CVPR 2019 | 亮风台推出全球最大单目标跟踪数据集 LaSOT

包含超过 352 万帧手工标注的图片和 1400 个视频,也是目前为止最大的拥有密集标注的单目标跟踪数据集。
AI 科技评论消息,计算机视觉和模式识别领域顶级会议 CVPR 2019 于上周在美国落下帷幕,各大企业和科研机构纷纷发布自家最新成果,其中,不乏诸多来自中国的研究成果。接下来,AI 科技评论将为大家介绍亮风台在 CVPR 2019 上展示的大规模单目标跟踪高质量数据集 LaSOT,这一数据集包含超过 352 万帧手工标注的图片和 1400 个视频,这也是目前为止最大的拥有密集标注的单目标跟踪数据集。以下为亮风台所提供的详细解读:
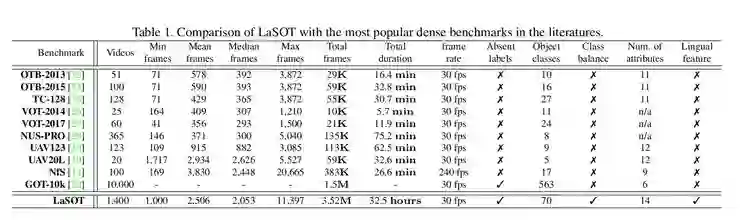
论文《LaSOT: A High-quality Benchmark for Large-scale Single Object Tracking》详细阐述了 LaSOT 数据集的构造原理和评估方法,由亮风台、华南理工大学、美图-亮风台联合实验室等单位共同完成,收录于 CVPR 2019。
LaSOT 贡献
视觉跟踪是计算机视觉中最重要的问题之一,其应用领域包括视频监控、机器人技术、人机交互等。随着跟踪领域的巨大进步,人们提出了许多算法。在这一过程中,跟踪基准对客观评估起到了至关重要的作用。LaSOT 的推出,也是希望为行业提供一个大规模的、专门的、高质量的基准,用于深度跟踪训练和跟踪算法的真实评估。
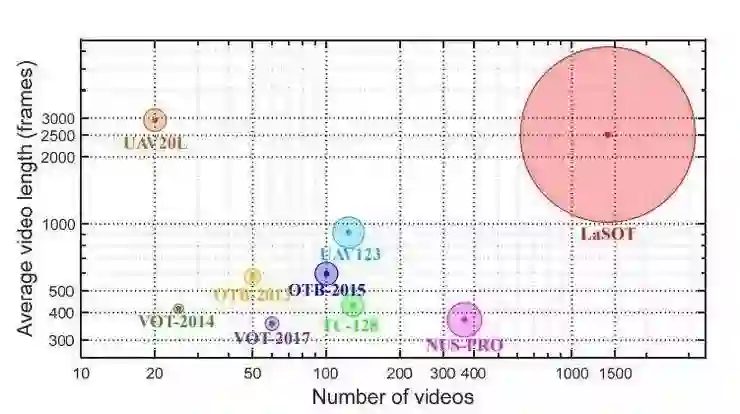
图 1:常用跟踪数据集统计示意图。包括 OTB-2013、OTB-2015、TC-128、NUS-PRO、UAV123、UAV20L、VOT-2014、VOT-2017 和 LaSOT。圆直径与数据集的总帧数数成比例。所提出的 LaSOT 比所有其他基准都要大,并且专注于长期跟踪。
观察和比较不同的跟踪算法发现,其进一步发展和评估受到现有评测集的限制,存在的问题主要包括:
1. 规模小。现有数据集很少有超过 400 个序列,由于缺乏大规模的跟踪数据集,很难使用跟踪特定视频训练深度跟踪器。
2. 短时跟踪。理想的跟踪器能够在相对较长的时间内定位目标,目标可能消失并重新进入视图。然而,大多数现有的基准都集中在短期跟踪上,其中平均序列长度小于 600 帧(即 20 秒左右),而且目标几乎总是出现在视频帧中。
3. 类别偏见。一个稳健的跟踪系统应该表现出对目标所属类别的不敏感性,这意味着在训练和评估跟踪算法时都应该抑制类别偏差(或类别不平衡)。然而,现有的基准通常只包含几个类别,视频数量不平衡。
许多数据集被提议处理上述问题,然而,并没有解决所有的问题。
基于上述动机,亮风台为社区提供了一个新的大型单目标跟踪(LaSOT)基准,并提供了多方面的贡献:
1. LaSOT 包含 1400 个视频,每个序列平均 2512 帧。每一帧都经过仔细检查和手动标记,并在需要时对结果进行目视检查和纠正。这样,可以生成大约 352 万个高质量的边界框标注。
此外,LaSOT 包含 70 个类别,每个类别包含 20 个序列。据了解,LaSOT 是迄今为止最大的具有高质量手动密集注释的对象跟踪数据集。
2. 与之前的数据集不同,LaSOT 提供了可视化边界框注释和丰富的自然语言规范,这些规范最近被证明对各种视觉任务都是有益的,包括视觉跟踪。这样做的目标是鼓励和促进探索集成视觉和语言功能,以实现强大的跟踪性能。
3. 为了评估现有的跟踪器,并为将来在 LaSOT 上的比较提供广泛的基准,团队在不同的协议下评估了 35 个具有代表性的跟踪器,并使用不同的指标分析其性能。
LaSOT 大规模多样化的数据采集
LaSOT 数据集的构建遵循大规模、高质量的密集注释、长期跟踪、类别平衡和综合标记五个原则。
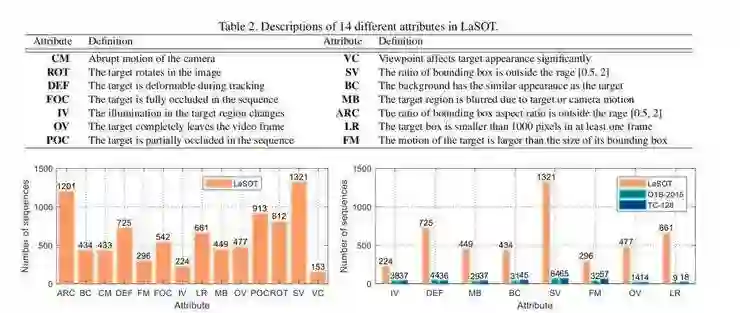
LaSOT 基准数据采集涵盖了各种不同背景下的各种对象类别,包含 70 个对象类别。大多数类别是从 ImageNet 的 1000 个类别中选择的,但少数例外(如无人机)是为流行的跟踪应用程序精心选择的。以往的数据集通常含有的类别少于 30 个,并且一般分布不均匀。相比之下,LaSOT 为每个类别提供相同数量的序列,以减轻潜在的类别偏差。
在确定了 LaSOT 中的 70 个对象类别之后,研究人员从 YouTube 中搜索了每个类的视频。最初,收集了 5000 多个视频。考虑到追踪视频的质量和 LaSOT 的设计原则,挑选了 1400 个视频。但是,由于大量无关内容,这 1400 个序列不能立即用于跟踪任务。例如,对于个人类别的视频(例如,运动员),它通常在开始时包含每个运动员的一些介绍内容,这不适合跟踪。因此,研究人员仔细过滤掉每个视频中不相关的内容,并保留一个可用于跟踪的剪辑。此外,LaSOT 的每一个分类都包含 20 个目标,反映了自然场景中的分类平衡和多样性。
最终,研究人员通过收集 1400 个序列和 352 万帧的 YouTube 视频,在 Creative Commons 许可下,编译了一个大规模的数据集。LaSOT 的平均视频长度为 2512 帧(即 30 帧每秒 84 秒)。最短的视频包含 1000 帧(即 33 秒),最长的视频包含 11397 帧(即 378 秒)。
LaSOT 提供可视化边界框标注
为了提供一致的边界框标注,团队还定义了一个确定性标注策略。对于具有特定跟踪目标的视频,对于每个帧,如果目标对象出现在帧中,则标注者会手动绘制/编辑其边界框,使其成为最紧的右边界框,以适合目标的任何可见部分;否则,标注者会向帧提供一个「目标不存在」的标签,无论是不可见还是完全遮挡。请注意,如任何其他数据集中所观察到的那样,这种策略不能保证最小化框中的背景区域。然而,该策略确实提供了一个一致的标注,这对于学习物体的运动是相对稳定的。
虽然上述策略在大多数情况下都很有效,但也存在例外情况。有些物体,例如老鼠,可能有细长和高度变形的部分,例如尾巴,这不仅会在物体的外观和形状上产生严重的噪声,而且对目标物体的定位提供很少的信息。在 LaSOT 中仔细识别这些对象和相关的视频,并为它们的注释设计特定的规则(例如,在绘制它们时不包括老鼠的尾部)。

图 2:LaSOT 示例序列和标注
序列的自然语言规范由描述目标的颜色、行为和环境的句子表示。对于 LaSOT,为所有视频提供 1400 个描述语句。请注意,语言描述旨在为跟踪提供辅助帮助。例如,如果追踪器生成进一步处理的建议,那么语言规范可以作为全局语义指导,帮助减少它们之间的模糊性。
构建高质量密集跟踪数据集的最大努力显然是手动标记、双重检查和纠错。为了完成这项任务,亮风台组建了一个注释小组,包括几个在相关领域工作的博士生和大约 10 名志愿者。
35 个代表性跟踪器的评估
没有对如何使用 LaSOT 进行限制,提出了两种协议来评估跟踪算法,并进行相应的评估。
方案一:使用 1400 个序列来评估跟踪性能。研究人员可以使用除了 LaSOT 中的序列以外的任何序列来开发跟踪算法。方案一旨在对跟踪器进行大规模评估。
方案二:将 LaSOT 划分为训练和测试子集。根据 80/20 原则(即帕累托原则),从每类 20 个视频中选出 16 个进行培训,其余的进行测试。具体来说,训练子集包含 1120 个视频,2.83m 帧,测试子集包含 280 个序列,690k 帧。跟踪程序的评估在测试子集上执行。方案二的目标是同时提供一大套视频用于训练和评估跟踪器。
根据流行的协议(如 OTB-2015[53]),使用 OPE 作为量化评估标准,并测量两个协议下不同跟踪算法的精度、标准化精度和成功率。评估了 LaSOT 上的 35 种算法,以提供广泛客观的基准,Tab. 3 按时间顺序总结这些跟踪器及其表示方案和搜索策略。
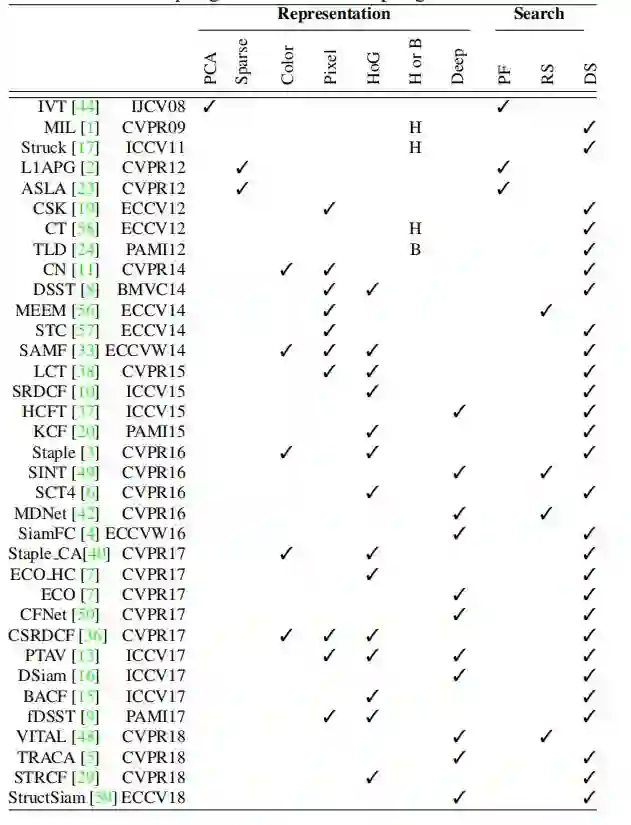
表 3:已评估跟踪程序的摘要
方案一评估结果
方案一旨在对 LaSot 的 1400 个视频进行大规模评估。每个跟踪器都按原样用于评估,没有任何修改。使用精度、标准化精度和成功率在 OPE 中报告评估结果。
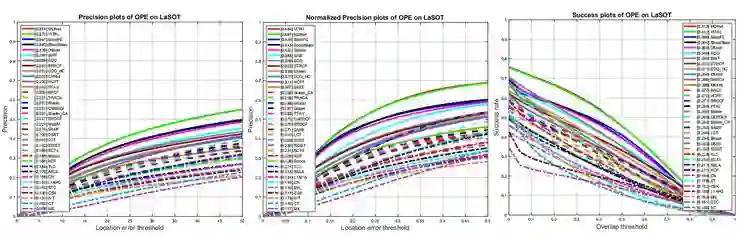
图 3:利用精度、归一化精度和成功率对一号方案下的算法量化评估。
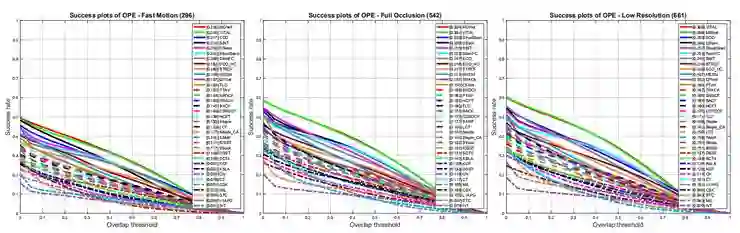
图 4:在协议 I 下,追踪器在三个最具挑战性的属性上的代表性结果。
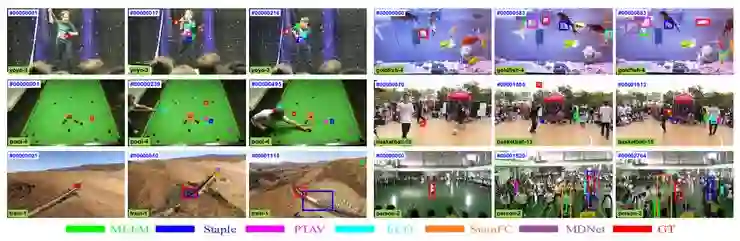
图 5:六大典型挑战序列上的的定性评价结果。
方案二评估结果
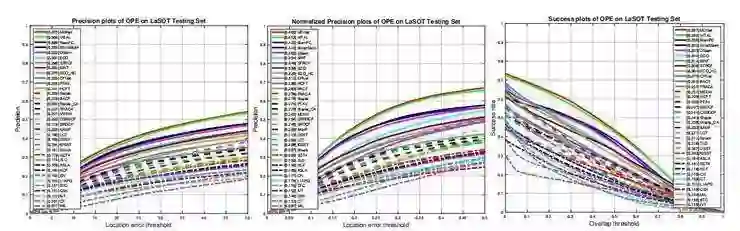
图 6:使用精度、标准化精度和成功率对方案 II 下的跟踪算法评估。
根据方案二,将 LaSOT 分为训练集和测试集。研究人员可以利用训练集中的序列来开发他们的跟踪器,并评估他们在测试集中的表现。为了提供测试集的基线和比较,评估了 35 种跟踪算法。每个跟踪器都被用于评估,没有任何修改或再培训。使用精度、归一化精度和成功率的评价结果如图 6 所示。
除了对每一种跟踪算法进行评估外,还对两种具有代表性的深跟踪算法 MDNET[42] 和 SIAMFC 进行了重新培训,并对其进行了评估。评估结果表明,这些跟踪器在没有重训练的情况下具有相似的性能。一个潜在的原因是重新培训可能和原作者使用配置不同。
文中又对 SiamFC 的 LaSOT 训练集进行了再培训,以证明使用更多的数据如何改进基于深度学习的跟踪器。Tab. 4 报告了 OTB-2013 和 OTB-2015 的结果,并与在 ImageNet 视频上培训的原始 SIAMFC 的性能进行了比较。请注意,论文中使用彩色图像进行训练,并应用 3 个比例的金字塔进行跟踪,即 SIAMFC-3S(彩色)。所有训练参数和跟踪在这两个实验中保持不变。最后在两个评测集上观察到了一致的性能提升,显示了针对深度追踪器的特定大规模训练集的重要性。
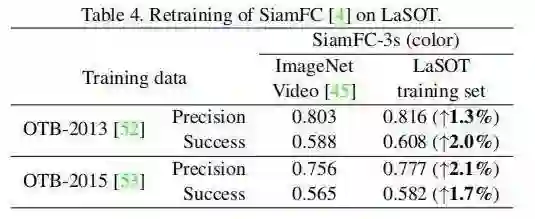
表 4:在 LaSOT 上对 SiamFC 进行再训练
LaSOT 主页:https://cis.temple.edu/lasot/
数据集下载:https://cis.temple.edu/lasot/download.html
算法测评和工具包:https://cis.temple.edu/lasot/results.html
论文:https://arxiv.org/abs/1809.07845
2019 年 7 月 12 日至 14 日,由中国计算机学会(CCF)主办、雷锋网和香港中文大学(深圳)联合承办,深圳市人工智能与机器人研究院协办的 2019 全球人工智能与机器人峰会(简称 CCF-GAIR 2019)将于深圳正式启幕。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

今日限量赠送5张1000元门票优惠码,门票原价1999元,打开以下任一链接即可使用,券后仅999元,限量5张,先到先得,送完即止。
https://gair.leiphone.com/gair/coupon/s/5d11f29598b17
https://gair.leiphone.com/gair/coupon/s/5d11f295988af
https://gair.leiphone.com/gair/coupon/s/5d11f2959856e
https://gair.leiphone.com/gair/coupon/s/5d11f29598301
https://gair.leiphone.com/gair/coupon/s/5d11f2959807d




