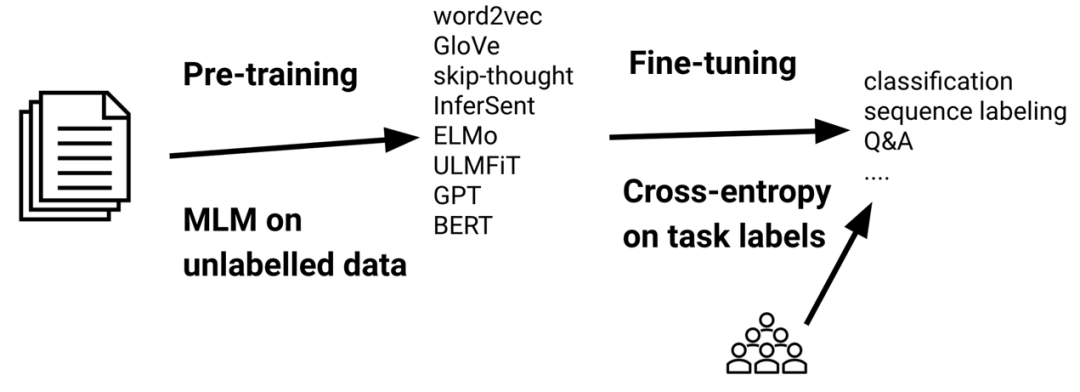
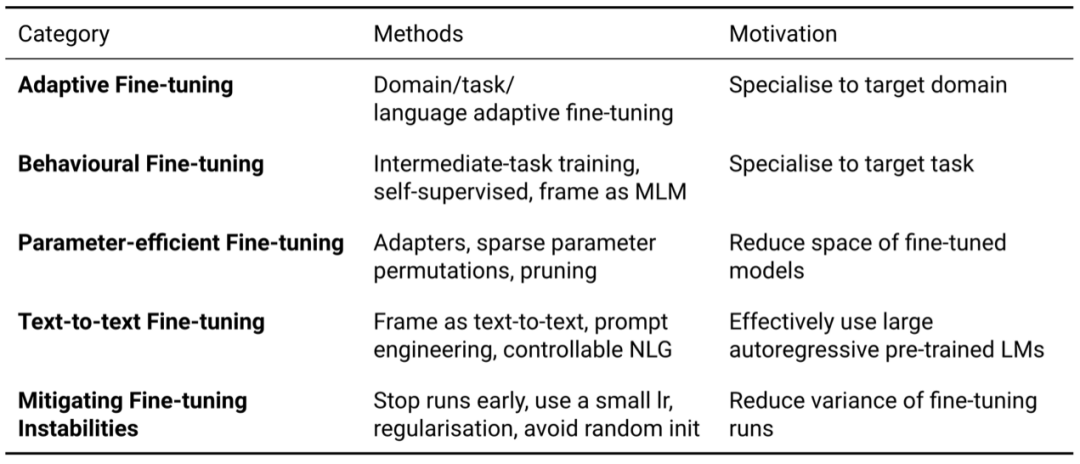
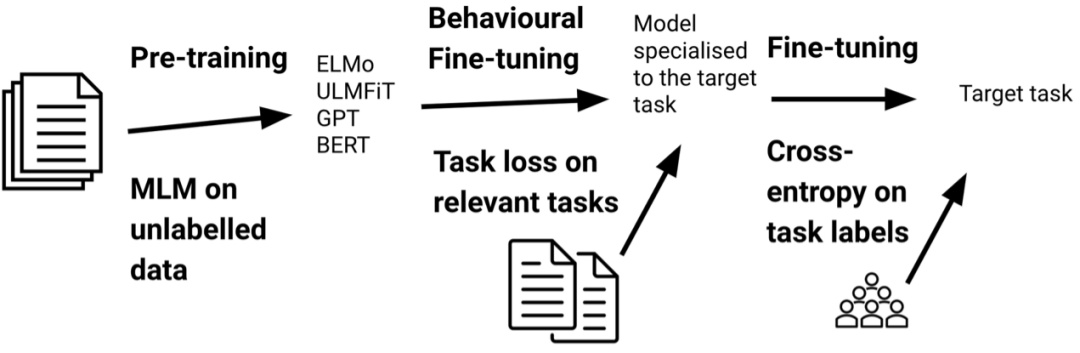
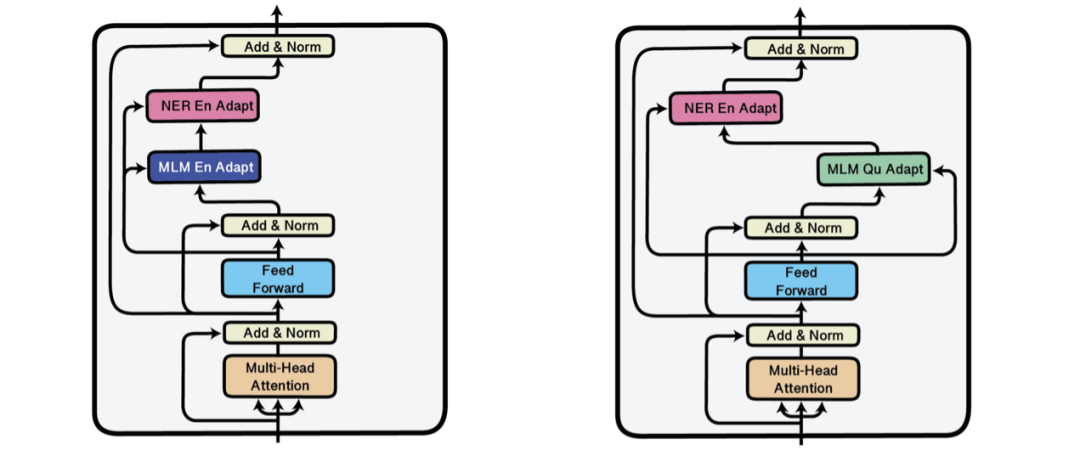
[1] Pan, Sinno Jialin and Qiang Yang. “A Survey on Transfer Learning.” IEEE Transactions on Knowledge and Data Engineering 22 (2010): 1345-1359. [2] Ruder, Sebastian. “Neural transfer learning for natural language processing.” (2019).[3] Logeswaran, L. et al. “Zero-Shot Entity Linking by Reading Entity Descriptions.” ArXiv abs/1906.07348 (2019): n. pag.[4] Han, Xiaochuang and Jacob Eisenstein. “Unsupervised Domain Adaptation of Contextualized Embeddings for Sequence Labeling.” EMNLP/IJCNLP (2019).[5] Mehri, Shikib et al. “Pretraining Methods for Dialog Context Representation Learning.” ArXiv abs/1906.00414 (2019): n. pag.[6] Phang, Jason et al. “Sentence Encoders on STILTs: Supplementary Training on Intermediate Labeled-data Tasks.” ArXiv abs/1811.01088 (2018): n. pag.[7] Broscheit, Samuel. “Investigating Entity Knowledge in BERT with Simple Neural End-To-End Entity Linking.” ArXiv abs/2003.05473 (2019): n. pag.[8] Arase, Yuki and Junichi Tsujii. “Transfer Fine-Tuning: A BERT Case Study.” EMNLP/IJCNLP (2019).[9] Glavas, Goran and I. Vulić. “Is Supervised Syntactic Parsing Beneficial for Language Understanding? An Empirical Investigation.” ArXiv abs/2008.06788 (2020): n. pag.[10] Garg, Siddhant et al. “TANDA: Transfer and Adapt Pre-Trained Transformer Models for Answer Sentence Selection.” ArXiv abs/1911.04118 (2020): n. pag.[11] Khashabi, Daniel et al. “UnifiedQA: Crossing Format Boundaries With a Single QA System.” EMNLP (2020).[12] Dou, Zi-Yi and Graham Neubig. “Word Alignment by Fine-tuning Embeddings on Parallel Corpora.” ArXiv abs/2101.08231 (2021): n. pag.[13] Ben-David, Eyal et al. “PERL: Pivot-based Domain Adaptation for Pre-trained Deep Contextualized Embedding Models.” Transactions of the Association for Computational Linguistics 8 (2020): 504-521.[14] Ram, Ori et al. “Few-Shot Question Answering by Pretraining Span Selection.” ArXiv abs/2101.00438 (2021): n. pag.[15] Bansal, Trapit et al. “Self-Supervised Meta-Learning for Few-Shot Natural Language Classification Tasks.” EMNLP (2020).[16] Rogers, Anna et al. “A Primer in BERTology: What We Know About How BERT Works.” Transactions of the Association for Computational Linguistics 8 (2020): 842-866.[17] Rebuffi, Sylvestre-Alvise et al. “Learning multiple visual domains with residual adapters.” NIPS (2017).[18] Houlsby, N. et al. “Parameter-Efficient Transfer Learning for NLP.” ICML (2019).[19] Stickland, Asa Cooper and Iain Murray. “BERT and PALs: Projected Attention Layers for Efficient Adaptation in Multi-Task Learning.” ICML (2019).[20] Izmailov, Pavel et al. “Averaging Weights Leads to Wider Optima and Better Generalization.” ArXiv abs/1803.05407 (2018): n. pag.[21] Huang, Gao et al. “Snapshot Ensembles: Train 1, get M for free.” ArXiv abs/1704.00109 (2017): n. pag.[22] Laine, S. and Timo Aila. “Temporal Ensembling for Semi-Supervised Learning.” ArXiv abs/1610.02242 (2017): n. pag.[23] Bapna, Ankur et al. “Simple, Scalable Adaptation for Neural Machine Translation.” EMNLP/IJCNLP (2019).[24] Pfeiffer, Jonas et al. “MAD-X: An Adapter-based Framework for Multi-task Cross-lingual Transfer.” EMNLP (2020).[25] Guo, Demi et al. “Parameter-Efficient Transfer Learning with Diff Pruning.” ArXiv abs/2012.07463 (2020): n. pag.[26] Aghajanyan, Armen et al. “Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning.” ArXiv abs/2012.13255 (2020): n. pag.[27] Donahue, J. et al. “DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition.” ICML (2014).[28] Howard, J. and Sebastian Ruder. “Universal Language Model Fine-tuning for Text Classification.” ACL (2018).[29] Ben-Zaken, Elad et al. “BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models.” (2020).[30] Sanh, Victor et al. “Movement Pruning: Adaptive Sparsity by Fine-Tuning.” ArXiv abs/2005.07683 (2020): n. pag.[31] Tamkin, A. et al. “Investigating Transferability in Pretrained Language Models.” EMNLP (2020).[32] Zhang, Tianyi et al. “Revisiting Few-sample BERT Fine-tuning.” ArXiv abs/2006.05987 (2020): n. pag.[33] Chung, Hyung Won et al. “Rethinking embedding coupling in pre-trained language models.” ArXiv abs/2010.12821 (2020): n. pag.[34] Li, C. et al. “Measuring the Intrinsic Dimension of Objective Landscapes.” ArXiv abs/1804.08838 (2018): n. pag.[35] Gordon, Mitchell A. et al. “Compressing BERT: Studying the Effects of Weight Pruning on Transfer Learning.” RepL4NLP@ACL (2020).[36] Brown, T. et al. “Language Models are Few-Shot Learners.” ArXiv abs/2005.14165 (2020): n. pag.[37] Schick, Timo and H. Schutze. “It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners.” ArXiv abs/2009.07118 (2020): n. pag.[38] Awasthi, Abhijeet et al. “Learning from Rules Generalizing Labeled Exemplars.” ArXiv abs/2004.06025 (2020): n. pag.[39] Dodge, Jesse et al. “Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping.” ArXiv abs/2002.06305 (2020): n. pag.[40] Mosbach, Marius et al. “On the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselines.” ArXiv abs/2006.04884 (2020): n. pag.[41] Zhu, C. et al. “FreeLB: Enhanced Adversarial Training for Natural Language Understanding.” arXiv: Computation and Language (2020): n. pag.[42] Jiang, Haoming et al. “SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization.” ArXiv abs/1911.03437 (2020): n. pag.[43] Aghajanyan, Armen et al. “Better Fine-Tuning by Reducing Representational Collapse.” ArXiv abs/2008.03156 (2020): n. pag.