深度学习的快速目标跟踪

本文原载于知乎专栏「目标跟踪之相关滤波 CF」,AI 研习社获得授权转载。
第一部分:CPU real-time tracker

终极鲁棒的人脸跟踪
关于跟踪,除了鲁棒性 (robust) 和准确性 (accuracy),这个专栏更关注跟踪算法的速度 (speed),2014~2017 年 CPU real-time tracker 汇总:
环境 Inter i3 CPU @ 3.70GHz, 8GB,64 位,没有 GPU,软件 MATLAB R2016a,在 OTB-100 上的结果,虽然与论文结果略有差异,但都是同一环境下的公平测试结果,供参考,对应论文和源码地址在以前博文里面都贴过了,这里略。

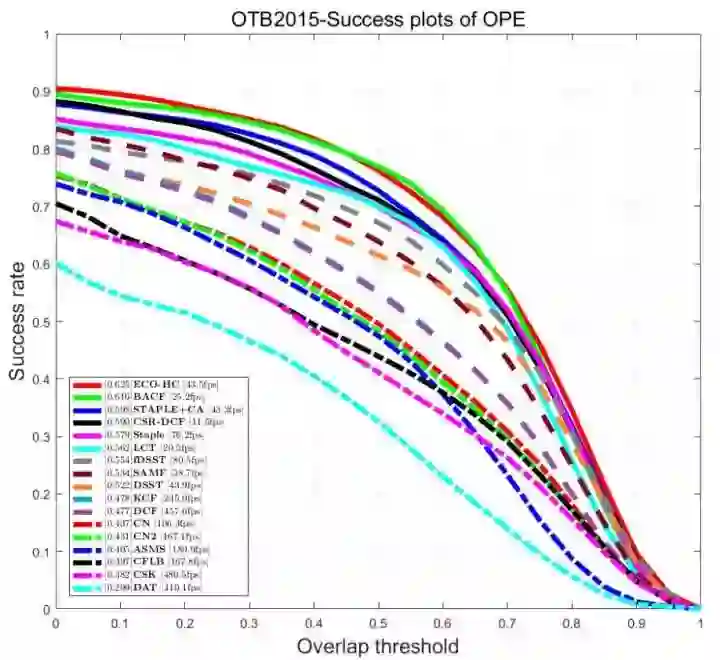
看起来这些 tracker 都与深度学习没有关系,没有 CNN 也没有卷积特征,好像 CNN 这个词天生就和 GPU 绑定在一起了,接下来我们就探究那些 GPU 上能实时的 tracker,分析它们有没有可能在 CPU 上也做到实时,甚至在 ARM 上也能跑起来。
第二部分:GPU real-time tracker
下面将要介绍的几个 GPU 快速跟踪算法,与上面不同,都是 CNN 相关的 (深度学习热,蹭人气~),推荐的这几个算法有以下相似点:
GPU 上能实时;
训练数据库是著名竞赛 ILSVRC(2015~2017) 的 Object detection from video task (VID),与测试序列完全隔离;
CNN 离线训练,在线不更新;(这也是能实时的保证)
在 VOT 上表现较好。
第一个要出场的,也是这一博文的主角 SiamFC,来自牛津 Luca Bertinetto 大神 SiameseFC tracker(http://t.cn/RcaRnrN )
Bertinetto L, Valmadre J, Henriques J F, et al. Fully-convolutional siamese networks for object tracking [C]// ECCV, 2016.
(直接跳过了同为 16ECCV 的 GOTURN,这个 tracker 虽然 GPU 上 100fps,但综合性能太差,在 OTB100 上甚至还不如 KCF,GPU 100fps vs. CPU 178fps,KCF 完胜!)
先来看看 SiamFC 的战绩:综合性能甩出 GOTURN 几条街,在 VOT15 上超过了 SRDCF;GPU 速度,3 尺度 86fps,5 尺度 58fps;VOT2016,基于 ResNet 的 SiamFC-R 第 12,基于 AlexNet 的 SiamFC-A 第 21;VOT2017,公测第 22,速度测试的冠军。
SiamFC 短短一年就有很多跟进 paper,可以说开创了目标跟踪的另一个方向,相关论文见下图。从 VOT2017 的结果来看,SiamFC 系列是少数幸存的 end2end 离线训练 tracker,是目前唯一可以与相关滤波抗衡的方向,是可以得益于大数据和深度学习的最具发展潜力的方向。(先吹一波,好累~ 喘口气)

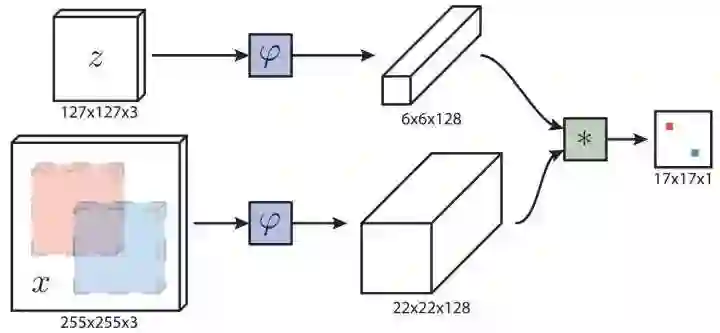
主体结构:Siamese network,核心 CNN 是 AlexNet,去掉 padding 和全连接层 FC,加入 BN 层,改为全卷积网络 FCN,控制 stride 为 8。FCN 部分作用相当于特征提取,会得到与输入图像分辨率相关,通道数 128 的 feature map,类似与常用 fHOG 特征 (h/4, w/4, 31)。
检测流程:两路输入图像分别用训练好的同一个 CNN(FCN) 提取特征,目标区域扩展纹理 (padding=1) 的输入图像,简称目标图像缩放到 127*127*3 特征 6*6*128,目标图像 4 倍大小的检测区域,简称检测图像缩放到 255*255*3 特征 22*22*128,相似度度量是 cross-correlation 交叉相关,计算每个位置的相似度得到 score map,其实就是拿输入特征 6*6*128*1 作为卷积核,对 22*22*128 的 feature map 进行卷积操作,(22-6)/1+1 = 17,得到 17*17*1 的输出。最后将很粗的 score map 双三次插值上采样,获得更精确稳定的目标位置,这一步在相关滤波中也非常常见,不过那里用了更方便的频谱插值。
Cross-correlation:FCN 具有位置对应特性,原本的检测操作应该是,在检测特征图上滑窗,寻找与目标特征相似度最高的位置,这里通过卷积操作代替滑窗检测,一个字:快!准!恨!
虽然卷积是滑窗检测的高效实现,但其本质上依然是滑窗,计算速度比相关滤波慢多了。这里我们有必要对比一下(ROUND 1):
相关滤波:优点 -> 得益于循环矩阵假设和 FFT,计算速度非常快,较大 feature map 也能轻松应对;缺点 -> 循环矩阵假设造成了边界效应,检测范围受限;
交叉相关:优点 -> 没有假设也没有边界效应,是实实在在的滑窗检测,有卷积高效实现速度可以接受;缺点:计算量高,仅适合较小 feature map。
尺度自适应:常用的多尺度检测方法实现尺度自适应,3 个尺度更快 86 fps,5 个尺度更好 58 fps。尺度检测是扩大或缩小检测区域,但检测图像都要缩放到 255*255*3,也就是说尺度检测是天然可以并行的,SiamFC 通过设置 mini-batch 的方式实现,一次性完成 3 或 5 个尺度样本检测,这在 GPU 上方便加速,但对 CPU 或 ARM 就不太友好了,单核速度需要 * 3 或 * 5 考虑。
在线不更新:这里的更新是指目标图像是不是更新,而非 CNN 的权值,CNN 离线训练后就完全固定了,SGD 反向传播在 tracking 问题中基本不可能实时。
最早 16CVPRw 的 SINT 就是在线不更新的,不更新当然速度快,但对特征的要求更高,特征必须对各种干扰和形变都非常鲁棒。SiamFC 的特征来自 AlexNet 的 conv5,属于高层语义特征,也就是说,这一层特征已经知道它要跟踪的是什么了,不会像 HOG 那样苛求纹理相似度。举个例子,如果跟踪目标是人,不论躺着或站着,conv5 都能 “认出来” 这是人,而纹理特征如 HOG 或 conv1 可能完全无法匹配。
(什么是纹理,什么是语义,有无明显的界限?如果有一张 100*100 的苹果图像,1 万个像素 vs. 一个词 “apple”,算两个极端吗?)
在线不更新带来的另一个好处,SiamFC 是目前最优秀的 long-term 跟踪算法。因为目标永远不会被污染,而且检测区域足够大,轻微的偏航都可以随时找回来。对比如下(ROUND 2):
在线更新:优点 -> 随时适应目标的变化,和背景信息的变化,对特征的要求较低,低层特征计算速度快分辨率高;缺点 -> 模型更新会累计误差,遮挡或失败时会学到背景,丢失后再也找不回来。
在线不更新:优点 -> 不更新速度更快,跟踪目标永远不会被污染,long-term 特性非常优秀;缺点 -> 对特征的要求非常高,必须是表达能力足够强足够鲁棒的特征,通常高层特征计算速度慢、分辨率低。
检测区域:目标图像是加了纹理扩展的,类似 Staple 中的 padding=1,而检测区域又是目标图像的 4 倍,这一设置接近 ECO 和 BACF 的检测区域,而且特征图还不用加余弦窗,检测区域算非常大了。
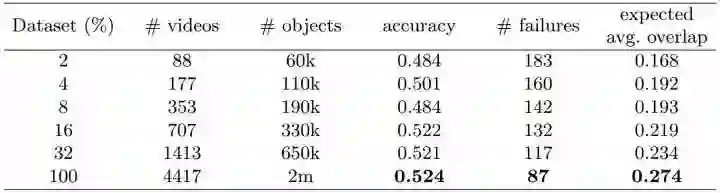
训练样本:SiamFC 是第一个用 2015 ILSVRC Object detection from video task (VID) 训练的,上一篇博文已经分析过用跟踪数据库训练有严重过拟合嫌疑,而且训练数据量有限。VID 有 4417 个视频,超过 2 百万标注帧,非常适合训练跟踪算法,很高兴看到今年很多论文都用这个数据库训练,我们看到的论文结果相对公平。SiamFC 训练数据越多效果越好,能得益于大数据。
下一个要介绍的是 EAST,CMU 做 BACF 的那个组,是 SiamFC 的改进,没有源码:
Huang C, Lucey S, Ramanan D. Learning Policies for Adaptive Tracking with Deep Feature Cascades [C]// ICCV, 2017.
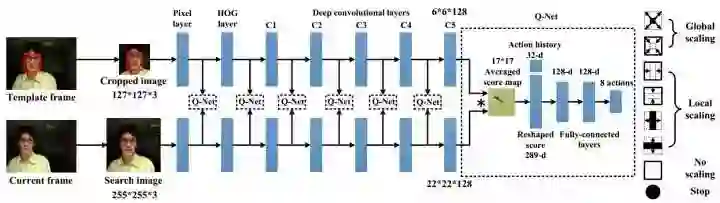
SiamFC 中所有帧都用 conv5 的特征去检测,EAST 的出发点是 (外观相似或不运动的) 简单帧用简单特征如像素边缘就可以定位,(经历较大外观变化的) 复杂帧才需要不变性更强的深度特征进行定位。EArly-Stopping Tracker(EAST) 首先用速度比较快的简单特征检测目标,如果检测置信度比较高就提前终止输出结果,如果置信度低就计算下一阶特征重新检测,仅在简单特征无法判别时才计算深度特征,这样就可以节省计算量。这种特征级联的想法与级联检测非常相似。
特征级联从简单到复杂、从快到慢依次是 pixel - HOG - conv1 - conv2 - conv3 - conv4 - conv5,注意不同特征的空间分辨率不同。相似度计算还是 SiamFC 的 cross-correlation,前面分析过分辨率太大时 cross-correlation 会非常慢,所以 EAST 将所有特征的空间分辨率都下采样到 17*17,以保证速度,其他部分与 SiamFC 完全一样。每个级联特征都用 decision policy 判断是否提前终止,这个 decision policy 用 RL 离线训练。
EAST 是第一个 CPU 友好的深度跟踪算法,平均速度 23.2 fps 接近实时,其中 50% 的时间速度是 190 fps,说明跟踪序列中简单帧占比较高,这些帧用 pixel 或 HOG 就可以搞定,类似 CSK 和 KCF。反过来说,那些需要深度特征如 conv5 判定的复杂帧速度非常慢,也说明帧率波动会比较大。
接下来依然是牛津 Luca Bertinetto 这个组,CFNet 也是 SiamFC 的改进工作:
Valmadre J, Bertinetto L, Henriques J F, et al. End-to-end representation learning for Correlation Filter based tracking [C]// CVPR, 2017.
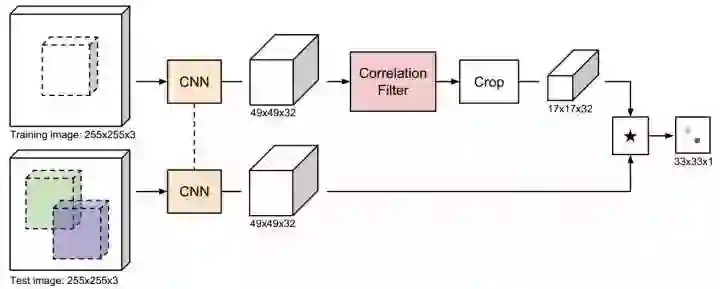
CFNet 的主要内容是推导了 Correlation Filter 的可微闭合解,让 CF 成为 CNN 中的一个层,这样 CNN-CF 就可以 end2end training,训练更适合 CF tracking 的卷积特征。
核心 CNN 的改动:还是 SiamFC 中用的那个调整后的 BN-AlexNet,整个网络的 stride 从 8 降低到 4,CF 适合较大的 feature map;限制输出层的通过道数为 32,表达能力足够的情况下速度更快。总结来说就是 feature map 的分辨率增加,但通道数下降。
CFNet 与 DCF 中 CF 的区别:在 DCF 中,相关滤波器构建和更新,新一帧目标检测,两个核心步骤都在频域完成;CFNet 中的 Correlation Filter layer,只负责相关滤波器的构建和更新,目标检测这一步还是采用 SiamFC 中的 cross-correlation 在空域卷积实现。
边界效应:下路检测图像与 SiamFC 类似,上路目标图像也是目标区域的 4 倍,输入由 127 扩大到 255,经 CNN 计算 feature map 49*49*32,加余弦窗,然后经 Correlation Filter 得到滤波器模板,注意滤波器计算完成后会返回空域,随后 crop 模板到 17*17*32,类似 BACF 的方法减少边界效果。最后是 cross-correlation,17*17*32*1 的滤波器对检测图像 feature map 49*49*32 卷积,(49-17)/1+1=33,滑窗检测得到 33*33*1 的 score map。其他流程与 SiamFC 一致。
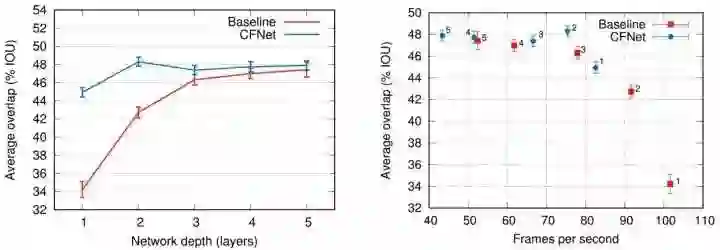
CFNet 在 conv2 效果最好,太深的 CNN 反而会变差,这是与 SiamFC 最大的不同点;CNN 特征越浅,当然速度越快,conv2 有 75 fps;性能轻微超过 SiamFC-3s,但 2 层 CNN 的参数只有 5 层 CNN 的 4%,仅 600kB 模型非常小。
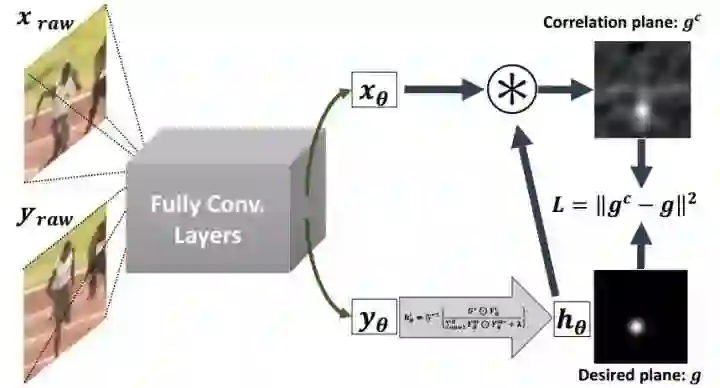
几乎是同一时间,类似的想法 end2end 训练 CNN-CF,DCFNet:foolwood/DCFNet(http://t.cn/R9Un0DA )
Wang Q, Gao J, Xing J, et al. DCFNet: Discriminant Correlation Filters Network for Visual Tracking [C]// ICIP, 2017.

DCFNet 同样将 DCF 作为 CNN 中的一层,实验同样也证明浅层的 CNN 比较好,不过出发点略有区别(ROUND 3):
CFNet:出发点 -> 用 CF 构建 SiamFC 中滤波器的模板;优点 -> crop 减轻了边界效应,cross-correlation 理论上可以检测任意范围的目标,没有限制;缺点 -> cross-correlation 计算量大速度慢,尤其是前面 CF 需要的 feature map 比较大。
DCFNet:出发点 -> 用 CNN 代替 DCF 中的 HOG 特征;优点 -> 除了 CNN 其他部分仍在频域快速解决,速度更快,特征分辨率比 CFNet 高近 3 倍,定位精度高;缺点 -> 边界效应限制了检测区域。
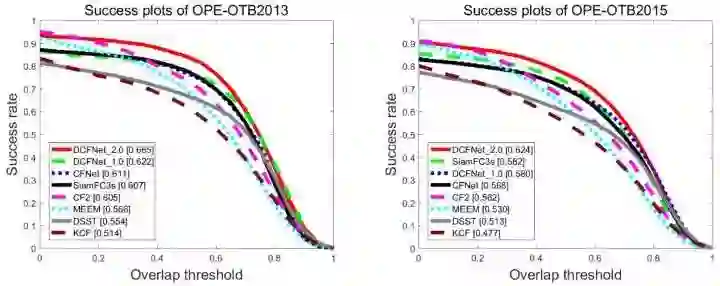
最新版 DCFNet 2.0 改用 VID 训练后,性能有了大幅飞跃,已经超过了 CFNet,而且速度更快 GPU 100 fps。
除了 DCFNet 与 CFNet 撞车,同一时间还有 CFCF egundogdu/CFCF(http://t.cn/RHFqmn5 )
CFCF 是 VOT2017 的冠军,同样也构造了可以 end2end training 的 CNN,同样用 VID 训练,不过 CFCF 的目的是通过 end2end training 去 fine-tune VGG-M,之后 C-COT 用这个 fine-tune 的 CNN 提取卷积特征,其他部分与 C-COT 完全一样,这个不能 real-time。
第三部分:总结比较
从 VOT2017 提交结果中有 SiamFC 但没有 CFNet,可以看出 SiamFC 比 CFNet 更优秀应该是没有疑问的,虽然速度慢一点,但真的很强。其实您也应看出来了,核心区别就在 Cross-correlation 和 Correlation Filter,一个通过 Conv 实现,一个通过 FFT 实现,最后总结对比(FINAL ROUND):
Cross-correlation:适合特征分辨率较小的高层 CNN,典型 AlexNet 的 conv5,CNN 特征提取部分更大更慢,滑窗检测计算量较大但没有边界效应,检测范围不受限,目标模型在线不更新,定位精度较低但更鲁棒。
Correlation Filter:适合特征分辨率较大的低层 CNN,典型 AlexNet 的 conv2,CNN 特征提取部分更小更快,模板更新和检测都可以在频域高效解决,CF 速度快,但边界效应难以处理,目标模型在线更新,定位精度更高但容易被污染。
VOT2017 中的 SiamDCF 是 SiamFC 和 DCFNet 的结合,优势互助,劣势互补,内测和速度测试表现都很不错:

回到最初的问题,GPU 上实时的 tracker 在 CPU 上能实时吗?
SiamFC 肯定是不行,3 个尺度 AlexNet 就要跑三次,难度太大,放弃。
速度最快的 DCFNet 看起来有点潜力,用 2 层 CNN 代替 HOG,只要控制通道数,conv2 的计算量可以接受。
有了以前把 DCF 在 ARM 上落地的经验,保持那个框架不变,仅仅将 HOG 用 CNN 代替,同时将 CNN 容量稍微调小,在单核 CPU 上可以轻松跑到上百 fps,完全有潜力在 ARM 上落地。不过我用的 2 层 CNN 是在 ImageNet-1k 上预训练的,并没有在 VID 上 end2end fine-tune,所以性能不如 HOG,只是用来测试速度的。
如果您也想把 SiamFC 或 DCFNet 放在 CPU 甚至 ARM 上跑,需要注意两点:
控制 CNN 容量:CNN 速度必须要快,几个尺度检测,这个 CNN 每帧就要跑几次,是计算量大头。
优化较好的 CNN inference framework:CNN 的核心计算量在 Conv layer,这里需要细致优化,保证 CNN 速度。
CNN tracking 方面我是新手,以上论文也不是我关注的重点,没有自己亲手实现过,细节上难免有错误,不吝指出,谢谢!
延伸阅读

上海交通大学博士讲师团队
从算法到实战应用
涵盖 CV 领域主要知识点
手把手项目演示
全程提供代码
深度剖析 CV 研究体系
轻松实战深度学习应用领域!
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
深度学习目标检测概览
▼▼▼




