CVPR 2020(Oral)丨MaskFlownet:基于可学习遮挡掩模的非对称特征匹配
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达
编者按:在光流预测任务中,形变带来的歧义与无效信息会干扰特征匹配的结果。在这篇 CVPR 2020 Oral 论文中,微软亚洲研究院提出了一种可学习遮挡掩模的非对称特征匹配模块 ,它可以被轻松结合到端到端的基础网络中,无需任何额外数据和计算开销就可以学习到遮挡区域,从而显著改进光流预测的结果。

论文:https://arxiv.org/abs/2003.10955
代码:https://github.com/microsoft/MaskFlownet
光流预测任务(opticalflow estimation)即给定一张原始图像与一张目标图像,希望建立一个表示从原始图像的每个像素到目标图像的对应关系的流场(flow field)。在理想情况下,目标图像通过流场形变得到的形变图像应该与原始图像非常相似。但是,前景与背景之间的相对位移产生的遮挡区域(occlusions)给形变图像带来了歧义与无效信息(如图1),使得光流预测任务变得更加困难。
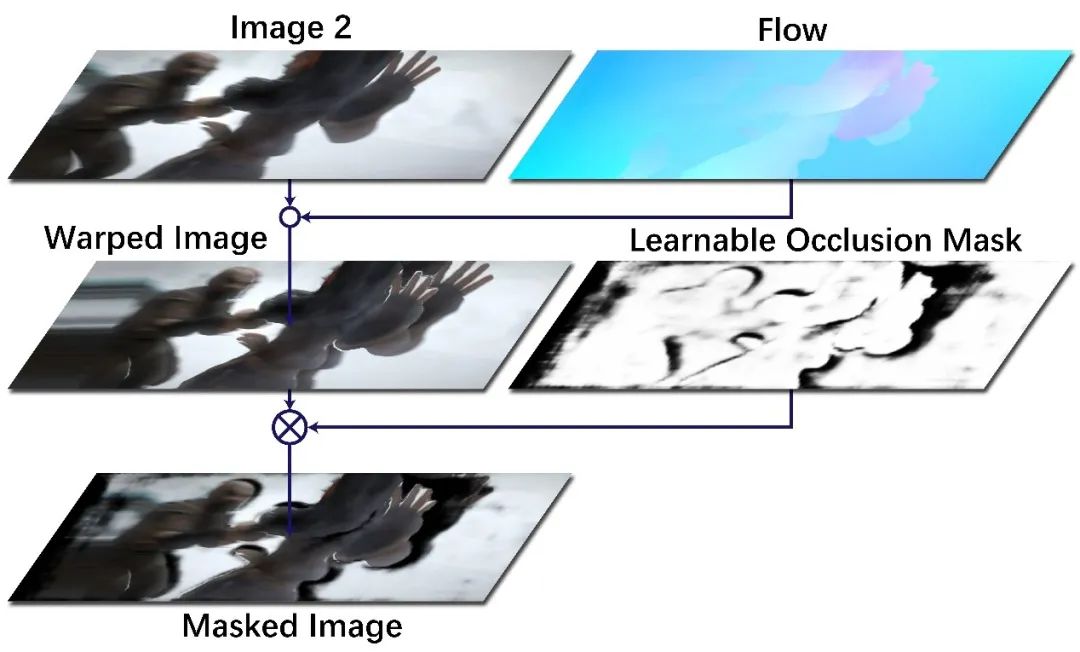
图1:可学习遮挡掩模作用于形变图像
近年来,基于卷积神经网络的深度学习正在被广泛地应用于光流预测领域,而特征形变(feature warping)则是其中最关键的一步。原始图像与目标图像首先通过同一个特征提取器得到不同层级的特征图,为了找到原始特征图与目标特征图之间的对应关系,特征形变将目标特征图通过当前预测的流场形变到与原始特征图相似的位置,再通过互相关层得到局部区域内两两像素之间的相关程度。然而,形变后的特征图同样在遮挡区域留下了歧义与无效信息,会干扰特征匹配的结果,这也是光流问题中尚未解决的主要问题之一。
本文提出一种可学习遮挡掩模(learnable occlusion mask)的非对称特征匹配模块,不需要任何显式的监督信息就可以预测遮挡区域、过滤特征形变带来的无效信息。如图1,目标图像通过流场形变之后,可学习遮挡掩模预测的遮挡(黑色)区域准确地过滤了重影部分的干扰信息,得到了干净的掩模图像(masked image)。在这个简单的例子中就可以看到,原始图像与目标图像并非完全对等——后者在形变之后产生了重影,需要利用掩模信息进行过滤。
可学习遮挡掩模的非对称特征匹配模块可以轻松结合到任何已有的基础网络上,通过端到端的方式自动学习到遮挡掩模,仅仅引入可忽略不计的额外计算量就可以显著提升网络的表现。
除此之外,我们还发现学习到的掩模可以和形变图像一起送入之后的级联网络中,进一步提升网络的整体表现。我们在 MPI Sintel、KITTI 2012 和 KITTI 2015 的光流数据集上都做了算法评测,截至投稿时间,均达到所有不使用额外信息的公开方法中最好的结果。

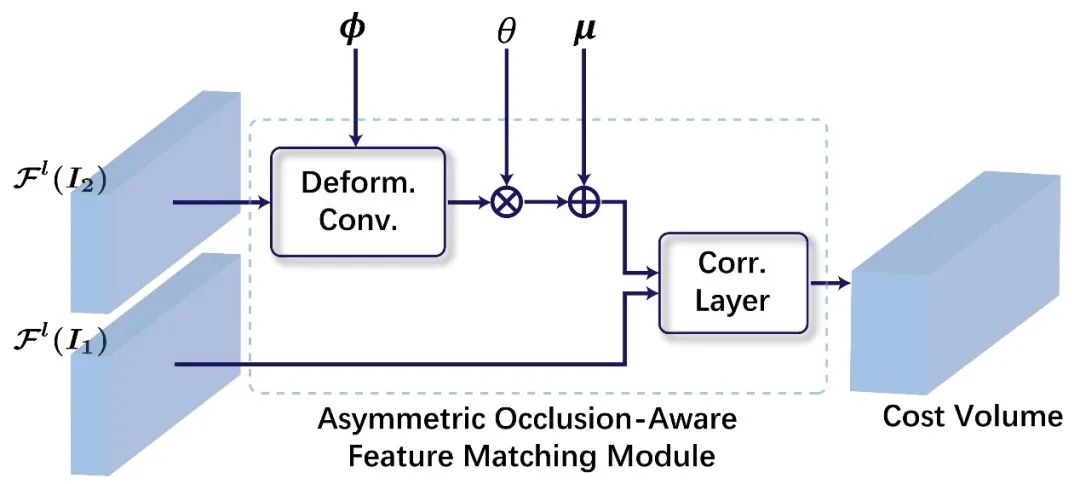
图2:可学习遮挡掩模的非对称特征匹配模块(AsymOFMM)
可学习遮挡掩模的非对称特征匹配模块的结构如图2所示。首先,我们非对称地引入了变形卷积(deformable convolution),即在根据当前流场对目标特征图进行形变的同时做一次额外的卷积,目的在于打破原始特征图与目标特征图的对称性。此时,网络预测的可学习遮挡掩模作用在形变后的特征图上(相乘),过滤重影现象带来的干扰信息,得到掩模特征图。最后,由于遮挡区域原本携带的信息在过滤之后有所缺失,因此需要与一个权衡项相加作为弥补,而这个权衡项,也是无监督学习到良好掩模的关键。
从图3中的对比可以看出,该模块不需要任何额外的监督信息就可以学习到反映真实遮挡区域的掩模。

图3:可学习遮挡掩模与遮挡区域真值(取反)对比
在该模块的基础上,我们还提出了可以充分利用掩模信息的双特征金字塔级联网络结构,进一步提升整个网络的表现。结合以上模块设计的MaskFlownet 的整体结构如图4所示。
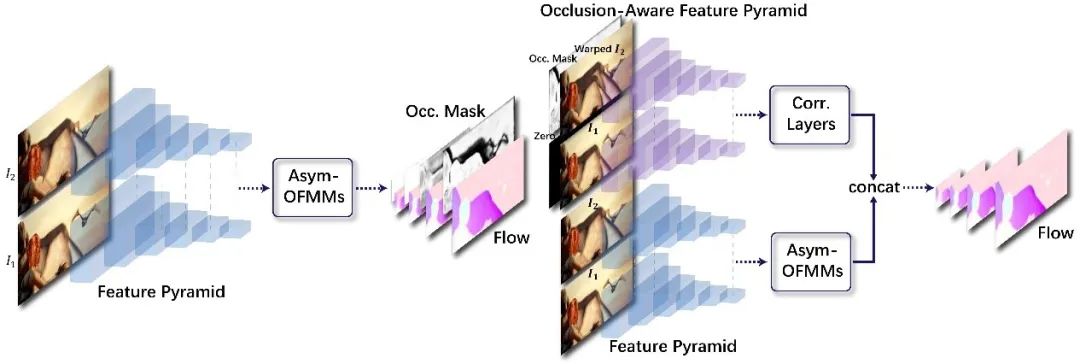
图4:MaskFlownet 完整网络结构
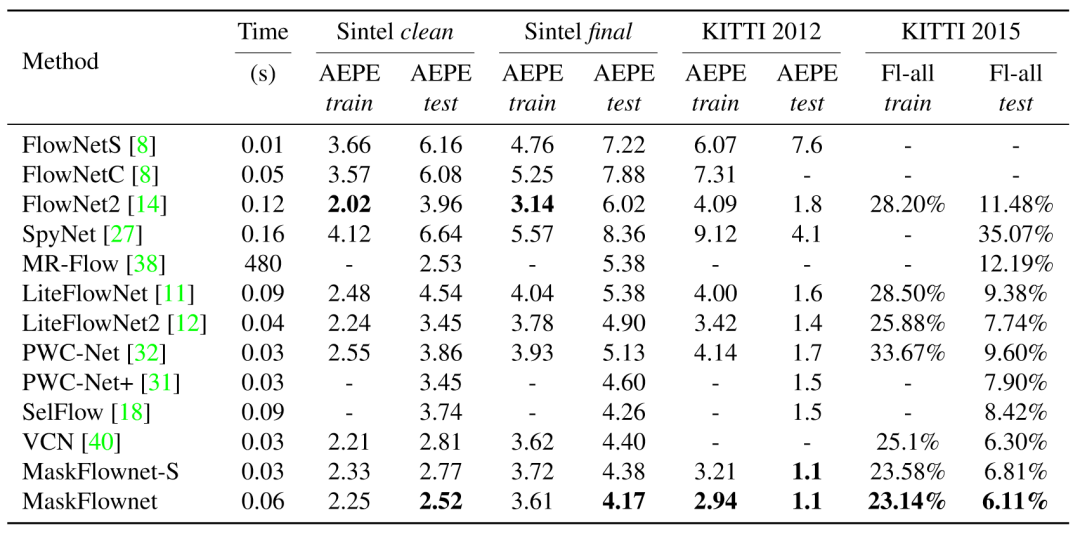
表1:总体实验结果
我们在 MPISintel、KITTI 2012 和 KITTI 2015 数据集上进行了广泛的实验。表1总结了我们的方法与其它方法相比的总体表现。其中,MaskFlownet-S 不使用级联部分、以 PWC-Net 为基础网络,仅仅将所有特征匹配部分替换为我们提出的可学习遮挡掩模的非对称特征匹配模块,就在所有数据集上都取得了实质性的提升。MaskFlownet 则进一步受益于级联网络,在所有测试集上都取得了所有方法中的最佳结果。
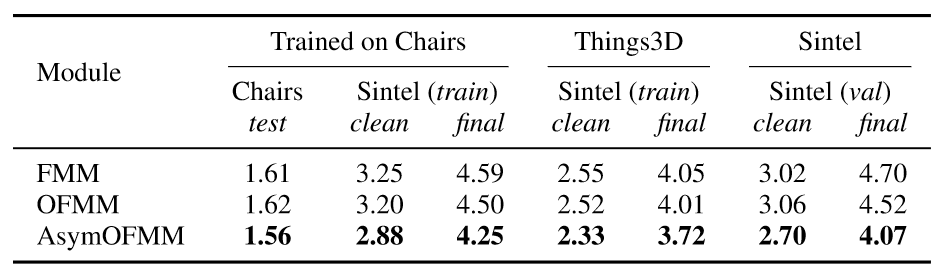
表2:不同特征匹配模块之间的对比
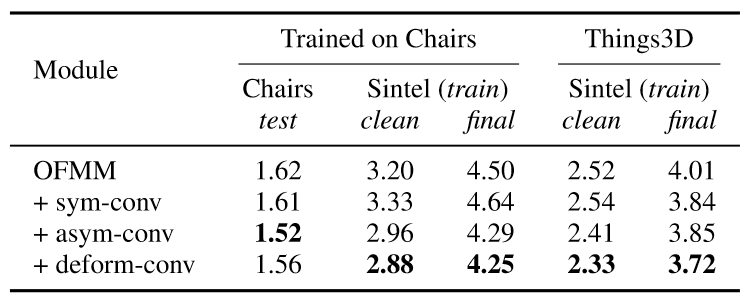
表3:对称与非对称卷积的对比
表2证明了可学习遮挡掩模的非对称特征匹配模块相对于普通设计的优越性。表3证明了增加一个对称的额外卷积层(sym-conv)对结果的影响并不显著,而简单的非对称设计就可以带来明显的提升。我们在实验中发现,经过非对称卷积的目标特征与原始特征的确可以学习到完全不同的特征表示进而从中受益,如图5所示。

图5:特征图中的非对称性
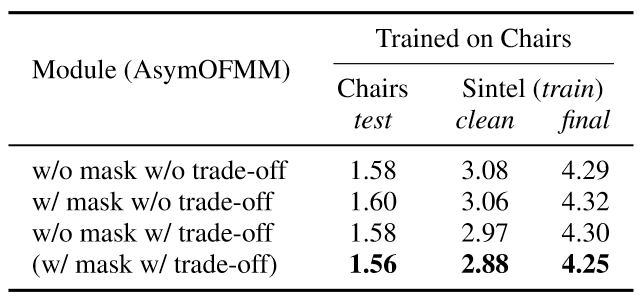
表4:掩模与权衡项的作用
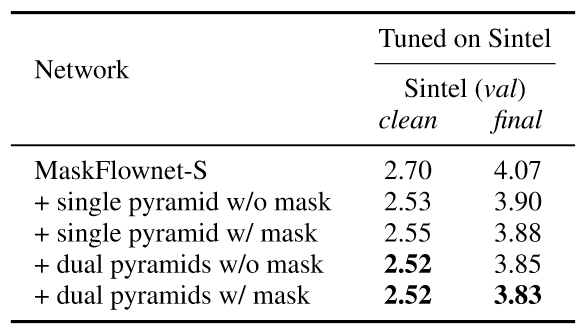
表5:级联与双特征金字塔的作用
表4说明了掩模与权衡项需要同时存在才会提升网络的表现。一个可能的解释是,只有质量良好的掩模才可以帮助特征匹配,而缺少权衡项将会导致网络无法学习到质量良好的掩模,如图6所示。表5证明了级联网络与双特征金字塔结构的作用。
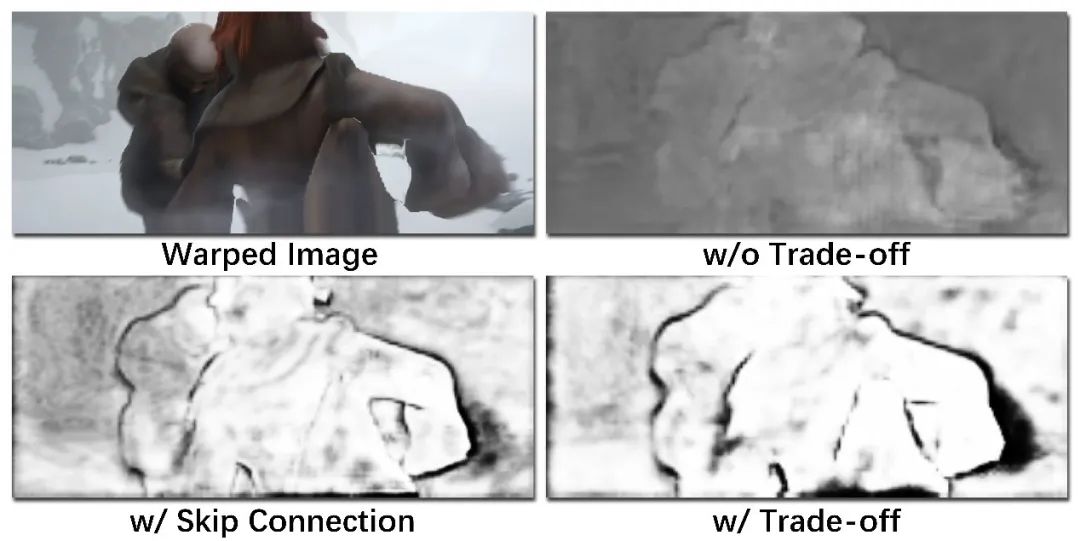
图6:有无权衡项(右上无,右下有)所学习到的掩模对比
我们提出了可学习遮挡掩模的非对称特征匹配模块,该模块可以被轻松结合到端到端的基础网络中,不需要任何额外数据就可以学习到遮挡区域,并且能显著改进光流预测的结果。
凭借其整体表现的优越性、不带来额外计算开销的便捷性、无需遮挡区域真值的普遍适用性、以及独立于基础网络的一般性,我们期望该模块可以在光流预测与特征匹配任务中得到广泛的应用。
更多技术细节请访问GitHub主页:https://github.com/microsoft/MaskFlownet
论文下载
在CVer公众号后台回复:MaskFlownet,即可下载本论文
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1800+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
请给CVer一个在看!



