

摘要——在大数据应用时代,联邦图学习(Federated Graph Learning, FGL)作为一种新兴的解决方案,正在逐步成为协调分布式数据持有者之间集体智能优化与最大限度保护敏感信息之间权衡的关键技术。已有的 FGL 综述虽具有重要价值,但主要集中于联邦学习(Federated Learning, FL)与图机器学习(Graph Machine Learning, GML)的集成,进而形成了一些以方法学和模拟场景为核心的早期分类体系。值得注意的是,从“数据中心化”视角出发,对 FGL 方法进行系统性梳理的尝试尚属空白,而这一视角对于评估 FGL 研究如何应对数据相关限制、进而提升模型性能至关重要。为此,本文提出了一种双层次的数据中心化分类框架:(1)数据特征,根据 FGL 所使用数据的结构性和分布性特征对相关研究进行归类;(2)数据利用,分析训练过程中应对关键数据难题所采用的策略与技术。每一层次的分类框架均由三个正交维度构成,分别对应不同的数据中心化配置。除分类框架外,本文还探讨了 FGL 与预训练大模型的集成应用,展示了其在现实世界中的典型应用案例,并总结了与 GML 发展趋势相契合的未来研究方向。 关键词:联邦图学习,机器学习
一、引言
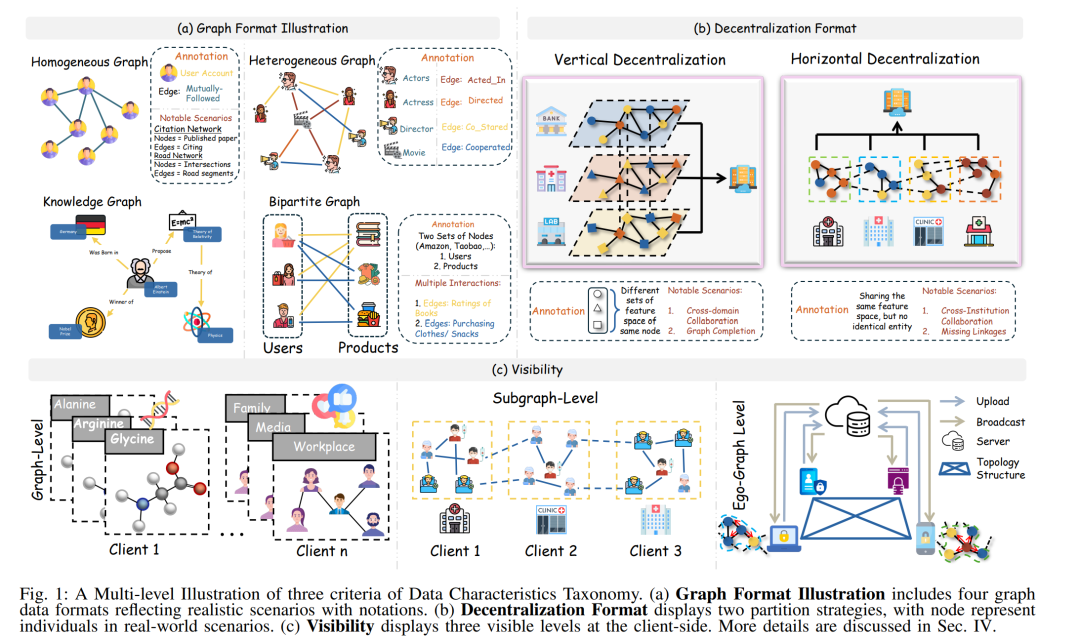
图数据集以非欧几里得结构形式表示,形式上被定义为由节点(实体)和边(关系)组成的元组,用以严谨地建模复杂的现实世界系统。图数据集的一个核心优势在于其能够显式地编码拓扑连接关系,从而突破独立同分布(i.i.d.)数据的传统约束,直接捕捉实体之间的交互依赖关系 [1]。与像素化图像或文本等传统数据格式不同,图结构具备独特的理论优势,而图神经网络(Graph Neural Networks, GNNs)的引入使得机器学习(Machine Learning, ML)算法可以基于传播机制挖掘隐藏在拓扑结构中的隐式信息结构。由于其显著的有效性,GNNs 促成了诸如 AlphaFold [2] 等突破性成果,该方法通过氨基酸序列预测蛋白质结构,推动了疫苗和抗体的开发。 鉴于 GNNs 所展现出的卓越性能,众多开创性模型相继被提出,例如 GCN [3] 和 GAT [4]。这些方法大多采用以模型为中心的研究视角,强调通过创新的结构设计在给定数据集上实现最优性能 [5]。然而,这类方法的成功往往隐含着一个前提假设:所使用的数据集已经经过充分清洗与处理,性能提升主要归因于模型结构的日益复杂。但现实世界中的数据常常存在显著的不确定性,如噪声干扰或对实体描述的不完整性,这些因素违背了上述假设。当低质量数据被输入 GNNs 时,模型难以有效提取可靠知识,从而暴露出模型中心范式在实际应用中的脆弱性。 为应对上述局限,数据中心化的图机器学习(Graph Machine Learning, GML)已逐渐发展为一种更具现实意义的研究范式,专注于解决实际数据问题。相应地,数据中心化 GML 正受到越来越多研究者的关注。然而,大多数现有研究仍假设数据处于集中式存储环境中,即数据被统一保存在单一位置。与之相比,去中心化的数据中心化 GML 仍属研究空白,尽管现实中数据往往分散在多个独立持有者手中。与此同时,对去中心化数据的处理还需满足隐私保护的严格法规要求。对此,联邦学习(Federated Learning, FL)因其能够在保障隐私的前提下实现分布式数据协同训练而备受关注 [6]。 随着 FL 向图数据的扩展,联邦图学习(Federated Graph Learning, FGL)迅速发展为一个专门的去中心化图学习框架。现有 FGL 研究普遍基于拟合真实场景的研究问题展开,在此基础上,已有综述提出了以“场景挑战”为导向的分类框架。这些工作为该领域的发展作出了积极贡献,但其范式主要源自模型中心视角,强调机制创新,却较少关注数据集本身的特征差异,也未充分讨论其数据中心化动因。 本文的动机:本综述旨在从数据中心化角度出发审视 FGL,源于对以下事实的清晰认知:当前大多数 FGL 面临的核心挑战均与数据紧密相关,如统计异质性与拓扑异质性。此外,若要深入理解这些挑战,就需要关注 FGL 所使用数据的特性,因为现有文献中已涉及多样的数据格式与去中心化配置。这种机制本质上是数据中心化 GML 在分布式环境下的延伸。为了帮助研究者从解决数据相关问题的角度更好地理解 FGL,本文致力于提供一个通用且系统化的指南。 具体而言,本文提出一个双层次的数据中心化分类框架,每一层均由三个正交维度组成,这些组合构成了对现有研究的全面理解: * 数据特征维度:包括(i)区分不同类型的图数据集(如同质图、异质图、知识图与二分图);(ii)突出数据在客户端间的分布形式;(iii)揭示每个客户端的数据可见性水平,即客户端是否可以访问完整全局图,或仅能访问部分子图。这些标准共同构成了对 FGL 研究中所处理数据结构与分布特征的全面刻画。 * 数据利用维度:探讨 FGL 方法如何以及何时将针对数据问题的机制纳入训练过程,具体包括:(i)明确关键数据挑战,如数据质量欠佳、客户端数据类别分布不均、大规模图训练过程中的收敛速度缓慢、以及数据隐私保护的增强;(ii)指出主要创新是集中在客户端侧,还是服务器端的操作流程中;(iii)进一步将训练过程细化为四个执行阶段(初始化、本地训练、全局聚合与后聚合),并总结典型 FGL 方法中所采用的技术细节。
作为首个聚焦于数据中心化视角的 FGL 综述,本文的贡献体现在以下三个方面: * (a)新视角:首次从数据中心化角度系统整理 FGL 研究,厘清不同类型数据在现有工作中的定义与使用方式。该视角契合大数据时代的研究重点,在此背景下,数据属性正在日益决定机器学习技术的选择与效果。 * (b)双层分类体系:提出基于数据中心化视角的双层次分类框架,每层均由三个正交标准构成,从细粒度上划分现有重要 FGL 研究,有助于研究者迅速定位与特定数据问题相关的研究成果。 * (c)扩展影响——生成式人工智能:首次探讨 FGL 与预训练大模型(Pre-trained Large Models, PLMs)的整合潜力,以加速图机器学习研究的进展。未来研究方向部分还指出了多个尚未被充分探索的数据中心化议题,强调其在 FGL 背景下的重要性与研究价值。
本文结构安排如下:第二节介绍 FL 与 FGL 的基本概念及其通用训练流程;第四节呈现基于数据特性的第一层分类,从本地与全局视角展开;第五节构建第二层分类,具体分析数据中心化挑战及代表性 FGL 方法的应对策略;第六节讨论客户端处理非图结构数据的研究;第七节评估 FGL 在解决现实世界数据问题中的适用性;第八节探讨 FGL 与 PLMs 的双向融合;第九节展望未来研究方向,包括 FGL 与 GML 热点议题的融合,以及向更复杂图结构类型的拓展。
