印结果是786432,等于512x512x3, 多阶数据扁平化以后TensorFlow才能线性的使用它。
机器到底是怎么学习的?
现在已经了解一个对象如何用数字化呈现让机器可以理解和计算,可是到底机器学习是怎么个学习法? 如何让机器能够通过自我学习判断一张图片是猫还是狗呢? 简单来说就是通过已知数据预测未来,我买榴莲比较多,买多了自然就有经验什么样的榴莲好吃。

要挑选榴莲第一个关心的问题是熟了没有,不能买生榴莲也不能买熟过头的,所以先看开裂情况,要找开裂了一点点但裂口不能太大的,然后闻一闻气味是否诱人,如果有发酵的味道就是熟过头了。还可以捏一下尖刺,如果捏不动就是太生。
第二个问题是果肉多不多,主要看形状,挑比较浑圆的可能肉包多一些。
第三个问题是肉质,挑果肉小的,颜色黄的,不能有水分。也可以听声辨认,狠狠地拍下果壳,邦邦声的就好吃,哼哼声的就不好。当然了,挑选的时候带好创可贴。
有了这些经验以后我就能预测一个榴莲是否好吃,不是百分百准确但是概率比较高,如果要让机器学会挑选榴莲就要把我的经验用机器能够理解的语言传递给机器。因此我定义了三个评估指标,还定义了决定每个评估指标的关键因子。
成熟度: (裂口[无/小/大],气味[无/香/发酵],硬度[软/硬/适中])
饱满度: (形状[浑圆/长条/异形])
肉质: (颜色[黄/白],肉包大小[大/中/小], 声音[邦邦/哼哼],湿度[干燥/多水])
根据这些规则机器要对水果店里的所有榴莲扫描一次收集全部数据,通过计算得到一个量化分值,对榴莲品质的好坏进行预测,分值越高的好吃的概率就越高。三个评估指标对于判断一个榴莲好坏的影响力有大有效小,如果我觉得肉质最重要,成熟度其次,饱满度最次,那么大概会有一个类似这样的公式:
overall_score = 成熟度 * 0.3 + 饱满度 * 0.2 + 肉质 * 0.5
这里我假设了几个权重值,因为肉质最重要因此权重最高,所有权重值的总和为1
同样对于成熟度这个评估指标而言,关键因子也有主次之分,可能味道最靠谱,其次看裂口,最后看硬度,那么成熟度的分值大概也有个公式:
maturity_score = 气味 * 0.6 + 裂口 * 0.2 + 硬度 * 0.1
饱满度和肉质的计算也类似,都代入overall_score的计算就是完整的公式。
overall_score = (味道 * 0.6 + 裂口 * 0.2 + 硬度 * 0.1) * 0.3 + (形状 * 1) * 0.2 + (颜色 * 0.3 + 肉包大小 * 0.2 + 声音 * 0.2 + 湿度 * 0.3) * 0.5
这个公式就是用来预测榴莲好坏的模型,我以前购买过的榴莲所拥有的数据就是训练集,未来要预测的榴莲数据就是测试集,训练集数量越多代表经验越丰富,预测也越准确。假设我以前购买过100个榴莲,现在给它们编号生成100条记录,包括所有特征向量,还有我对这些榴莲好坏的一个经验评估分(好榴莲3分,普通榴莲2分,差榴莲1分),也就是我把榴莲的好坏分成三个档次,把这个问题转化成了一个分类问题。
这个表格里有些字段属性可能空缺,比如榴莲没有裂口的话很可能就闻不到气味,看不到果肉颜色,更无从观察果肉的湿度。你可能也会注意到有的特征维度是冗余的,即从其它特征维度能推导出这些维度的属性,比如裂口大则果壳肯定是软的,那么有可能这个冗余特征是一个无效因子。
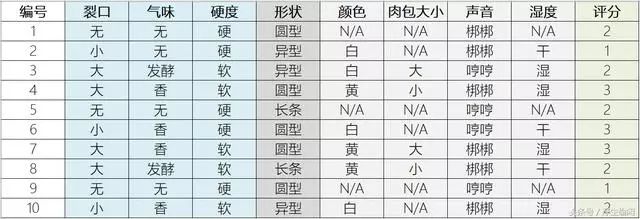
注意上表中所有特征向量的属性值在实际计算的时候也都会用数字来量化,比如形状(圆型=1,长条=2, 异形=3)
不过先等一等,如果就用上面这个固定规律来计算榴莲好坏算什么机器学习,所谓机器学习是要通过训练集的数据对公式的参数不断进行调整以求最大化逼近目标。也就是说,机器要通过训练集数据调参优化,overall_score的计算公式里那些权重值都是我拍脑袋定出来的,一定不是最优组合,机器需要发现规律找到最合理的权重设置对未来的目标榴莲做出最精准的预测。
前面写了这么多废话才引入下面的机器学习第一公式,也是机器学习中最常见的公式,实际上就是线性分类函数(linear classifier),训练分类器的目标就是求出(w,b)。
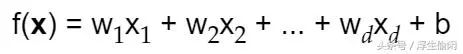
d个特征因子
一般用向量形式表达简化为
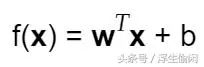
向量形式
w就是前面提到的权重设置的d维向量,b是bias, 即一个偏差值。为什么还需要这个偏差值呢? 如果没有偏差值,无论权重如何,在x=0时分类分值始终为0。这样所有分类器的直线都不得不穿过原点(左图),这显然不合理,实际上绝大多数情况下这条线肯定不过原点。偏差值允许分类器代表的直线左右平移(右图),它影响输出,但并不和原始数据产生关联。在右图中,w就是直线的斜率,而b则是直线的位移。
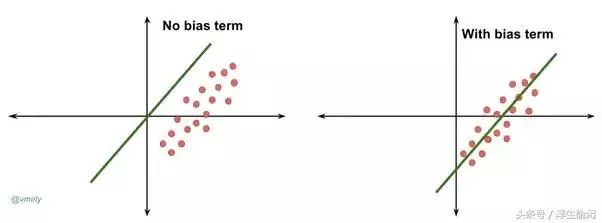
with and without bias
线性分类器主要由两个部分组成:
一个是评分函数(score function),它是一个从原始图像到类别分值的映射函数,就是我计算榴莲overall_score的那个函数。另一个是损失函数(loss function),它是用来量化预测得到的分类标签的得分与真实标签之间的一致性, 评估算法的好坏,损失函数越小则预测结果越准。所以线性分类器可以转化成为一个最优化问题,在最优化过程中,通过更新score function的参数来最小化loss function。上面的右图中,所有红点到直线的距离之和就是损失函数的误差。我们的目标不是缩小某一个点和直线间的最大误差,而是所有点和直线间的误差最小,因此引入了方差的评估方式,即数据集上的L2损失。
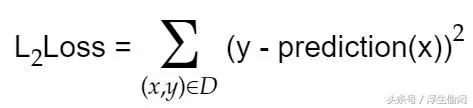
将方差值除以样本的数量就可以得到均方差,也就是以前的文章中用来对比图像的指标MSE
下面两张图中,左边更符合预期,但是如果简单的计算所有点到直线的距离之和就变成右边损失更小,如果用方差来评估会发现左边更优。
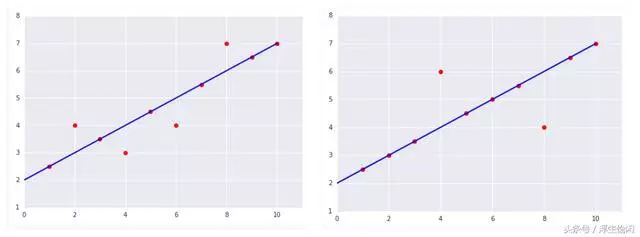
损失函数评估
用我妈能看懂的话来说,要让机器找到最准确的规律,判断一个好的榴莲到底是看熟不熟更重要,还是看果肉多不多重要,或者是看肉质好坏重要,三者之中的权重到底如何设定最佳,判断熟不熟到底是观察裂口靠谱还是闻味道或者试硬度靠谱,这几个特征的权重又该如何设置最好。当然了,我妈定义好榴莲的标准和我可能不一样,她也可以自己对过往的榴莲数据做标注打上分数,重新训练数据再去预测出符合她预期的结果。
用官话来总结,我定义了一个监督式机器学习的任务,因为规则是我提供的,标注也是我提供的。同时我已经生成了一个有标注的样本,包含一百条历史购买榴莲的数据信息,其中既有榴莲的特征(气味,硬度,颜色等),也有榴莲品质的标注(1到3分)。我希望通过一个评分函数的模型定义了特征和标注之间的关系,让机器逐渐学习和发现特征与标注的关系完善模型,这是机器学习的核心。最终目标是对未来要购买的榴莲进行预测,找到最优的权重和偏差组合,让预测结果尽可能逼近真相。也就是让预测的分值和我人工判断的分值,也就是让损失函数最小化, 损失函数的评估是L2方差。如果我预测榴莲是需要分为三种离散值(好/普通/差),这就是一个分类模型,如果我预测榴莲需要给出连续的分值(10分最高,0分最低,允许小数),这就是一个回归模型。
最后说一下机器如何逼近真相将损失降到最低,先想想猜数字游戏,让朋友想一个1到100的数字不要说出来,我们去猜这个数字的时候可能会用二分法,先问这个数字是否小于50,小于50的话是否小于25,大于50的话是否大于75,就这么经过几次迭代离答案越来越近。机器也是这么多次迭代找到答案的,关键点在于如何高效的找到答案,尤其是当我们有几十万数百万数据集的时候。
回归问题可以映射到下图中的曲线函数找最低点问题,最低点就是损失函数最小的解。通过计算整个数据集中 w 每个可能值的损失函数来找到收敛点这种方法效率太低,所以通过梯度下降法来逼近,梯度具备两个特征: 方向和大小,即往哪个方向移动,每次移动的步长有多大。步长太小迭代速度慢,步长过大则可能冲过头了。所以要看梯度的倾斜度来决定,如果梯度斜率很大,下降的很快,就缩小步长,否则可以放心使用较大的步长。
虽然样本数可能非常多但是其中有很多冗余样本,所以拿样本的子集来回归可以加快学习速度,一个折中的方案是采取小批量随机梯度下降法(SGD)来回归, 每次迭代只抽样拿少量样本(10-1000)
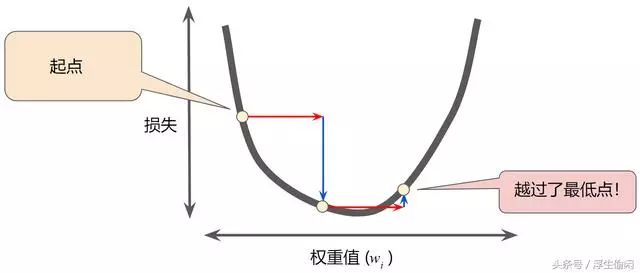
梯度下降
Reference:
1. Google 十几天前新出的 Machine Learning Crash Course
2. 香港科技大学TensorFlow课件
来源:今日头条号(浮生偷闲)







