OpenAI炼丹秘籍:教你学会训练大型神经网络

来源:数据派THU
本文为约3512字,建议阅读7分钟
本文介
绍了一些训练大型神经网络的相关技术及底层原理。

如今AI的很多进步都要归功于大型神经网络,尤其是大公司和研究机构提供的预训练模型更是推动了下游任务的进步。
但想自己动手训练一个大型神经网络并不简单,首先要面对的就是海量的数据、多机协调和大量GPU的调度工作。
一提到「并行」,冥冥之中就会感觉多了很多隐藏的bug。

最近OpenAI发布了一篇文章,详细介绍了一些训练大型神经网络的相关技术及底层原理,彻底消除你对并行的恐惧!
比如以并行训练一个三层的神经网络为例,其中并行可以分为数据并行、pipeline并行,trensor并行和专家并行,图中不同颜色代表不同层、虚线隔开的是不同的GPU。
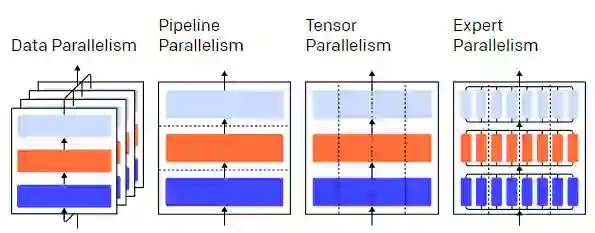
听上去很多,但理解这些并行技术实际上只需要对计算结构进行一些假设,然后对数据包的流动方向有所了解即可。
训练流程无并行
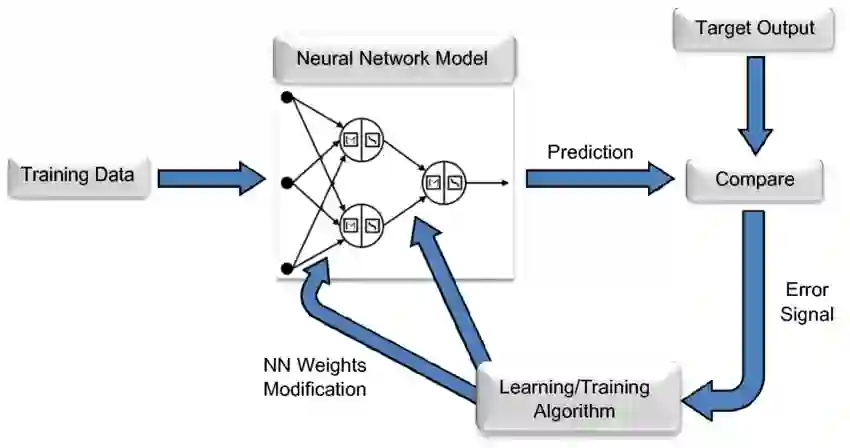
训练一个神经网络是一个迭代的过程。
在一次迭代中,输入数据经过模型的层,前向传递后即可为一个batch数据中的每个训练实例计算输出。
然后各层再向后传递,通过计算每个参数的梯度来传播每个参数对最终输出的影响程度。
每个batch数据的平均梯度、参数和一些每个参数的优化状态被传递给一个优化算法,比如Adam可以计算下一个迭代的参数(在你的数据上应该有更好的性能)和新的每个参数的优化状态。
随着训练在大量数据上的迭代,模型不断进化,产生越来越精确的输出。
在整个训练过程中,会有不同的并行技术在不同的维度上进行切割,包括:
1、数据并行,即在不同的GPU上运行一个batch的不同子集;
2、pipeline并行,即在不同的GPU上运行模型的不同层;
3、tensor并行,即将单一操作(如矩阵乘法)的数学运算拆分到不同的GPU上;
4、专家混合(Mixture of Experts, MoE),即只用每层的一部分来处理每个输入实例。
并行中说的GPU并非仅局限于GPU,对于其他神经网络加速器的用户来说,这些想法同样有效。
数据并行
数据并行训练意味着将相同的参数复制到多个GPU(通常称为worker),并将不同的实例分配给每个GPU同时进行处理。
单纯的数据并行仍然需要模型符合单个GPU的内存要求,如果你利用多个GPU进行计算,那代价就是存储许多重复的参数副本。有一些策略可以增加你的GPU可用的有效RAM,比如在两次使用之间将参数暂时卸载到CPU内存。
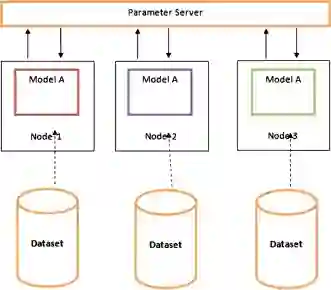
当每个数据并行worker更新其参数副本时,他们需要协调以确保每个worker继续拥有类似的参数。
最简单的方法是在worker之间引入阻塞式通信:
1、在每个worker上独立计算梯度;
2、在各worker上平均梯度;
3、每个worker上独立计算相同的新参数。
其中步骤2是的阻塞需要传输相当多的数据(与worker的数量乘以参数量的大小成正比),非常有可能降低训练吞吐量。
虽然有各种异步同步方案来消除这种开销,但它们会损害学习效率;在实践中,研究人员通常还是会坚持使用同步方法。
Pipeline并行
pipeline并行训练的意思是将模型的顺序块分割到不同的GPU上,每个GPU只持有一部分参数,因此,同一个模型在每个GPU上消耗的内存比例较小。
将一个大的模型分割成连续层的大块是很直接的一种方式。然而,各层的输入和输出之间存在着顺序上的依赖性,所以一个朴素的实现可能会导致大量的空闲时间,而wroker在等待前一个机器的输出被用作其输入。
这些等待时间块被称为气泡(bubbles),浪费了空闲机器可以完成的计算。
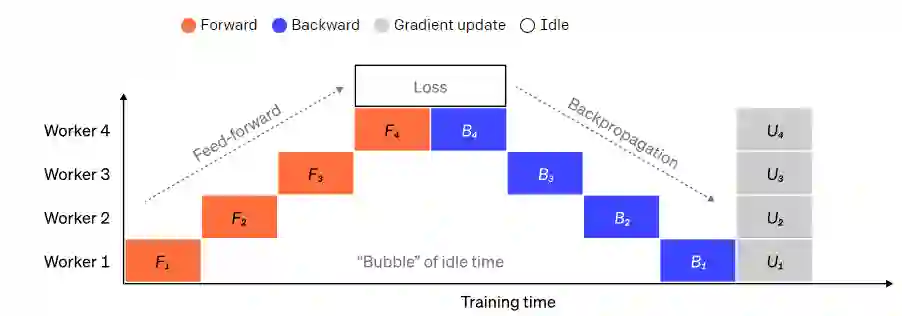
我们可以重用数据并行的思想,通过让每个worker一次只处理一个数据元素的子集来降低气泡的成本,巧妙地将新的计算与等待时间重叠起来。
核心思想是将一个batch分成多个microbatches;每个微批的处理速度应该是成比例的,每个worker在下一个微批可用时就开始工作,从而加速管道的执行。
有了足够的微批,worker在大部分时间内都处于工作状态,并且在每个step的开始和结束时气泡最小。梯度是所有微批的平均值,只有所有微批完成之后才会进行参数更新。
模型被分割的worker的数量通常被称为pipeline深度。
在前向传递期间,worker只需要将其大块层的输出(也叫激活)发送给下一个worker;在后向传递期间,它只将这些激活的梯度发送给前一个worker。如何调度这些传递过程以及如何在微批中聚合梯度,仍然有很大的设计空间。
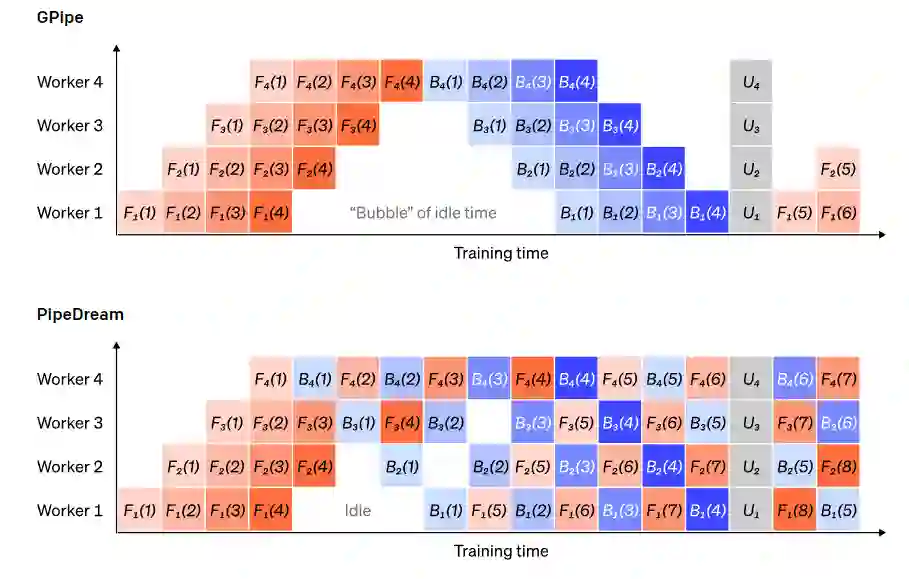
GPipe的做法是让每个worker连续地处理前向和后向的传递,然后在最后同步地聚合来自多个微批的梯度。而PipeDream则安排每个工作者交替地处理前向和后向通道。
Tensor并行
Pipeline并行是将一个模型按层「垂直」分割,而Tensor并行则是在一个层内「横向」分割某些操作。
对于现代模型(如Transformer)来说,计算瓶颈主要来自激活批矩阵与大权重矩阵相乘。矩阵乘法可以被认为是成对的行和列之间的点积,所以是有可能在不同的GPU上独立计算点积,或者在不同的GPU上计算每个点积的一部分,最后再将结果相加。无论采用哪种策略,我们都可以将权重矩阵切成偶数大小的「碎片」,将每个碎片放在不同的GPU上,并使用该碎片来计算整个矩阵乘积的相关部分,然后再进行GPU间通信来合并结果。
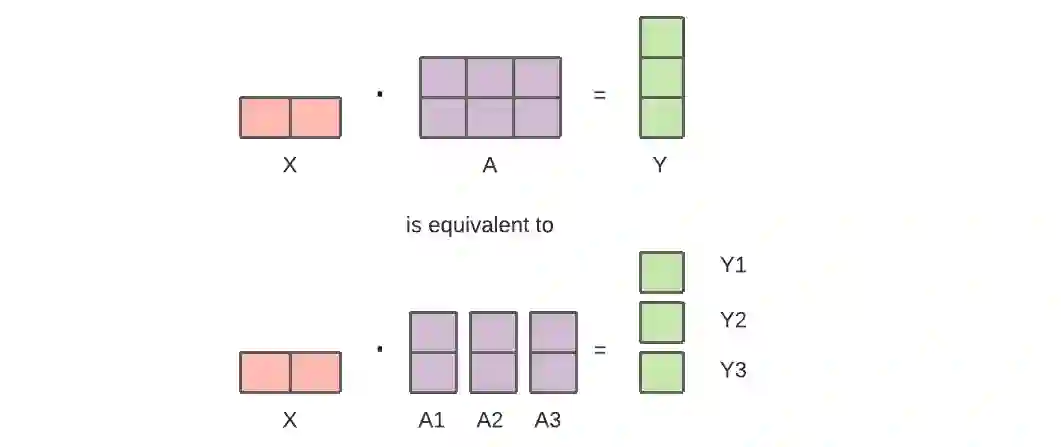
Megatron-LM采用的就是这种方式,它在Transformer的自注意力和MLP层内并行化矩阵乘法。PTD-P使用Tensor、数据和Pipeline并行;它的pipeline调度将多个不连续的层分配给每个设备,以更多的网络通信为代价减少气泡的开销。
有时网络的输入也可以在一个维度上进行并行化,相对于交叉通信来说,并行计算的程度很高。序列并行就是这样一个想法,一个输入序列在不同时间被分割成多个子实例,通过以更细粒度的实例进行计算,可以按比例减少峰值内存消耗。
混合专家系统(MoE)
混合专家系统(MoE)
对于任何一个输入,MoE策略都只有一部分网络被用来计算输出。
比如说一个网络里有很多套权重,网络可以在推理时通过门控机制选择具体使用哪套。这样就可以在不增加计算成本的情况下增加参数量。
每组权重被称为一个「专家」,训练目标是希望网络能够学会将专门的计算和技能分配给每个专家。不同的专家可以托管在不同的GPU上,为扩大模型使用的GPU数量提供了一个明确的方法。
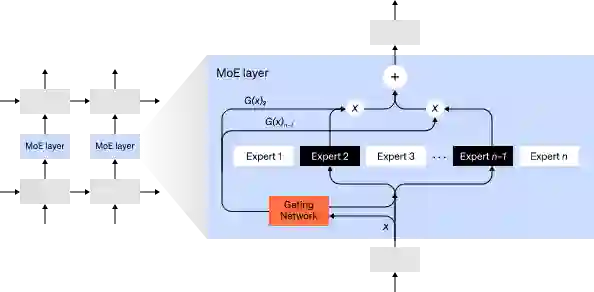
GShard可以将MoE Transformer的规模扩大到6000亿个参数,其方案是只有MoE层被分割到多个TPU设备上,而其他层则是完全重复的。
Switch Transformer则是通过将一个输入路由(routing)到一个专家,成功将模型规模扩展到数万亿的参数,甚至稀疏度更高。
省内存小妙招
除了买GPU外,还有一些计算策略可以帮助节省内存,方便训练更大的神经网络。
1、为了计算梯度,你可能需要保存原始激活值,这可能会消耗大量的设备内存。检查点(Checkpointing, 也被称为激活再计算)可以存储任何激活子集,并在后向通道中以just-in-time的方式重新计算中间激活。
这种方式可以节省大量的内存,而计算成本最多就是多出一个完整的前向传递。我们也可以通过选择性的激活再计算来不断地在计算和内存成本之间进行权衡,也就是检查那些存储成本相对较高但计算成本较低的激活子集。
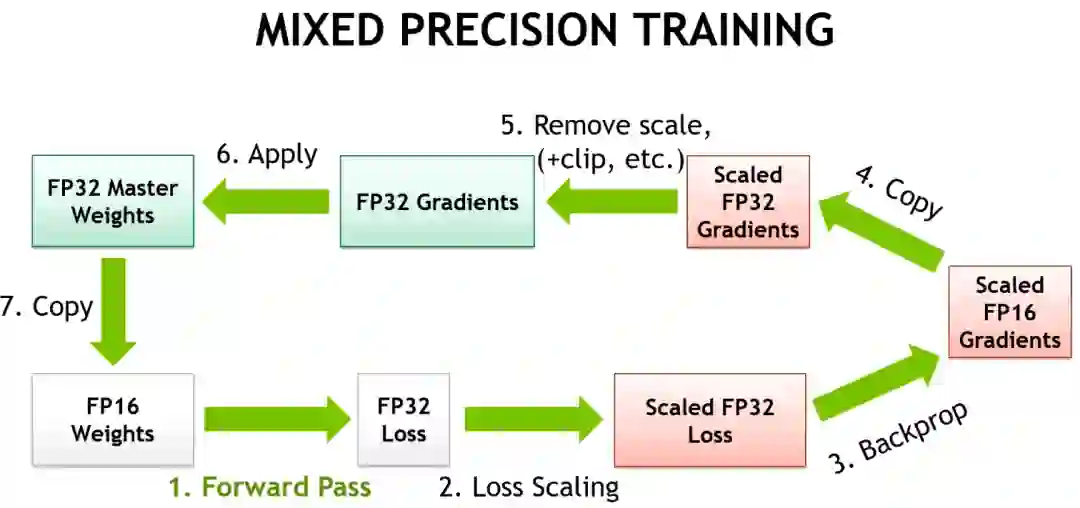
2、混合精度训练(Mixed Precision Training)是使用较低精度的数字(最常见的是FP16)来训练模型。现代的计算加速器可以用低精度数字达到更高的FLOP数,而且你还可以节省设备RAM。只要处理得当,这种方式训练得到的模型在性能上几乎不会有太大损失。
3、卸载(Offloading)是将未使用的数据暂时卸载到CPU或不同的设备中,然后在需要时再将其读回。朴素的实现方式会大大降低训练速度,但复杂的实现方式会预先获取数据,这样设备就不需要再等待了。
这个想法的一个具体实现是ZeRO,它将参数、梯度和优化器状态分割到所有可用的硬件上,并根据实际需要再将它们具体化。
4、内存效率优化器(Memory Efficient Optimizer)可以减少优化器所维护的运行状态的内存占用,如Adafactor。
5、压缩(Compression)也可用于存储网络中的中间结果。例如,Gist对为后向传递而保存的激活进行压缩;DALL-E在同步梯度之前压缩了梯度。




