prompt你到底行不行?

文 | 马杀鸡三明治
源 | 知乎
很久之前老板下任务要试试prompt这个大风,但是玩完后发现太菜了所以连文章都没写,刚好今天工作比较闲就来写写了。
先上结论,连续prompt为运用大模型提供了一种思路,其实这种思路早就见过不少了。。。
离散prompt才是最佳的姿势,但是存在人工设计模板带来变数的问题。
所以prompt真的不太行。
不想看细节的可以直接看总结。
prompt三阶段为:
-
第一阶段, 离散prompt -
第二阶段,连续prompt -
第三阶段,pretrain阶段和下游阶段统一任务类型(T5,zeroprompt)
这里的第三阶段是个人看法。
为什么要prompt
prompt本意在于下游任务使用模型的时候,尽可能与预训练模型pretrain阶段的任务保持一致。
我们现在用BERT的方式大多数为finetune,这会有以下两点弊端:
1.finetune存在上下游阶段任务不一致的问题,fintune对BERT原来的结构破坏严重
2.下游任务通过标注数据驱动,finetune到一个位置,而finetune任务语言上的意义并没有告知给模型。
我们看这两个弊端,本质上我们是在做出选择,是精确的finetune还是泛化能力很强的MLM。
针对这两点弊端做出改进,主要就是pretrain阶段和下游任务阶段能尽可能一致,这样才能发挥出MLM的能力。但是这个过程必定有人为因素,这个过程也就是第一阶段的离散prompt:
第一步,构造prompt。
第二步,构造MAKS token映射。
为此衍生出autoprompt,soft prompt,连续prompt等方法,
接下来我们具体聊聊这两个劣势。
1.finetune存在上下游阶段任务不一致的问题,fintune对BERT原来的结构破坏严重
看第一点,pretrain阶段学习最主要的任务是MLM,那么我们下游使用能否也是用MLM?这就是prompt最开始的思路。问题在于怎么让下游变成MLM任务。
如任务情感分类,x = 我很累 y=负面
第一步,构造prompt
那么我们可以这样加入prompt,prompt = 我感觉很[MASK]
于是可以得到给BERT的token为
[CLS]我很累,感觉很[MASK][SEP]
第二步,构造MAKS token映射
即MASK预测的token应该怎么样映射到标签,比如负面可能的token候选有:难受,坏,烦
这样我们就能让上下游一致了。
2.finetune任务语言上的意义并没有告知给模型
我们知道BERT是一个语言模型,但是finetune却让他数据驱动参数变化,而不是先跟他表明这个任务是干嘛。所以你会发现prompt就是在使用语言的通顺,因为pretrain阶段的语料也是通顺的语料,所以我们构建prompt希望句子X和prompt接起来是一个通顺的话,这样上下游就更一致了。
为了让拼起来的话通顺,我们就会结合场景设计prompt比如上面那个案例使用的prompt=感觉很[MASK],当然也可以promp=心情很[MASK]。
有了上面的思路prompt按阶段开始变种,第一阶段是离散prompt,后来出现连续prompt。
第一阶段,离散prompt
Pattern-Exploiting Training
其实就是我们最开始说的prompt方法,
第一步,构造prompt
那么我们可以这样加入prompt,prompt = 我感觉很[MASK]
于是可以得到给BERT的token为
[CLS]我很累,感觉很[MASK][SEP]
第二步,构造MAKS token映射
即MASK预测的token应该怎么样映射到标签,比如负面可能的token候选有:难受,坏,烦
但是这里面两步都涉及人为因素。所以有人做出了改进,自然是围绕如何去除人工设计,也就是“构造prompt”,“MAKS token映射”。
其实在我看来这才是prompt的优势所在,但是这个优势又带来了劣势,因为有人实验发现prompt的几个字都能导致模型效果的较大的变化。
AutoPrompt
为了去除人工设计带来的变数,autoprompt针对自动“构造prompt”,自动选择“MAKS token映射”,做出方案。
第一步,构造prompt
选择loss下降最大的prompt token,注意到这里的loss怎么计算呢,这一步我们要先给定mask映射词。
这两步骤其实有冲突,先有鸡还是先有蛋。。。论文的做法是先用假的prompt喂进去求出mask映射,也就是:
[CLS] {sentence} [T] [T] [T] [MASK]. [SEP]
然后再用得到的mask映射用数据驱动选择T。
第二步,构造MAKS token映射
step1,使用上下文的MASK token的output embedding作为x,与label训练一个logistic,可以理解为logistic得分高的向量他就更能表示label
step2,使用上下文MASK token的output token的embdding给打分函数,取得分top-k
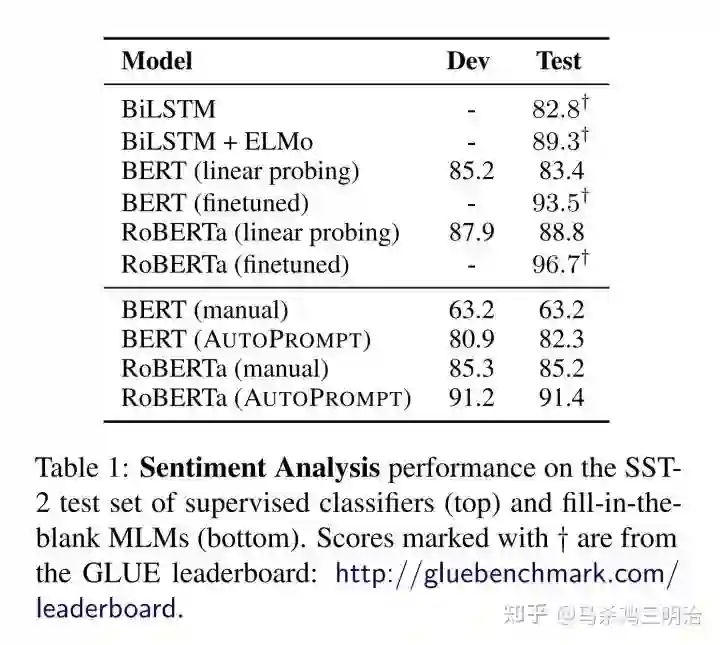
太多细节可以看论文,这个方法和finetune差距也有10个点的出入,注意到这里的roberta是large的,效果比base的BERT好,原因就是因为large的mlm能力更强,在做MRC任务也知道tiny和base的差距还有base和large的差距。模型参数量越大MLM能力越强。
第二阶段,连续prompt
这个阶段prompt开始变味道了,基本思路就是把之前离散的prompt token换成连续的prompt token,怎么换呢。
之前离散prompt的是以token喂给bert的,比如前面那个情感分类的prompt=“我感觉[MASK]”,是以token为单位给bert的,那连续prompt就是把这些token替换成embedding,直接把通过了bert emebdding层的prompt token的向量替换成可训练参数,并且冻结整个BERT,只训练3*768这个矩阵。比如我这里token emebdding维度为3*768(我感觉,三个字)那么可训练参数就是3*768,就是这么回事,那具体还有些骚操作可以玩:
1,比如这里的3*768,那能不能20*768呢,这个也是个不可控的东西可以做实验。
2,能不能给BERT每层encoder整上3*768呢,意味着每层的encoder通过self attention把每层的3*768的信息交互进模型。
3,可不可以不用[MASK]映射了,我直接使用CLS来分类。
以上讲的3点都是P-tuning v2的做法,至于P-tuning v2之前的玩法就不多说了,花样没有P-tuning v2多,但是P-tuning v2的效果在large模型上是接近finetune的,而且你不需要训练太多参数就可以撬动一些大模型了,包括Prefix-tuning也说了他们不需要训练太多参数就可以撬动一些大模型了,但是这个玩法不是早就有了吗,现在打着prompt的旗号又能水是吧。
此外,P-tuning v2中,prompt token长度对实验的影响还挺大的,而且跟任务具有一定相关性,表现很不稳定。论文也没做few-shot实验,效果待定。没有说base模型的效果。
其实看到这里你会发现prompt已经变味了,严格来说根本不是什么prompt了,这种构建可训练向量去控制模型的方法也不稀奇,而去除 [MASK]映射换成CLS来分类就更加有fintune那感觉了。由于我没自己去跑跑,但是可以看到都是负面评论居多,太多负面评价了,不列举了。

第三阶段,pretrain阶段和下游阶段统一任务类型(T5,zeroprompt)
最后一提T5和zeroprompt。
T5是google使用ender-decoder结构做的一个大模型,T5把pretrain阶段任务和下游阶段任务统一了,都做seq2seq任务,或者论文里说的text2text任务。
而zeroprompt,把各种场景和不同的任务类型(分类,翻译,阅读理解,近似句得分等)数据,以人工设计prompt的方式训练,得到一个超级无敌prompt模型,其实本质上也是统一了pretrain阶段任务和下游阶段任务,都做MLM,不同的是zeroprompt为了适应新的任务场景需要一套算法来自动prompt,而T5通过固定引导词配对任务类型,直接decode出答案。
对比两者,T5直接重新设计pretrain阶段任务,和下游阶段任务保持一致,而zeroprompt本质上也是用了自动prompt的方法,但是把中文任务数据都跑了个遍,达到了中文prompt一统。
总结
prompt从最开始的人工设计模板,到自动prompt再到连续prompt,逐渐变的畸形。
最开始的人工设计模板就是为了利用好BERT的pretrain阶段学习到的MLM能力然后用在下游,但是人工设计模型存在不稳定的问题,自动prompt效果又很差。
于是连续prompt开始表演,连续prompt已经没有prompt的味道了,把prompt弄成向量,通过训练希望模型能自己得到好的prompt向量,其实就是在finetune。
所以prompt行不行,目前来看不如finetune。但是他具有一定的few shot能力,特别是离散prompt。在一些简单的任务是可以直接用离散prompt的方式做到few shot,这其实是利用BERT在pretrain阶段学习到的能力,但是一旦任务过难,那few shot效果会很差,远不如标几条数据finetune一下。这里就是涉及到泛化和精准,你想要一定的泛化性,那就一定牺牲了精准。
最后zeroprompt和T5,基本是把prompt的东西都玩完了,其实就是pretrain阶段和下游阶段是否一致的问题。
后台回复关键词【入群】
加入卖萌屋NLP、CV与搜推广求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【
后台回复关键词【